







一、摘要
不同于模式匹配的知识获取,Watson中可以在非结构化文本中通过简单的语义分析来自动获取知识,甚至是以前不存在于知识库中的类型。知识获取分两步——第一,抽取浅层知识,第二,统计推理语义。这套方法的名字叫——PRISMATIC。
二、相关术语
在PRISMATIC中使用以下术语:
- 帧(Frame)——一个帧是一个基本的语义片段,是一段文本中一系列的实体和他们之间的关系;
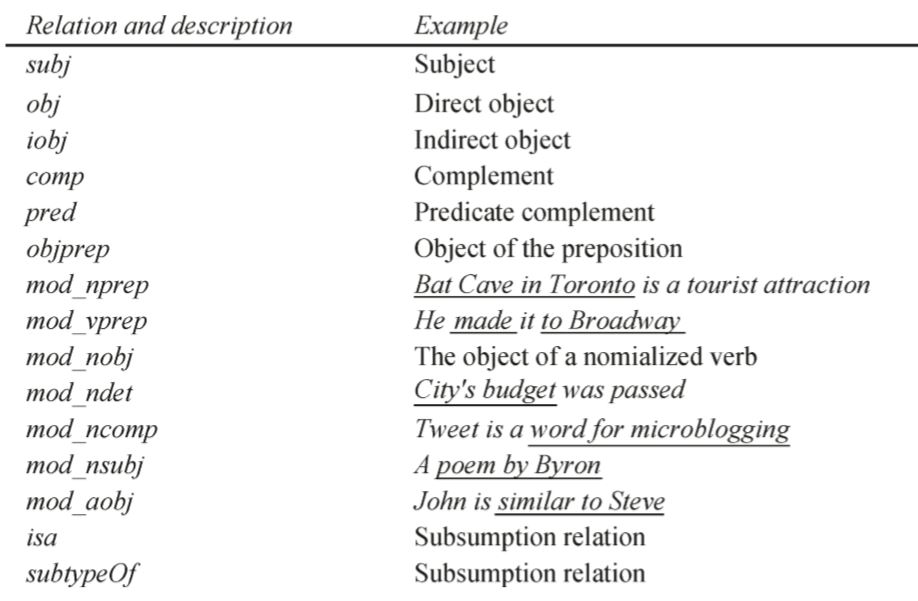
- 槽(Slot) ——一个槽就是一个二元关系,在PRISMATIC中就是两者之间的依赖关系,常用的见下表:
- 槽值(Slot value)——槽值要么是一个术语要么是一个呗NER标注的类型,下方的表格展示了标记出来的槽和对应的值,分析树为下图的分析树:

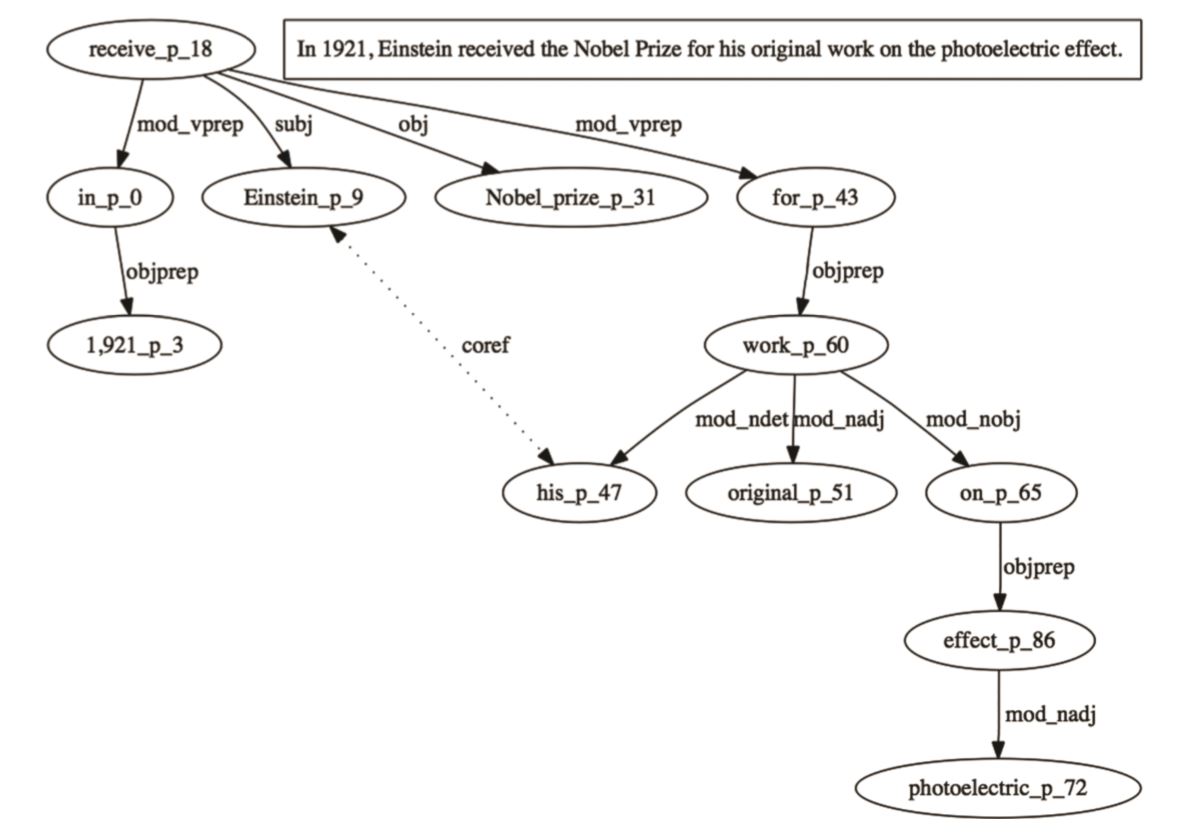
-帧映射(Frame projection)——帧映射就是一系列有规律地在帧中出现的一部分。(笔者说,这个名字有点奇怪啊,当然如果是我理解有问题,欢迎指出)。
PRISMATIC的正式定义如下:
一个PRISMATIC P 就是多个帧的集合,即
P={f1,f2,...,fn}
,其中
fi={⟨s1,v1⟩,⟨s2,v2⟩,...,⟨sm,vm⟩}
。
上式中
⟨sm,vm⟩
即代表一个槽、值对,
V(s,f)
则指帧f中的槽s的值。
由此定义帧映射
C⊆P
即,
三、系统概述
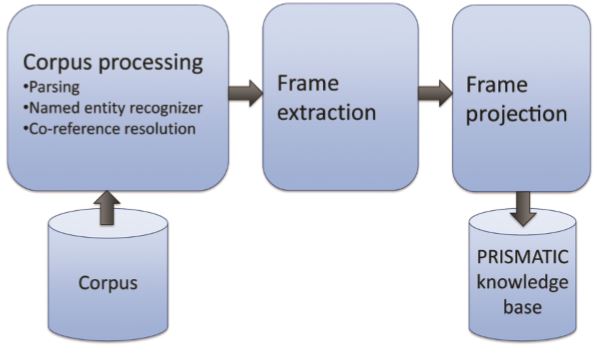
PRISMATIC的生成用到了多个NLP工具,包括依赖分析、基于规则的命名实体识别以及在Deep Parsing那边博文中讲到的一致性解决组件。PRISMATIC的创建过程概括为如下三步:
- 语料库处理——这一步使用上面提到的NLP方法来标记语料库;
- 帧抽取——将于标记相关的帧抽取出来;
- 帧映射——在全部帧中抽取出需要的那部分,并且制表统计频率信息,以此来推理语义信息。
下图展示了PRISMATIC创建的大致流程:
语料库处理
语料库处理最关键的步骤就是依赖分析,在上一篇博文中对Deep Parsing中使用的ESG已有介绍,这里就不在复述了。分析树会产生很多实体间的“公理”(原词是axiom,这里的使用也有些不好翻译),为了能够与描述中的“公理”对齐,又使用了一个机遇规则的命名实体识别器,重点是实体的类型信息,因为在帧抽取阶段还需要这部分信息。
帧抽取
帧抽取是为了获得一个能够表示浅层知识的大量帧组成的集合。为了能够捕捉到感兴趣的关系,帧的元素被限制在那些能够表示谓词的宾语信息中。另外,每个帧的深度被限制在2层,一个大的分析树可能产生多个帧。后面将会将会降到的关系抽取的那部分还会将一部分语义信息添加到分析树之中。
帧映射
帧映射其实是想在数据中发现、归纳一些有意思的知识模式,比如说,定义了一种N-P-OT的映射操作,对于 {⟨noun,"annexation"⟩,⟨preposition,"of"⟩,⟨object−type,"Region"⟩} 这种就会总结出来,annexed的宾语通常是一种region。而且,这样一来我们就能提前计算和查找下面的“聚合统计”。
四、聚合统计
许多有用的聚合统计都可以通过帧映射结果获得,这里只简单介绍一下三个栗子:
- 频率——特定帧的频率可以被定义为 #(f)=|{fi∈P|∀s∈SV(s,f)}| 。
- 条件概率——一个特定帧的条件概率可以通过 p(f|f′)=[#(f)/#(f′)] ,其中 f′⊆f
- 归一化逐点共同信息——想放出来英文原文,Normalized Pointwise Mutual Information,计算公式为 npmi(f,f′)=pmi(f,f′)−ln(max|#(f),#(f′))N , 其中 pmi(f,f′)=lnN(#(f∪f′)/#(f)×#(f′)) (N是指定帧映射的大小)
后记今天这篇博文有两个主要特点:第一,大家期待已久的公式来了;第二,必须得用MarkDown编辑器写了,因为数学公式的输入得用 LATEX 方式才爽。















 6097
6097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









