







上篇文章介绍了线性回归,但是一般线性回归模型在处理复杂的数据的回归问题时会遇到一些问题,主要表现在:
- 1.预测精度:要处理好样本的数量n和特征的数量p之间的关系。
当n>>p时,最小二乘回归会有较小的方差;
当 n≈p 时,容易产生过拟合;
当n< p时,最小二乘回归得不到有意义的结果。 - 2.模型的解释能力:如果模型中的特征之间有相互关系,这样会增加模型的复杂程度,并且对整个模型的解释能力并没有提高,这时,我们就要进行特征选择。
以上的这些问题,主要就是表现在模型的方差和偏差问题上,这样的关系可以通过下图说明:
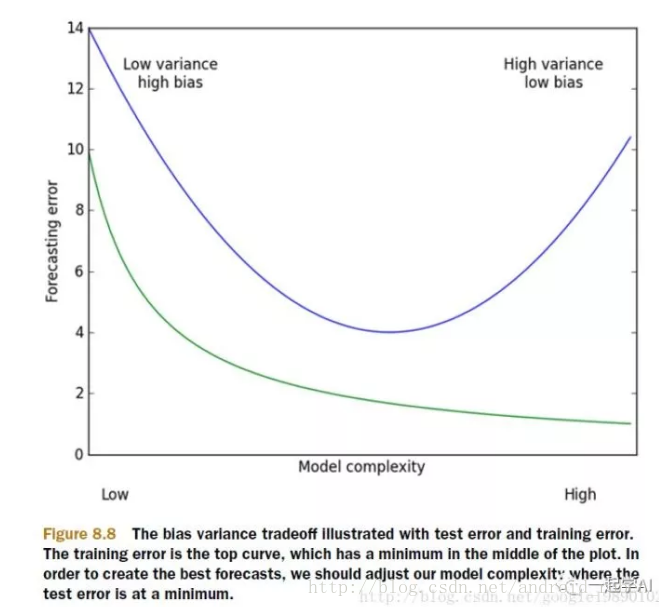
方差指的是模型之间的差异,而偏差指的是模型预测值和数据之间的差异。我们需要找到方差和偏差的折中。这就引入了岭回归。
在进行特征选择时,一般有三种方式:
- 子集选择
- 收缩方式(Shrinkage method),又称为正则化(Regularization)。主要包括岭回归和lasso回归。
- 维数缩减
岭回归(Ridge Regression)是在平方误差的基础上增加正则项
∑ni=1(yi−∑pj=0wjxij)2+λ∑pj=0w2j,λ>0
通过确定\lambda的值可以使得在方差和偏差之间达到平衡:随着\lambda的增大,模型方差减小而偏差增大。
对w求导,结果为: 2XT(Y−XW)−2λW
令其为0,可求得w的值: w^=(XTX+λI)−1XTY
实验:
我们去探讨一下取不同的\lambda对整个模型的影响。
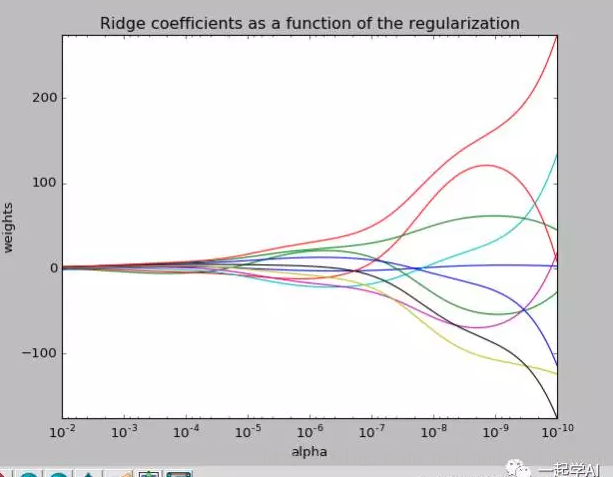
从上图我们可以看到偏差的权重对模型的影响很大,但是都将会在某一个范围趋同。
最后附上实验的代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model
# X is the 10x10 Hilbert matrix
X = 1. / (np.arange(1, 11) + np.arange(0, 10)[:, np.newaxis])
y = np.ones(10)
# Compute paths
n_alphas = 200
alphas = np.logspace(-10, -2, n_alphas)
coefs = []
for a in alphas:
ridge = linear_model.Ridge(alpha=a, fit_intercept=False)
ridge.fit(X, y)
coefs.append(ridge.coef_)
# Display results
ax = plt.gca()
ax.plot(alphas, coefs)
ax.set_xscale('log')
ax.set_xlim(ax.get_xlim()[::-1]) # reverse axis
plt.xlabel('alpha')
plt.ylabel('weights')
plt.title('Ridge coefficients as a function of the regularization')
plt.axis('tight')
plt.show()














 665
665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









