







http://antkillerfarm.github.io/
高斯判别分析(续)
将上面三个分布的概率密度函数代入第二节公式7,可求得 argmaxyp(y|x) ,然后进行最大似然估计,可得该GDA的最大似然估计参数为:(过程略)
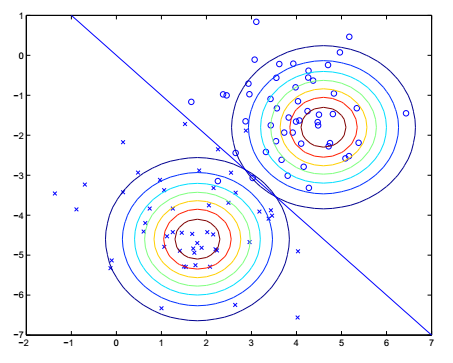
上图中的直线就是分界线
GDA vs 逻辑回归
从上面的变换可以看出,GDA是逻辑回归的特例。
一般来说,GDA的条件比逻辑回归严格。因此,如果模型符合GDA的话,采用GDA方法,收敛速度(指所需训练集的数量)比较快。
而逻辑回归的鲁棒性较好,对于非GDA模型或者模型不够准确的情况,仍能收敛。
互不相容事件、独立事件与条件独立事件
如果 P(AB)=0 ,则事件A、B为互不相容事件。
如果 P(AB)=P(A)P(B)或P(A)=P(A|B) ,则事件A、B为独立事件。
如果 P(AB|R)=P(A|R)P(B|R) ,则事件A、B为条件R下的独立事件。
可见,这三者是完全不同的数学概念,不要搞混了。
朴素贝叶斯方法
这里以文本分析(Text Classification)为例,讲解一下朴素贝叶斯(Naive Bayes)方法。
文本分析的一个常用方法是根据词典建立特征向量x。x中的每个元素代表词典里的一个单词,如果该单词在文本中出现,则对应的元素值为1,否则为0。
这里假设我们的目标是通过文本分析,判别一个email是否是垃圾邮件。 y=1 表示是垃圾邮件, y=0 表示不是垃圾邮件。显然,在这里一封邮件就是一个样本集。
相比之前的应用领域,文本分析的特殊之处在于词典中的单词数量十分庞大,从而导致x的维数巨大(比如50000个单词,就是50000维),以至于之前的方法,根本无法计算。
为了简化问题,我们假设 p(xi|y) 是条件独立的。这个假设被称为朴素贝叶斯假设(Naive Bayes (NB) assumption)。使用这个假设的算法被称为朴素贝叶斯分类器(Naive Bayes classifier)。
从数学角度,NB假设是个很严格的条件,但是实际使用中,即使样本集不满足NB假设,使用NB方法的效果一般还是不错的。
因此:
最大似然估计值为:
NB算法还可以扩展到y有多个取值的情况。对于y为连续函数的情况,可以采用区间离散化操作,将之离散化为多个离散值。
拉普拉斯平滑
对于样本集中未出现的单词,在其首次出现时,由于先验概率 p(xi|y=1)=0,p(xi|y=0)=0 ,这时公式1会出现 00 的情况。
为了避免这种情况,我们假定先验概率至少为1次,也就是
这种方法叫做拉普拉斯平滑(Laplace Smoothing)。注意这里 ϕ 的定义和上面略有不同,上面的公式中,y是二值分布,而这里是多值分布(值为k)。为了满足概率和为1的条件,分母上需要加k。
文本分类的事件模型
文本分类的事件模型有两类:
1.多值伯努利事件模型(multi-variate Bernoulli event model)。
在这个模型中,我们首先随机选定了邮件的类型(垃圾或者普通邮件,也就是 p(y) ),然后翻阅词典,随机决定一个词是否要在邮件中出现,出现则 xi 标示为1,否则标示为0。然后将出现的词,组成一封邮件。一个词是否出现的概率为 p(xi|y) ,整封邮件的概率为 p(y)∏ni=1p(xi|y) 。
2.多项事件模型(multinomial event model)。
令 xi 表示邮件的第i个词在字典中的位置,那么 xi 的取值范围为 1,2,...∣V∣ , ∣V∣ 表示字典中单词的数目。这样一封邮件可以表示成 (x1,x2,…,xn) ,这里n为邮件包含的单词个数,显然每个邮件的n值一般是不同的。
这相当于重复投掷 ∣V∣ 面的骰子,将观察值记录下来就形成了一封邮件。每个面的概率服从 p(xi|y) ,而且每次试验条件独立。这样我们得到的邮件概率是 p(y)∏ni=1p(xi|y) 。
需要注意的是,上面两个事件模型的概率公式虽然一致,但含义却有很大差异,不要弄混了。
支持向量机
支持向量机(SVM,Support Vector Machines)是目前最好的监督学习算法。它由Vladimir Naumovich Vapnik与Alexey Ya. Chervonenkis于1963年提出。
注:Vladimir Naumovich Vapnik,1936年生,乌兹别克国立大学学士,莫斯科控制科学学院博士,后成为该学院计算机科学研究部门负责人。1990年代末移民美国,先后供职于AT&T Bell、NEC、Facebook,伦敦大学和哥伦比亚大学教授。
Alexey Yakovlevich Chervonenkis,1938~2014,俄罗斯数学家。俄罗斯科学院院士,伦敦大学教授。
我们首先来看一幅图:
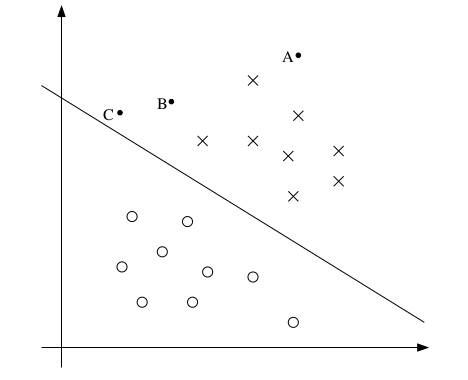
上图中的x和o分别代表y的两种不同取值(1和0)。前面提到逻辑回归的预测函数为 hθ(x)=g(θTx) ,那么图中直线的解析方程就是 θTx=0 。这条直线被称作分割超平面(Separating Hyperplane),也就是预测值的分界线。
图中的三个点A、B、C,虽然都在线的上方,然而从直觉来说,A离分界线最远,我们对它的值为1的信心也最足。反观C点,由于离分界线比较近,我们对其值的预测,实际上并没有多大把握。因为这种情况下,样本集的少许调整,就会导致分界线的移动,从而导致预测值的改变。B点的情况介于A和C之间。
和逻辑回归不同,SVM更关心靠近分界线的点,让他们尽可能地远离分界线,而不是在所有点上都达到最优。
为了便于后续讨论,我们对 hθ(x) 进行改写: hw,b(x)=g(wTx+b) 。其中b为常数项,即 x0 的系数项,w为其余的 xi 的系数项。
同时对 g(z) 的定义也调整为:
这个定义的好处在于 g(z) 的取值,只和z的符号相关,而和其绝对值的大小无关。
函数边距和几何边距
为了定义样本点和边界线的距离,我们引入函数边距(functional margin)和几何边距(geometric margins)的定义。
函数边距的定义如下:
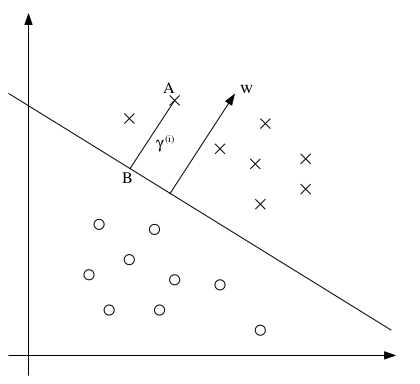
几何边距的几何意义如上图所示。w是分界线的法向量,A的坐标是 x(i) ,它到分界线的距离是 γ(i) ,根据解析几何知识可知,A到分界线的垂足B的坐标为 x(i)−γ(i)w∥w∥ 。将其代入分界线方程 wTx+b=0 ,可得:
正是A在边界线上方时的情况,扩展到整个坐标系的话,上式可改为:
同理,可得几何边距的定义为:
从函数边距和几何边距的定义可以看出,如果等比例缩放w和b的话,其几何边距不变,且当 ∥w∥=1 时,函数边距和几何边距相等。
最优边距分类
SVM算法的本质,就是求能使几何边距最大的w和b的取值,用数学语言描述就是求解问题:
注:上式中的 s.t. 是subject to的缩写,表示极值问题的约束条件。
这个问题等价于:
如果能通过比例变换使 γ^=1 ,则问题化解为:
这个问题实际上就是数学上的QP(Quadratic Programming)问题,采用这种方案的分类被称为最优边距分类(optimal margin classifier)。
拉格朗日对偶
QP问题是有约束条件的优化问题(constrained optimization problem)的一种,下面让我们讨论一下解决这类问题的通用方法。
假设我们求解如下问题:
这里将约束条件分为两类:
1. hi(w)=0 代表的是约束条件为等式的情况。
2. gi(w)≤0 代表的是约束条件为不等式的情况。
上述约束优化问题也被称为原始优化问题(primal optimization problem)。为了求解这个问题,我们定义广义拉格朗日(generalized Lagrangian)函数:
利用这个函数可以将约束优化问题转化为无约束优化问题。其中的 αi 、 βi 也被称作拉格朗日乘子(Lagrange multiplier)。
其中, P 代表原始优化问题, maxα,β:αi≥0 表示在 α,β 变化,而其他变量不变的情况下,求最大值。















 2022
2022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









