









1,信息论
在引入决策树的概念之前,先了解一下信息论。
考虑一个离散的随机变量x,当我们观察到这个变量的具体值得时候,我们接受到多少信息呢?信息量可以被看成在学习x的值得时候的“惊讶程度”。如果有人告诉我们一个相当不可能的事件发生了,我们接受到的信息要多于我们被告知某个很可能发生的事件发生时得到的信息。因此,事件发生的概率越大,信息量越小。同时,我们观察到,对于两个不相关事件,同时发生时获得的信息量等于各自发生的信息量之和。设事件的概率为p(x),信息为h(x).
故,我们有:
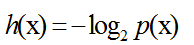
平均信息量为:
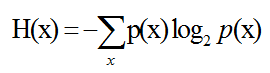
2,决策树
决策树是附加概率结果的一个树状的决策图,是直观的运用统计概率分析的图法。机器学习中决策树是一个预测模型,它表示对象属性和对象值之间的一种映射,树中的每一个节点表示对象属性的判断条件,其分支表示符合节点条件的对象。树的叶子节点表示对象所属的预测结果。
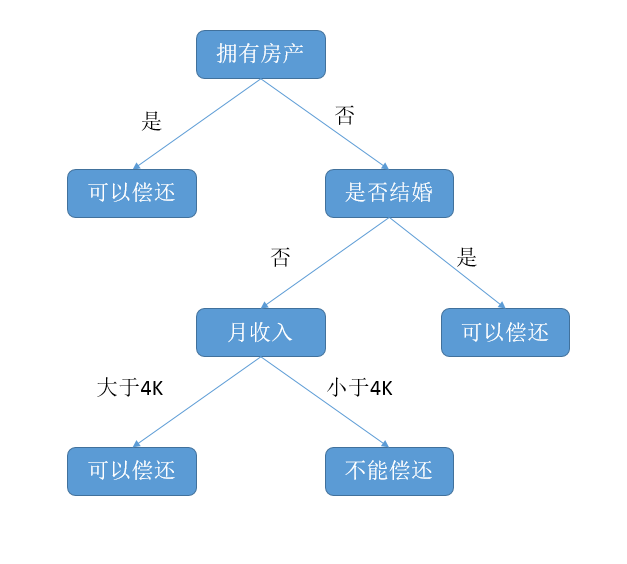
通过选择合适的属性来作为决策树的节点,选择的算法,在这里用ID3算法。
3,ID3算法
查看本博客的另一篇文章:
http://blog.csdn.net/chaoshengmingyue/article/details/50937291
4,具体实现:
(1)计算信息熵
数据的格式:
dataSet = [[1,1,'yes'],
[1,1,'yes'],
[1,0,'no'],
[0,1,'no'],
[0,1,'no']]
labels = ['n', 'flp']按上述的数据格式计算信息熵
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts={}
#先将最后一位不同类的个数统计后放在一个字典中
for featVec in dataSet:
currentLabel = featVec[-1]#得到数据集的最后一个元素
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -=prob*log(prob,2)
return shannonEnt(2)划分数据集
函数的参数
1,第一个参数是数据集
2,第二个是要根据哪一个特征进行划分,如axis=0时,表示根据第一个特征进行划分
3,第三个参数是特征的返回值,即假设使用上述的数据集,axis=0,value=1时,则函数返回的值是,划分后第一个特征值为1的数据。
如:

def splitDataSet(dataSet, axis, value):
retDataSet = []
for featvec in dataSet:
if featvec[axis] == value:
reducedFeatVec = featvec[:axis]
reducedFeatVec.extend(featvec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet(3)将上述代码结合起来,选择最好的分割特征,进行分割。
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0])-1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
#将数据集的第i个特征的所有可能值存放在一个list中
featList = [example[i] for example in dataSet]
#由于set集合要求,元素之间不相同,故这一行用来去除相同的元素,得到第i个特征的所有取值
uniqueVals = set(featList)
newEntropy = 0.0
#计算每种划分的熵,并计算他们的加权平均
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob*calcShannonEnt(subDataSet)
#计算信息增益
infoGain = baseEntropy - newEntropy
if(infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature(4),递归构建决策树
首先,考虑一个问题,当划分特征到最后一个任然无法完全将数据分开怎么办?
这里,我们这么做,计算在最后无法分开的数据集中,各个类别所占的比例,比例最高的即为当前数据集的类别。
因此,要建立一个这样的函数,来进行上述的操作。
(其中函数sorted的用法参看:http://blog.csdn.net/chaoshengmingyue/article/details/50914863中的解释)
def majorityCnt(classList):
classCount = {}
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCOunt.iteritems(), key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]创建树:
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet]
#表明在分组中只有一种类别,故已经将数据分开了
if classList.count(classList[0]) == len(classList):
return classList[0]
#表明特征已经划分完了,此时数据还没分开
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatureLabel = labels[bestFeat]
myTree = {bestFeatureLabel:{}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatureLabel][value] = createTree(splitDataSet(dataSet,bestFeat,value),subLabels)
return myTree输出结果:
{‘n’: {0: ‘no’, 1: {‘flp’: {0: ‘no’, 1: ‘yes’}}}}
(5),用决策树进行分类
testVec=[1,1],判断是yes还是no
def classify(inputTree, featLabels, testVec):
firstStr = inputTree.keys()[0]
secondDict = inputTree[firstStr]
#计算用来分割数据的特征在实际数据中是位于第几个特征
featIndex = featLabels.index(firstStr)
for key in secondDict.keys():
if testVec[featIndex] == key:
if type(secondDict[key].__name__ == 'dict'):
classLabel = classify(secondDict[key], featLabels, testVec)
else:
classLabel = secondDict[key]
return classLabel最后返回yes。
(6),可以将求出的决策树保存在本地,不用每次都计算。
#保存
def storeTree(inputTree, filename):
import pickle
fw = open(filename,'w')
pickle.dump(inputTree, fw)
fw.close()
#读取
def grabTree(filename):
import pickle
fr = open(filename)
return pickle.load(fr)














 789
789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









