







 本文介绍了感知机学习算法(PLA),它是一种用于分类的简单机器学习算法。通过初始化直线并不断迭代更新,PLA寻找最佳分类边界。文章详细阐述了PLA的原理,更新步骤,并提供了Python实现代码,包括数据预处理、训练过程及预测。最终,文章附带了一个示例数据集以辅助理解。
本文介绍了感知机学习算法(PLA),它是一种用于分类的简单机器学习算法。通过初始化直线并不断迭代更新,PLA寻找最佳分类边界。文章详细阐述了PLA的原理,更新步骤,并提供了Python实现代码,包括数据预处理、训练过程及预测。最终,文章附带了一个示例数据集以辅助理解。
一、概论
对于给定的n维(两种类型)数据(训练集),找出一个n-1维的面,能够“尽可能”地按照数据类型分开。通过这个面,我们可以通过这个面对测试数据进行预测。
例如对于二维数据,要找一条直线,把这些数据按照不同类型分开。我们要通过PLA算法,找到这条直线,然后通过判断预测数据与这条直线的位置关系,划分测试数据类型。如下图:
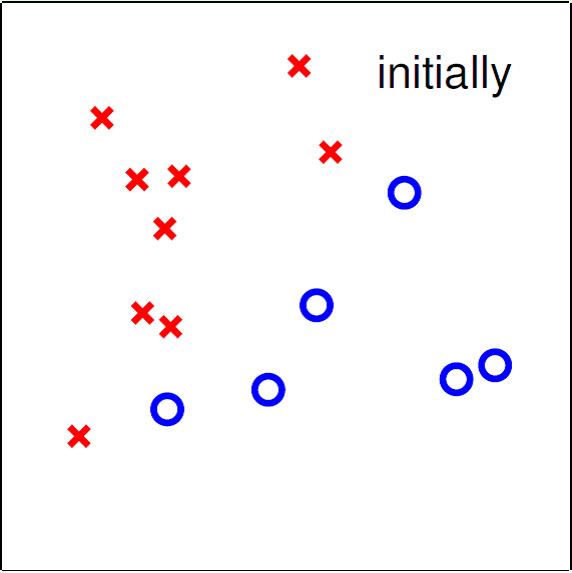
二、PLA的原理
先初始化一条直线,然后通过多次迭代,修改这条直线,通过多次迭代,这条直线会收敛于接近最佳分类直线。
修改直线的标准是,任意找出一个点(训练数据中的某个点),判断这个点按照这条直线的划分类型是否跟该点实际类型是否相同。如果相同则开始下次迭代;如果判断错误,则更新直线的参数。
三、W的更新步骤
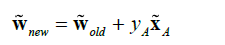
期中W为直线的参数矩阵。y为该点的实际类型,x为该点的参数矩阵。
假设有一下测试数据:
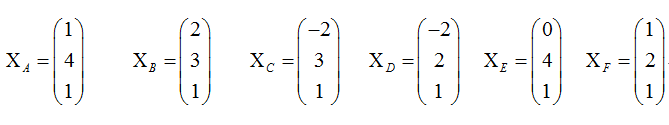
第1、2个位向量参数,第三个为截距值。
这几个测试数据集的类型表现为:
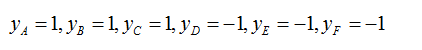
求出以下的测试集的类型:
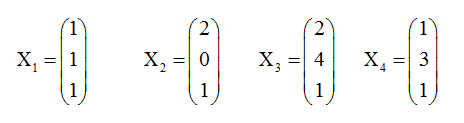
假设W的初始化值为: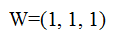
第一次选择E点来更新W的值:
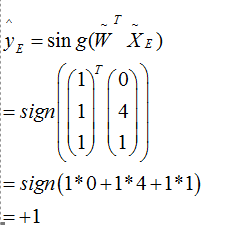
其中sign的符号函数,sign(x)当x的值大于0是sign(x)=+1,否则为-1。(这里+1,-1分别表示两种标签类型)
如上面公式求出来的结果是+1类型,而真实值为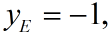
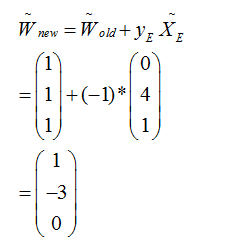
四、python实现
1、初始化W的值和迭代次数:
ITERATION = 70;
W = [1, 1, 1];2、读取训练、测试数据,生成训练、测试(二维)列表:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5052
5052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









