







 本文详细介绍了决策树算法中如何划分数据集和计算信息增益,旨在通过实例解析如何找到最佳特征来划分数据,从而实现更好的分类效果。内容包括基本概念、具体操作,并提供了Python代码示例。
本文详细介绍了决策树算法中如何划分数据集和计算信息增益,旨在通过实例解析如何找到最佳特征来划分数据,从而实现更好的分类效果。内容包括基本概念、具体操作,并提供了Python代码示例。
写在前面的话
可怜了我这个系列的博客,写的这么好,花了很多心思去写的,却没有人知道欣赏。就像我这么好也没有人懂得欣赏,哈哈哈,我好不要脸。。。
如果您有任何地方看不懂的,那一定是我写的不好,请您告诉我,我会争取写的更加简单易懂!
如果您有任何地方看着不爽,请您尽情的喷,使劲的喷,不要命的喷,您的槽点就是帮助我要进步的地方!
1.划分数据集
1.1 基本概念
在度量数据集的无序程度的时候,分类算法除了需要测量信息熵,还需要划分数据集,度量花费数据集的熵,以便判断当前是否正确的划分了数据集。
我们将对每个特征数据集划分的结果计算一次信息熵,然后判断按照那个特征划分数据集是最好的划分方式。
也就是说,我们依次选取我们数据集当中的所有特征作为我们划定的特征,然后计算选取该特征时的信息增益,当信息增益最大时我们就选取对应信息增益最大的特征作为我们分类的最佳特征。
下面是我们的数据集:

我们用python语言表示出这个数据集
dataSet= [[1, 1, ‘yes’], [1, 1, ‘yes’], [1, 0, ‘no’], [0, 1, ‘no’], [0, 1, ‘no’]]
在这个数据集当中有两个特征,就是每个样本的第一列和第二列,最后一列是它们所属的分类。
我们划分数据集是为了计算根据那个特征我们可以得到最大的信息增益,那么根据这个特征来划分数据就是最好的分类方法。
因此我们需要遍历每一个特征,然后计算按照这种划分方式得出的信息增益。信息增益是指数据集在划分数据前后信息的变化量。
1.2 具体操作
划分数据集的方式我们首先选取第一个特征的第一个可能取值来筛选信息。然后再选取第一个特征的第二个可能的取值来划分我们的信息。之后我们再选取第二个特征的第一个可能的取值来划分数据集,以此类推。
e.g:
[[1, 1, ‘yes’], [1, 1, ‘yes’], [1, 0, ‘no’], [0, 1, ‘no’], [0, 1, ‘no’]]
这个是我们的数据集。
如果我们选取第一个特征值也就是需不需要浮到水面上才能生存来划分我们的数据,这里生物有两种可能,1就是需要,0就是不需要。那么第一个特征的取值就是两种。
如果我们按照第一个特征的第一个可能的取值来划分数据也就是当所有的样本的第一列取1的时候满足的样本,那就是如下三个:
[1, 1, ‘yes’], [1, 1, ‘yes’], [1, 0, ‘no’]
可以理解为这个特征为一条分界线,我们选取完这个特征之后这个特征就要从我们数据集中剔除,因为要把他理解为分界线。那么划分好的数据就是:
[[1, ‘yes’], [1, ‘yes’], [0, ‘no’]]
如果我们以第一个特征的第二个取值来划分数据集,也就是当所有样本的第二列取1的时候满足的样本,那么就是
[[1, 1, ‘yes’], [1, 1, ‘yes’], [0, 1, ‘no’], [0, 1, ‘no’]]
那么得到的数据子集就是下面这个样子:
[[1,’yes’],[1,’yes’],[1, ‘no’], [1, ‘no’]]
因此我们可以很容易的来构建出我们的代码:
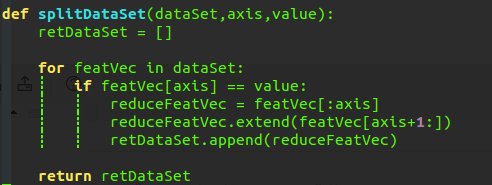
下面我们来分析一下这段代码,
# 代码功能:划分数据集
def splitDataSet(dataSet,axis,value): #传入三个参数第一个参数是我们的数据集,是一个链表形式的数据集;第二个参数是我们的要依据某个特征来划分数据集
retDataSet = [] #由于参数的链表dataSet我们拿到的是它的地址,也就是引用,直接在链表上操作会改变它的数值,所以我们新建一格链表来做操作
for featVec in dataSet:
if featVec[axis] == value: #如果某个特征和我们指定的特征值相等
#除去这个特征然后创建一个子特征
reduceFeatVec = featVec[:axis]
reduceFeatVec.extend(featVec[axis+1:])
#将满足条件的样本并且经过切割后的样本都加入到我们新建立的样本中
retDataSet.append(reduceFeatVec)
return retDataSet总的来说,这段代码的功能就是按照某个特征的取值来划分数据集。
为方便您测试实验我们在贴出这段代码:
def splitDataSet(dataSet,axis,value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reduceFeatVec = featVec[:axis]
reduceFeatVec.extend(featVec[axis+1:])
retDataSet.append(reduceFeatVec)
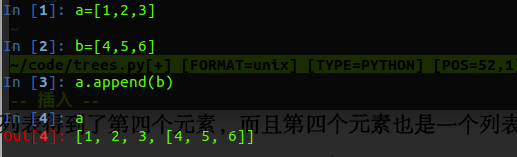
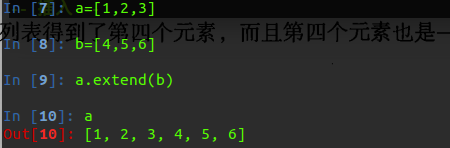
return retDataSet在这里我们可以注意到一个关于链表的操作:
那就是extend 和append
它们的用法和区别如下所示:
下面我们再来测试一下我们的数据:
先给出实验的完整代码
#!/usr/bin/env python
# coding=utf-8
# author: chicho
# running: python trees.py
# filename : trees.py
from math import log
def crea 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 72
72

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









