








相信能看到这篇文章的人,都大致知道什么是决策树(DT)。很多人也知道怎么用DT,但对DT也不一定有直观的感觉,更难以深究其细节。所以本文以Iris数据集为例,一步一步讲解DT的实现过程,并画出一颗DT,让我们能从根本上理解DT及其内部结构。
理解了DT,就更容易理解它的扩展算法Random Forest, GBDT, XGBoost。
Iris数据集
安德森鸢尾花卉数据集,下面给出数据集中的一小部分,这个数据集一共有3种类型,150个样本。
| 编号 | 花萼长度 | 花萼宽度 | 花瓣长度 | 花瓣宽度 | 属种 |
|---|---|---|---|---|---|
| 1 | 5.1 | 3.5 | 1.4 | 0.2 | 0 |
| 2 | 5.0 | 3.3 | 1.4 | 0.2 | 0 |
| 3 | 7.0 | 3.2 | 4.7 | 1.4 | 1 |
| 4 | 6.4 | 3.2 | 4.5 | 1.5 | 1 |
| 5 | 6.3 | 3.3 | 6.0 | 2.5 | 2 |
| 6 | 5.8 | 2.7 | 5.1 | 1.9 | 2 |
为什么选择Iris呢,应为它数据量小啊,便于把问题说清楚。还有就是在python里很容易调用这个数据集,下面几行代码就可以获得Iris数据集了。
from sklearn.datasets import load_iris
iris = load_iris()
print(iris.data)
print(iris.target)划分数据集
构建一颗决策树的核心,在于节点上的判断问题(决策),以及树的形状划分。周志华的书里对于如何选择最优划分属性,有很精辟的描述:
一般而言,随着划分过程不断进行,我们希望决策树的分支节点所包含的样本尽可能属于同一类别,即节点“纯度”(purity)越来越高。
所以数据集的划分,是根据样本集合“纯度”来决定的。我们必须先知道怎么来衡量样本集合“纯度”。这也是所谓决策树的学习算法:
* ID3学习算法:以信息增益为准则来划分属性
* C4.5学习算法:是ID3的改进
* 用信息增益率来选择属性(ID3用信息增益)
* 在树构造过程中进行剪枝
* 能处理非离散数据和不完整数据
信息增益
信息熵
度量样本集合纯度中,我们最常用的指标是信息熵(information entropy)。
信息熵用于衡量样本集合D中,N类样本的纯度。信息熵值越小,说明纯度越高(想象集合中只有一类样本,则Ent(D)=0)。
注意,信息熵的计算,只与样本类别有光,与样本特征无关(在机器学习中,根据Y即可计算)
对于上表给出的6个数据,一共分3类(每类2个样本),则它的信息熵计算过程如下:
对于完整的Iris数据,可用如下代码计算其信息熵:
from sklearn.datasets import load_iris
import math
iris = load_iris()
p0_count = 0
p1_count = 0
p2_count = 0
count = sum(iris.target)
for t in iris.target:
if(t==0):
p0_count += 1
elif(t==1):
p1_count += 1
elif(t==2):
p2_count += 1
p0 = p0_count/count
p1 = p1_count/count
p2 = p2_count/count
ent = -(p0*math.log(p0)/math.log(2) + p1*math.log(p1)/math.log(2) + p2*math.log(p2)/math.log(2))
print(ent)# result = 1.58496250072
信息增益
信息增益,是根据样本的类别进行计算。假定属性a有V个可能的取值,则信息增益计算公式如下:
其中 |D| 表示样本的个数, |Dv| 表示v类样本的个数。
假定我们的数据集就是上表给定的6个样本(选择这6个样本方便详细说明计算过程)。则:
(1) 对于花萼长度属性,一共有6种(V=6)可能得取值。若使用该属性对D进行划分,则可得到6个子集:
D1
(花萼长度=5.1),
D2
(花萼长度=5.0),
D3
(花萼长度=7.0),
D4
(花萼长度=6.4),
D5
(花萼长度=6.3),
D6
(花萼长度=5.8)。每个子集只有1个样本,
|Dv|=1
-
D1
数据集中,数据在3个属种中的概率(
花萼长度为5.1的,属于类别0,1,2的概率)为:p0=1, p1=0, p2=0
- Ent(D1)=−∑3k=1(pklog2pk)=−(1log21+0+0)=0
-
D2
数据集中,数据在3个属种中的概率为:p0=1, p1=0, p2=0
- Ent(D2)=−∑3k=1(pklog2pk)=−(1log21+0+0)=0
-
D3
数据集中,数据在3个属种中的概率为:p0=0, p1=1, p2=0
- Ent(D3)=−∑3k=1(pklog2pk)=−(0+1log21+0)=0
-
D4
数据集中,数据在3个属种中的概率为:p0=0, p1=1, p2=0
- Ent(D4)=−∑3k=1(pklog2pk)=−(0+1log21+0)=0
-
D5
数据集中,数据在3个属种中的概率为:p0=0, p1=0, p2=1
- Ent(D5)=−∑3k=1(pklog2pk)=−(0+0+1log21)==0
-
D6
数据集中,数据在3个属种中的概率为:p0=0, p1=0, p2=1
- Ent(D6)=−∑3k=1(pklog2pk)=−(0+0+1log21)==0
所以, Gain(D,‘花萼长度‘)=Ent(D)−∑Vv=1(|Dv||D|Ent(Dv))=1.585−∑Vv=1(|Dv||D|Ent(Dv))=1.585−(16×0+16×0+16×0+16×0+16×0+16×0)=1.585
(2) 对于花萼宽度属性,一共有4种(V=4)可能得取值。若使用该属性对D进行划分,则可得到4个子集:
D1
(花萼宽度=3.2),
D2
(花萼宽度=3.3),
D3
(花萼宽度=3.5),
D4
(花萼宽度=2.7)。
∣∣D1∣∣=2
,
∣∣D2∣∣=2
,
∣∣D3∣∣=1
,
∣∣D4∣∣=1
。
-
D1
数据集中,数据在3个属种中的概率(
花萼宽度为3.2的,属于类别0,1,2的概率)为:p0=0, p1=2/2, p2=0
- Ent(D1)=−∑3k=1(pklog2pk)=−∑3k=1(pklog2pk)=−(0+1log21+0)=0
-
D2
数据集中,数据在3个属种中的概率(
花萼宽度为3.3的,属于类别0,1,2的概率)为:p0=1/2, p1=0, p2=1/2
- Ent(D1)=−∑3k=1(pklog2pk)=−(12log2(12)+0+12log2(12))=1
-
D3
数据集中,数据在3个属种中的概率为:p0=1/1, p1=0, p2=0
- Ent(D3)=−∑3k=1(pklog2pk)=−(1log21+0+0)=0
-
D4
数据集中,数据在3个属种中的概率为:p0=0, p1=0, p2=1/1
- Ent(D4)=−∑3k=1(pklog2pk)=−(0+0+1log21)=0
所以, Gain(D,‘花萼宽度‘)=Ent(D)−∑Vv=1(|Dv||D|Ent(Dv))=1.585−∑Vv=1(|Dv||D|Ent(Dv))=1.585−(13×0+13×1+16×0+16×0)=1.252
(3) 对于花瓣长度属性,一共有5种(V=5)可能得取值。若使用该属性对D进行划分,则可得到5个子集:
D1
(花瓣长度=1.4),
D2
(花瓣长度=4.7),
D3
(花瓣长度=4.5),
D4
(花瓣长度=6.0),
D5
(花瓣长度=5.1)。
∣∣D1∣∣=2
,
∣∣D2∣∣=1
,
∣∣D3∣∣=1
,
∣∣D4∣∣=1
,
∣∣D5∣∣=1
。
*
Ent(D1)=−(1log21+0+0)=0
*
Ent(D2)=−(0+1log21+0)=0
*
Ent(D3)=−(0+1log21+0)=0
*
Ent(D4)=−(0+0+1log21)=0
*
Ent(D5)=−(0++0+1log21)=0
所以,
Gain(D,‘花瓣长度‘)=1.585
(4) 对于花瓣宽度属性,一共有5种(V=5)可能得取值。若使用该属性对D进行划分,则可得到5个子集:
D1
(花瓣宽度=0.2),
D2
(花瓣宽度=1.4),
D3
(花瓣宽度=1.5),
D4
(花瓣宽度=2.5),
D5
(花瓣宽度=1.9)。
∣∣D1∣∣=2
,
∣∣D2∣∣=1
,
∣∣D3∣∣=1
,
∣∣D4∣∣=1
,
∣∣D5∣∣=1
。
*
Ent(D1)=−(1log21+0+0)=0
*
Ent(D2)=−(0+1log21+0)=0
*
Ent(D3)=−(0+1log21+0)=0
*
Ent(D4)=−(0+0+1log21)=0
*
Ent(D5)=−(0++0+1log21)=0
所以,
Gain(D,‘花瓣宽度‘)=1.585
接下来,如何选择最佳的分类属性呢?
选择信息增益最大的属性作为分类属性
而我们这里,4个属性中,有三个属性的信息增益都相同且共为最大值,选哪一个呢?根据[6],可知选哪个都可以。这里若选择花萼长度,则两层节点的树就能划分完整个数据集。
ID3算法的限制
用信息增益的方法,对本文给出Iris的6个数据集分类,得到的决策树如下
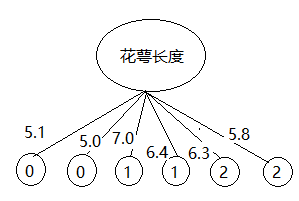
有没有感觉到什么问题?
如果给定的花萼长度是8.8,这棵树就没法分类了!!!
而用sklearn得到的决策树却是这样
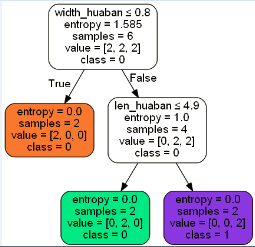
到stackoverflow问了这个问题[7],原来ID3主要是针对非数值特征,sklearn的CART算法才适用于数值特征。
参考
- [1] Iris dataset, https://zh.wikipedia.org/wiki/%E5%AE%89%E5%BE%B7%E6%A3%AE%E9%B8%A2%E5%B0%BE%E8%8A%B1%E5%8D%89%E6%95%B0%E6%8D%AE%E9%9B%86
- [2] scikit-learn decision tree theory, http://scikit-learn.org/stable/modules/tree.html#classification
- [3] scikit-learn decision tree interface, http://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html
- [4] 周志华,《机器学习》
- [5] http://blog.csdn.net/v_july_v/article/details/7577684
- [6] same information gain choosing, http://stats.stackexchange.com/questions/23157/choosing-between-best-two-attributes-with-the-same-information-gain-when-buildin
- [7] decision tree structure, http://stackoverflow.com/questions/38931245/why-the-decision-tree-structure-is-only-binary-tree-for-sklearn-decisiontreeclas
更新
本文将连续值看为离散值进行计算得到的结果。
若给定的数据,是像本文这样的连续值,请参考周志华《机器学习》第四章决策树,4.4.1连续值,进行处理。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









