






Generative Models for Document(文章的生成模型)
这里的Document(文章)是包括两部分:文章的作者集合,组成文章内容的单词集合。例如:
Document 1表示为:

Document 2表示为:
| |

我们将Document d的作者集合表示为![]() ,内容的单词集合表示为
,内容的单词集合表示为![]() 。如
。如 ![]() = {张三,李四} ,
= {张三,李四} ,![]() = { good good study day day up } ;
= { good good study day day up } ;
![]() = {王五,李四} ,
= {王五,李四} , ![]() ={ search knowledge read more books }。
={ search knowledge read more books }。
D 个 Document的集合C就可以表示为:
C = {(![]() ,
,![]() ), (
), (![]() ,
,![]() ), ……,(
), ……,(![]() ,
,![]() )}。
)}。
下面解释什么是Generative Models for Document(文章生成模型)?
在我们的Author Topic Model(作者主题模型)中,每个author都对应一个在topics上的多项分布 ,每个topic都对应一个在word(单词)上的多项分布。如图:

那么一个Document d的内容是如何生成的?
对于Document d中的每个word(单词),首先从![]() (作者集合)中等概率选择一个作者,然后根据此作者在Topics上的概率分布,随机选择一个Topic,最后根据这个Topic在words(单词)上的概率分布,随机产生这个单词。
(作者集合)中等概率选择一个作者,然后根据此作者在Topics上的概率分布,随机选择一个Topic,最后根据这个Topic在words(单词)上的概率分布,随机产生这个单词。
如果Document d 中的单词有![]() 个,这个过程要重复
个,这个过程要重复![]() 次。
次。
每个Document都这么做便生成了整个数据集合。
我们用个例子也解释这个过程。
Document 1表示为:
![clip_image001[1]](http://hi.csdn.net/attachment/201008/15/0_1281880476KGg8.gif "clip_image001[1]")
对于第一个单词good,它是这么产生的:从![]() = {张三,李四}中等概率随机选择一个作者,假设选中了“张三”,然后根据张三在Topics上的概率分布(0.1,0.6,0.3)随机选择一个Topic,选中Topic2的可能性较大,假设选中了Topic2。再根据Topic2在words上的概率分布,选择word(单词),这次正好选中了“good”。
= {张三,李四}中等概率随机选择一个作者,假设选中了“张三”,然后根据张三在Topics上的概率分布(0.1,0.6,0.3)随机选择一个Topic,选中Topic2的可能性较大,假设选中了Topic2。再根据Topic2在words上的概率分布,选择word(单词),这次正好选中了“good”。
Author Topic Model 认为所有Document的内容都是这样生成的。而我们面临的问题是,如果我们认可我们的数据集就是这么产生的,反过来我们要推断这个生成过程是怎样的,即估计每个作者在Topic上的概率是如何分布的,每个Topic在word(单词)上的概率是如何分布的。
Graph Model(图模型)
下面我们讨论Author Topic Model的Graph Model

我们这样理解这幅图:
箭头理解为变量之间的条件依赖,如图

![]() 条件依赖于w,或者说w概率生成
条件依赖于w,或者说w概率生成![]() 。方框表示重复采样(生成),次数在右下角标识,如上图,重复采样了N次。
。方框表示重复采样(生成),次数在右下角标识,如上图,重复采样了N次。
在Author Topic Model中,Document(文章)中的单词w,和共同作者![]() 都是已知的,或者说是可观察的,在图上表示为有填充的圆。
都是已知的,或者说是可观察的,在图上表示为有填充的圆。
每个author都对应一个在topics上的多项分布 ,图中用![]() 表示。每个topic都对应一个在words(单词)上的多项分布,图中用
表示。每个topic都对应一个在words(单词)上的多项分布,图中用![]() 表示。
表示。
![]() 和
和![]() 都有一个对称的 Dirichlet prior
都有一个对称的 Dirichlet prior ![]() 。也就是
。也就是![]() 和
和![]() 是依靠了先验知识。A表示数据集合中作者的总个数,T是Topic的个数。
是依靠了先验知识。A表示数据集合中作者的总个数,T是Topic的个数。
对于一个Document中的每个单词,我们从![]() (作者集合上的均匀分布)中随机采样一个作者x,然后从和x对应的多项分布
(作者集合上的均匀分布)中随机采样一个作者x,然后从和x对应的多项分布![]() 中采样一个Topic z,再从Topic z 对应的多项分布
中采样一个Topic z,再从Topic z 对应的多项分布![]() 中采样一个单词。采样过程重复
中采样一个单词。采样过程重复![]() 次,生成Document。D个Document重复这一过程,便生成了整个数据集。
次,生成Document。D个Document重复这一过程,便生成了整个数据集。
Bayesian Estimation of the Model Parameters
模型参数的贝叶斯估计
在Author Topic Model 中,有两组未知参数:author-topic 分布![]() ,
,
和topic-word分布![]() 。我们采用 Gibbs sampling 方法估计它们。
。我们采用 Gibbs sampling 方法估计它们。
对于每个单词,根据下面公式为其采样author和topic。

这里![]() 代表一篇文章中第i个单词分配给第j个Topic和第k个作者。
代表一篇文章中第i个单词分配给第j个Topic和第k个作者。![]() 代表第i个单词是词典中第m个词汇。
代表第i个单词是词典中第m个词汇。![]() 代表除第i个单词之外其余单词的Topic和Author分配。
代表除第i个单词之外其余单词的Topic和Author分配。
 表示单词m在此次分配之前已经分配给Topic j的总个数。
表示单词m在此次分配之前已经分配给Topic j的总个数。![]() 表示到目前为止,作者k分配给Topic j的总个数。
表示到目前为止,作者k分配给Topic j的总个数。
V是词典的总个数(数据集合中所有不同单词的个数),T是Topic 的个数。
在算法估计期间,我们只需要追踪两个矩阵。一个是V x T(word
by topic)计数矩阵,另一个是K x T (author by topic)计数矩阵。
最后,我们根据这两个计数矩阵估算author-topic 分布![]() 和topic-word分布
和topic-word分布![]() 。
。

![]() 表示Topic j 使用单词 m 的概率
表示Topic j 使用单词 m 的概率
![]() 表示作者k 在Topic j 的概率
表示作者k 在Topic j 的概率
算法一开始为每篇文章中每个单词随机分配一个Topic,随机分配一个作者(从这篇文章的作者集合中)。然后根据等式(1),对每篇文章中每个单词进行采样,采样重复I次。
假设 V x T(word by topic)计数矩阵 ![]() ,K x T (author by topic)计数矩阵
,K x T (author by topic)计数矩阵![]() 分别如下:
分别如下:
![]()
|
|


![clip_image001[2]](http://hi.csdn.net/attachment/201008/15/0_12818805380Mng.gif "clip_image001[2]")
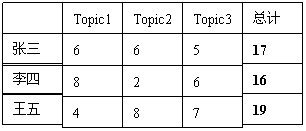
如何为“good”分配Topic和Author?
共有 {张三,Topic1}, {张三,Topic2},{张三,Topic3},
{李四,Topic1}, {李四,Topic2},{李四,Topic3} 六种可能。
这六种情况的概率是不一样的,根据等式(1)
 同理求出其余情况的概率,根据这个概率分布,随机产生一种分配。
同理求出其余情况的概率,根据这个概率分布,随机产生一种分配。
重复这一过程采样每个单词。
最后根据等式(2)和(3)求出![]() 和
和 ![]() 。
。
附录:
在AT原始paper中有幅贝叶斯网络图,想看懂这幅图只需要一点贝叶斯网络的基础知识就可以了,所以这里把需要理解的地方列出来。
先举一个例子:联合概率P(a,b,c)=P(c|a,b)P(b|a)P(a)可以表示为如下图

箭头表示条件概率,圆圈表意一个随机变量。这样我们就可以很容易的画出一个条件概率对应的贝叶斯网络。
对于更复杂的概率模型,比如

由于有N个条件概率,当N很大时,在图中画出每一个随机变量显然不现实,这是就要把随机变量画到方框里:
![clip_image025[1]](http://hi.csdn.net/attachment/201008/15/0_1281880546FXqq.gif "clip_image025[1]")
这就表示重复N个tn.
在一个概率模型中,有些是我们观察到的随机变量,而有些是需要我们估计的随机变量,这两种变量有必要在图中区分开:

如上图,被填充的圆圈表明该随机变量被观察到并已经设为了被观察到的值。














 7567
7567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










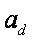{kind=link}
{kind=link}
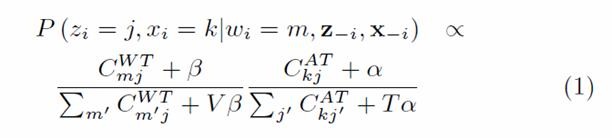{kind=link}
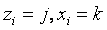{kind=link}
{kind=link}
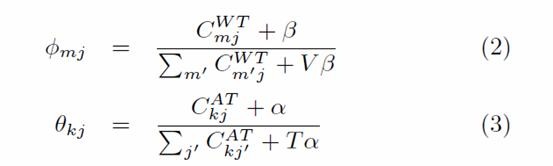{kind=link}
{kind=link}
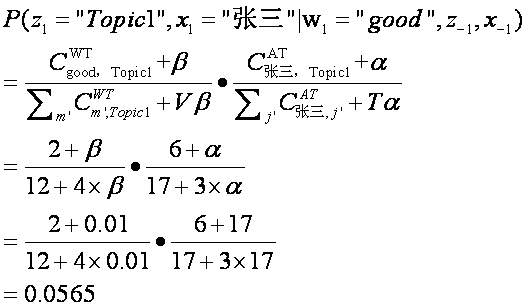{kind=link}