






比较排序是通过一个单一且抽象的比较运算(比如“小于等于”)读取列表元素,而这个比较运算则决定了每两个元素中哪一个应该先出现在最终的排序列表中。
声明:下面通过在维基百科中找到的非常完美的图示来介绍一系列比较排序。
插入排序
在该系列的【算法】1中我们便介绍了这个基本的算法,它的比较过程如下:
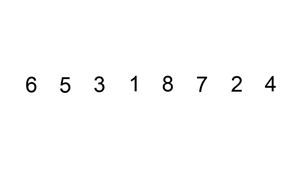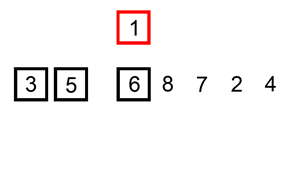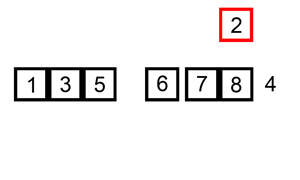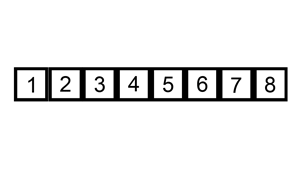
以下是用插入排序对30个元素的数组进行排序的动画:
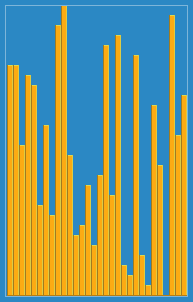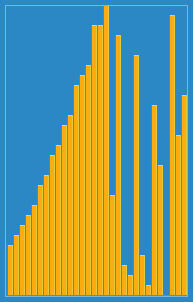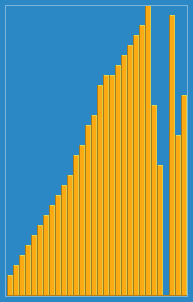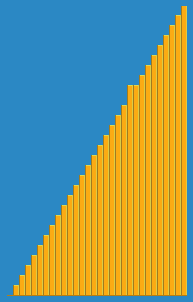
插入排序是最简单的排序算法,插入排序最差的复杂度是O(n^2)效率比较低适合少量数据进行排序,但是实现起来比较简单。在一组无序元素中选取第二位插入排序的key值,并用key值与其前面临近的元素做比较,如果大于key值就将其值后移一下,继续上key值与前面的做比较并重复移动位置。如果key前面的值都小于key就将key值后面的元素值赋值给key重复上述动作。(其根本就是在一个最小的有序序列中不断的插入数据且使其保持有序)
插入排序的实现:
private static void insertSort(int[] a) {
for(int j = 1; j < a.length; j++) {
int key = a[j];
int i = j - 1;
while(i >= 0 && a[i] > key) {
a[i + 1] = a [i];
i--;
}
a[i + 1] = key;
}
}选择排序
选择排序的比较过程如下:
其动画效果如下:

选择排序是通过遍历每一次都找出最小(最大)的数查找出来放在第一位,然后从第二个元素开始重复上边的动作即可完成排序。选择排序的时间复杂度为哦(n^2),且为非稳定排序算法。
实现代码如下:
private static void choseSort(int[] a) {
for(int i = 0; i < a.length; i++) {
int lowIndex = i;
int j = i + 1;
while(j < a.length) {
if(a[lowIndex] > a[j]) {
lowIndex = j;
}
j++;
}
int temp = a[i];
a[i] = a[lowIndex];
a[lowIndex] = temp;
}
}归并排序
前面多次写到归并排序,它的比较过程如下:
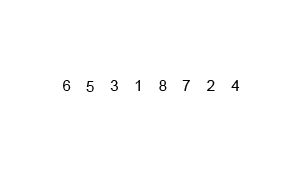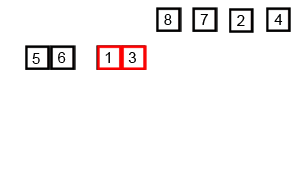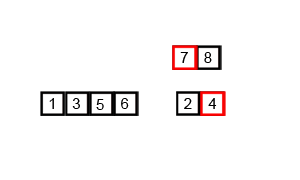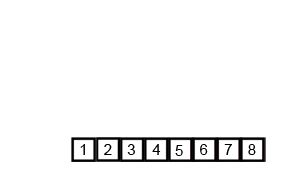
归并排序的动画如下:

private static void margeSort(int[] a,int left, int right) {
if(left < right) {
int middle = (left + right)/2;
System.out.println("middle:" + middle);
margeSort(a,left, middle);
margeSort(a, middle + 1, right);
marge(a, left, right, middle);
}
}
private static void marge(int[] a,int i, int j, int middle) {
int[] temp = new int[a.length];
int k = i;
int tempFirst = i;
int mid = middle +1;
while(i <= middle&& j >= mid) {
if (a[i] < a[mid]) {
temp[k++] = a[i++];
} else{
temp[k++] = a[mid++];
}
}
while(i <= middle) {
temp[k++] = a[i++];
}
while(j >= mid) {
temp[k++] = a[mid++];
}
while (tempFirst <= j) {
a[tempFirst] = temp[tempFirst ++];
}
}
归并排序(Merge)是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,每个子序列是有序的。然后再把有序子序列合并为整体有序序列。
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。 将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。
实现代码:
堆排序(非稳定)
在该系列的【算法】4中我们便介绍了快排,构建堆的过程如下:

堆排序的动画如下:
堆排序和归并排序一样复杂度都是nlogn。同时和插入排序一样不需要额外的存储空间。堆排序是建立在完全二叉树的基础之上的。在进行堆排序事前我们首先需要对无序序列进行大顶堆(或者小顶堆)的构建。大顶堆的根节点的值是整个无序序列中值最大,将大顶堆根节点和最后一个节点交换,同时对剩下的n-i个节点进行大顶堆的构建,构建成功后重新将根节点的值和n-i进行交换,交换后对剩下的n-i-1个节点重新构建大顶堆。如此重复。
代码实现如下:
/**
* heap sort
*/
public static void heapSort(int[] array) {
buildHeap(array);
for (int a: array) {
System.out.println(a);
}
System.out.println("**************");
for (int i = array.length -1;i > 0; i--) {
swap(array,0,i);
heapify(array,0, i);
}
}
/**
* 根据parentnode leftnode rightnode 调整位置
* 在调整位置后递归调整做出位置交换的子节点的位置是否符合大顶堆状态
* @param array
* @param i
* @param length
*/
private static void heapify(int[] array, int i, int length) {
int left = i * 2 + 1;
int right = i * 2 + 2;
int max = 0;
if (array[left] > array[i] && left < length) {
max = left;
} else {
max = i;
}
if (right < length && array[right] > array[max]) {
max = right;
}
if (max != i) {
swap(array, i, max);
heapify(array, max, length);
}
}
/**
*构建大顶堆
* @param array
*/
private static void buildHeap(int[] array) {
for (int i = array.length/2 -1; i>= 0; i--) {
heapify(array,i, array.length);
}
}
/**
* 交换
* @param array
* @param i
* @param j
*/
private static void swap(int[] array, int i, int j) {
int temp = array[i];
array[i] = array[j];
array[j] = temp;
}快速排序
设要排序的数组是A[0]……A[N-1],首先任意选取一个数据(通常选用数组的第一个数)作为关键数据,然后将所有比它小的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一趟快速排序。值得注意的是,快速排序不是一种稳定的排序算法,也就是说,多个相同的值的相对位置也许会在算法结束时产生变动。
在该系列的【算法】5中我们便介绍了快排,它的比较过程如下:
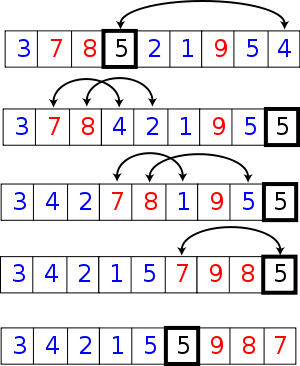
快速排序的动画如下:
快速排序的实例代码:
<1>递归实现方法:
/**
* Created by cike on 16/4/16.
*
* 快速排序是在复杂度同为O(N * logN)的集中算法中效率较高的一种.
* 同时快速排序中运用的分治思想.
*/
public class Quicksort {
public void quicksort(int n[], int left, int right) {
int dp;
if (left < right) {
dp = partition(n, left, right);
quicksort(n, left, dp - 1);
quicksort(n, dp +1, right);
}
}
private int partition (int n[], int left, int right) {
int pivot = n[left];
while (left < right) {
while (left < right && n[right] >= pivot)
right--;
if (left < right)
n[left++] = n[right];
while (left < right && n[left] <= pivot)
left++;
if (left < right)
n[right--] = n[left];
}
n[left] = pivot;
return left;
}
}
<2>非递归方法:
/**
* 非递归方法
*/
public void sort(int[] n, int left, int right) {
Stack<Integer> stack = new Stack<Integer>();
if (left < right) {
int mid = partition(n, left, right);
if (left < mid -1) {
stack.push(left);
stack.push(mid -1);
}
if (right > mid + 1) {
stack.push(mid +1);
stack.push(right);
}
while (!stack.empty()) {
right = stack.pop();
left = stack.pop();
mid = partition(n, left, right);
if (left < mid -1) {
stack.push(left);
stack.push(mid -1);
}
if (right > mid + 1) {
stack.push(mid + 1);
stack.push(right);
}
}
}
}另外一些比较排序
以下这些排序同样也是比较排序,但该系列中之前并未提到。
Intro sort
该算法是一种混合排序算法,开始于快速排序,当递归深度超过基于正在排序的元素数目的水平时便切换到堆排序。它包含了这两种算法优良的部分,它实际的性能相当于在典型数据集上的快速排序和在最坏情况下的堆排序。由于它使用了两种比较排序,因而它也是一种比较排序。
冒泡排序
大家应该多少都听过冒泡排序(也被称为下沉排序),它是一个非常基本的排序算法。反复地比较相邻的两个元素并适当的互换它们,如果列表中已经没有元素需要互换则表示该列表已经排好序了。
上面的描述中已经体现了比较的过程,因而冒泡排序也是一个比较排序,较小的元素被称为“泡(Bubble)”,它将“浮”到列表的顶端。
尽管这个算法非常简单,但大家应该也听说了,它真的非常的慢。
冒泡排序的过程如下:
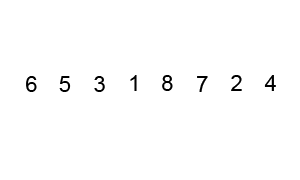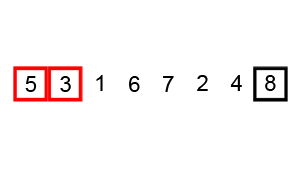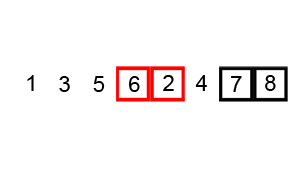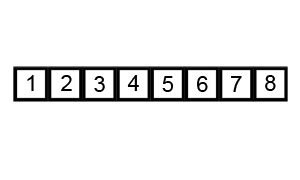
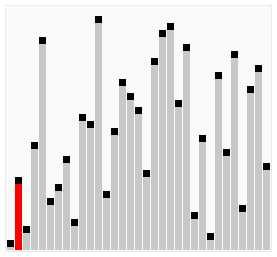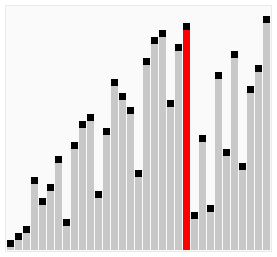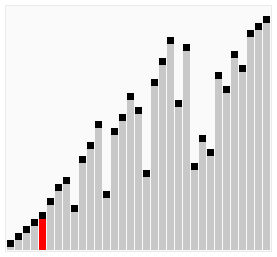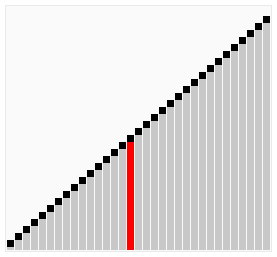
冒泡排序的动画演示:

其最好情况、最坏情况的运行时间分别是: Θ(n) 、 Θ(n2) 。
代码实现:
private static void bubbleSort(int[] a) {
for (int i = 0;i < a.length; i++) {
for (int j = 1; j < a.length - i; j++) {
if (a[j -1] > a[j]) {
int temp = a[j];
a[j] = a[j - 1];
a[j - 1] = temp;
}
}
}
}奇偶排序
奇偶排序和冒泡排序有很多类似的特点,它通过比较在列表中所有的单双号索引的相邻元素,如果有一对是错误排序(也就是前者比后者大),那么将它们交换,之后不断的重复这一步骤,直到整个列表排好序。
而鉴于此,它的最好情况、最坏情况的运行时间均和冒泡排序相同: Θ(n) 、 Θ(n2) 。
奇偶排序的演示如下:

下面是C++中奇偶排序的示例:
双向冒泡排序
双向冒泡排序也被称为鸡尾酒排序、鸡尾酒调酒器排序、摇床排序、涟漪排序、洗牌排序、班车排序等。(再多再华丽丽的名字也难以弥补它的低效)
和冒泡排序的区别在于它是在两个方向上遍历列表进行排序,虽然如此但并不能提高渐近性能,和插入排序比起来也没太多优势。
它的最好情况、最坏情况的运行时间均和冒泡排序相同: Θ(n) 、 Θ(n2) 。
排序算法的下界
我们可以将排序操作进行得多块?
这取决于计算模型,模型简单来说就是那些你被允许的操作。
决策树
决策树(decision tree)是一棵完全二叉树,它可以表示在给定输入规模情况下,其一特定排序算法对所有元素的比较操作。其中的控制、数据移动等其他操作都被忽略了。
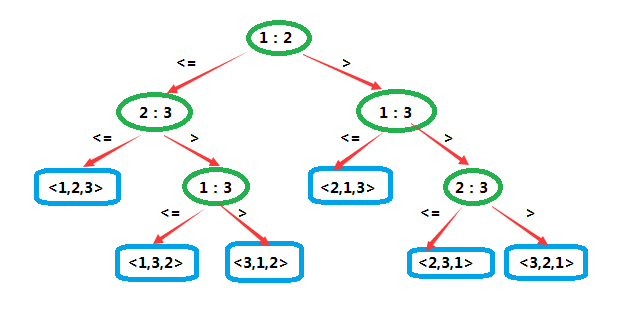
这是一棵作用于3个元素时的插入排序的决策树。标记为 i:j 的内部结点表示 ai 和 aj 之间的比较。
由于它作用于3个元素,因此共有 A33=6 种可能的排列。也正因此,它并不具有一般性。
而对序列 <a1=7,a2=2,a3=5> 和序列 <a1=5,a2=9,a3=6> 进行排序时所做的决策已经由灰色和黑色粗箭头指出了。
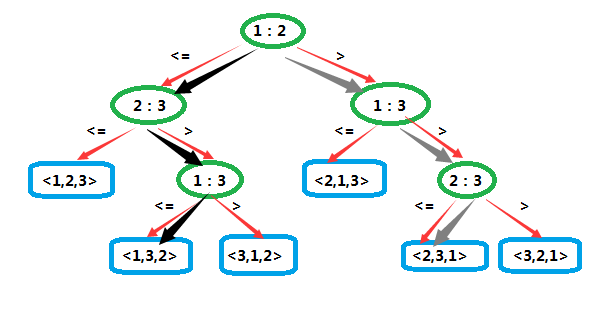
决策树排序的下界
如果决策树是针对n个元素排序,那么它的高度至少是 nlgn 。
在最坏情况下,任何比较排序算法都需要做 Ω(nlgn) 次比较。
因为输入数据的 Ann 种可能的排列都是叶结点,所以 Ann≤l ,由于在一棵高位 h 的二叉树中,叶结点的数目不多于 2h ,所以有:
n!≤l≤2h
对两边取对数:
=> lg2h≥lgn!
=> lg2h=hlg2≥lgn!
又因为:
lg2<1
所以:
n≥lgn!=Ω(nlgn)
因为堆排序和归并排序的运行时间上界均为 O(nlgn) ,因此它们都是渐近最优的比较排序算法。















 1173
1173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









