







1.原理分析:
随机森林是通过自助法(boot-strap)重采样技术,从原始训练样本集N中有放回地重复随机抽取k个样本生成新的训练集样本集合,然后根据自助样本集生成k个决策树组成的随机森林,新数据的分类结果按照决策树投票多少形成的分数而定.
通俗的理解为由许多棵决策树组成的森林,而每个样本需要经过每棵树进行预测,然后根据所有决策树的预测结果最后来确定整个随机森林的预测结果.随机森林中的每一颗决策树都为二叉树,其生成遵循自顶向下的递归分裂原则,即从根节点开始依次对训练集进行划分.在二叉树中,根节点包含全部训练数据,按照节点不纯度最小原则,分裂为左节点和右节点,他们分别包含训数据的一个子集,按照同样的规则,节点继续分裂,直到满足分支停止规则,停止生长.
1.首先我们用N来表示原始训练集样本的个数,用M来表示变量的数目.
2.其次我们需要确定一个定值m,该值被用来决定当在一个节点上做决定时,会使用到多少个变量.m
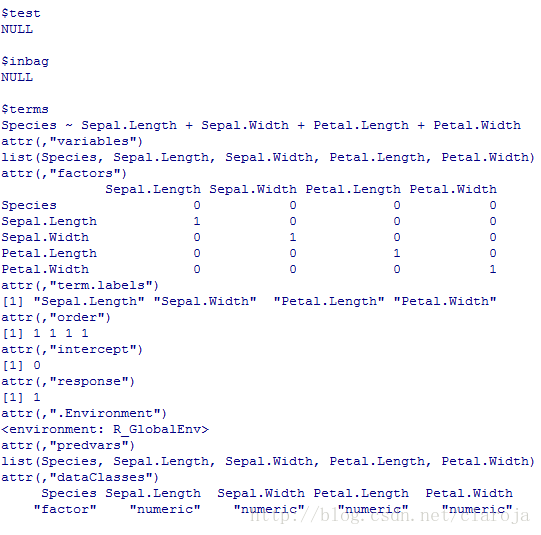
fit_rf=randomForest(Species~.,data=data_train,mtry=4,importance=TRUE,ntree=1000)
fit_rf[1:length(fit_rf)]
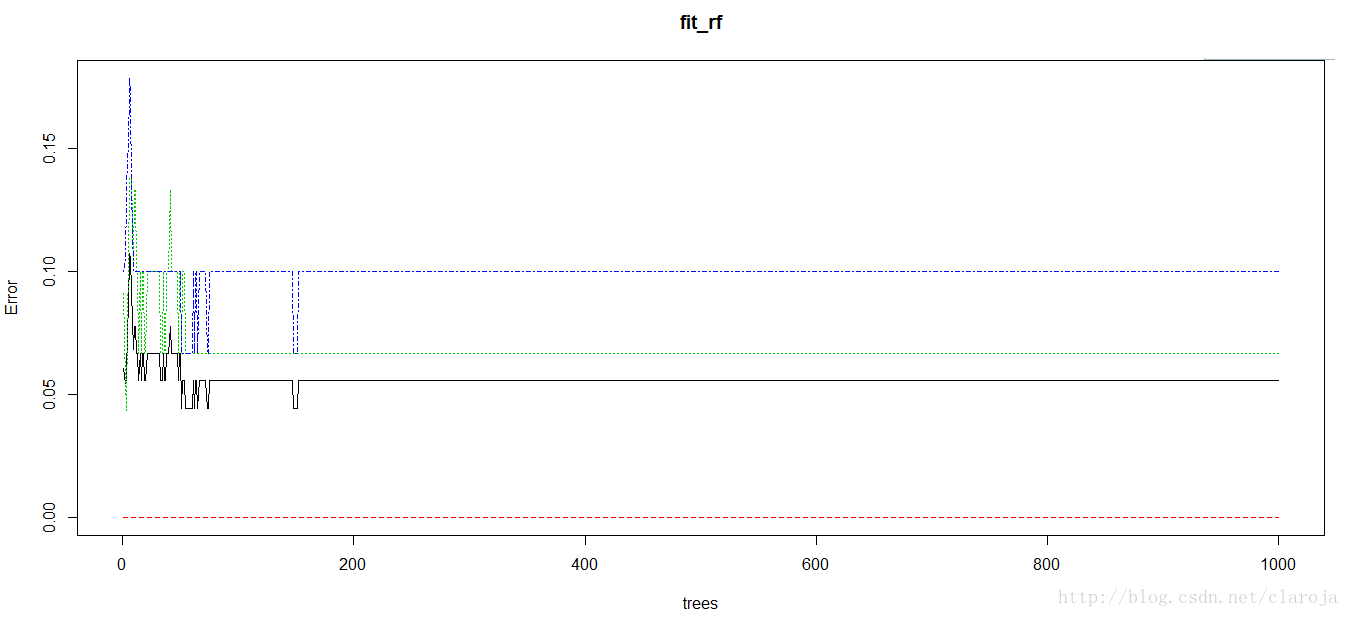
2)作图














 1185
1185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









