




Ranking SVM 简介
Learning to Rank
Learning to Rank(简称LTR)用机器学习的思想来解决排序问题(关于Learning to Rank的简介请见(译)排序学习简介)。LTR有三种主要的方法:PointWise,PairWise,ListWise。Ranking SVM算法是PairWise方法的一种,由R. Herbrich等人在2000提出, T. Joachims介绍了一种基于用户Clickthrough数据使用Ranking SVM来进行排序的方法(SIGKDD, 2002)。
Ranking SVM
我们可以学习得到一个分类器,例如SVM,来对对象对的排序进行分类并将分类器运用在排序任务中。这被Herbrich隐藏在Ranking SVM方法后的思想。
图1展示了一个排序问题的例子。假设在特征空间中存在两组对象(与两个查询相关联的文献)。进一步假设有三个等级(级别)。 例如,第一个组中的对象 x1 , x2 和 x3 分别有三个不同的级别。权重向量 ω 对应的线性函数 f(x)=⟨ω,x⟩ 可以对对象进行评分并排序。使用排序函数对对象进行排序等价于将对象投影到向量,并根据投影向量对对象进行排序。 如果排序函数是‘优秀’,那么等级3的对象应该排在等级2的对象之前,以此类推。要注意属于不同组的对象之间不能进行比较。

Fig. 1 Example of Ranking Problem
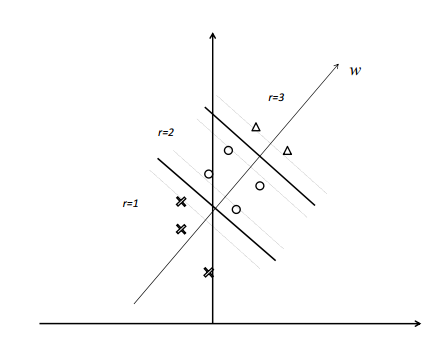
Fig. 2 Transformation to Pairwise Classification
图2显示了图1描述的排序问题可以被转化为线性的SVM分类问题。同一组中的两个特征向量之间的差别被作为新的特征向量对待, e.g.,x1−x2,x1−x3 , and x2−x3 . 进一步,标签也被赋给了新的特征向量。例如, x1−x2,x1−x3 , and x2−x3 为正数。同一级别的特征向量或者不同组的特征向量不会被组成新的特征向量。可以通过训练得到对图5中表示的新特征向量进行分类的线性SVM分类器。 几何学上,SVM模型的边缘表示两个等级对象对之间预测的最小间距。 注意到SVM分类器的分类超平面通过对应对的原点和正样本还有负样本。 例如 x1−x2 and x2−x1 代表正样本和负样本。SVM分类器的权重向量 ω
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1242
1242






 到【灌水乐园】发言
到【灌水乐园】发言







