




 Spanner是一种全球规模的分布式数据库系统,旨在提供高性能、高可靠性和跨机房数据一致性。通过使用TrueTime API确保时间戳的一致性,并利用Paxos算法来管理数据的读写一致性。
Spanner是一种全球规模的分布式数据库系统,旨在提供高性能、高可靠性和跨机房数据一致性。通过使用TrueTime API确保时间戳的一致性,并利用Paxos算法来管理数据的读写一致性。
作者:刘旭晖 Raymond 转载请注明出处
Email:colorant at 163.com
BLOG:http://blog.csdn.net/colorant/
更多论文阅读笔记 http://blog.csdn.net/colorant/article/details/8256145
关键字
Spanner, 外部一致性, 跨机房, True time
== 目标问题 ==
提供一个高性能,全球规模的分布式同步备份数据库
== 核心思想 ==
Spanner的设计目标是支持分布于上百个数据中心,可达百万级数量规模服务器的高性能数据库。其重点在于以较高的性能提供高可靠性和跨机房的数据一致性。
Spanner以基于时间戳的方式实现了数据读写的全局一致性,而在全球规模的数据库中高效的实现这一点,其关键在于底层的TrueTime API的实现。
TrueTime API 的实现基于GPS和原子钟,在全球范围内保证各个服务器取得的时间的绝对误差在1-7毫秒级别以内
在TrueTime API提供的精确时间戳的基础上,Spanner通过Paxos选举出来的Leader协调和管理两阶段commit的绝对时间和提交次序,进而保证数据的读写一致性。
== 实现 ==
Spanner的一个集群部署称为一个Universe,每个Universe由众多Zone组成,每个Zone大致可以类比为一个BigTable的集群。Zone内部包含一个ZoneMaster管理数据分配,数百到上千个SpanServer负责实际的数据存储和查询,若干Location Proxy用来路由客户端到特定的SpanServer。UniverseMaster仅起到性能数据监控的作用。每个Zone都是一个物理隔离的单位,Placement Driver负责数据在各个Zone之间进行备份和迁移。
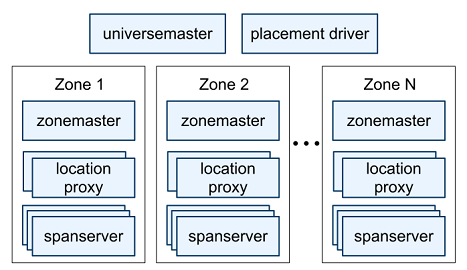
SpanServer内部的数据组织形式类似于BigTable的Tablet,但是从论文上看起来,和Bigtable并没有任何关系。每个SpanServer管理数百到上千个Tablet(包含类似多版本的Key->Value映射形式的数据)每个Tablet之上都架构了一个Paxos状态机用于协同并发操作。底层文件系统为Colossus(号称GFS的下一代,没有查到相关文献。。。)
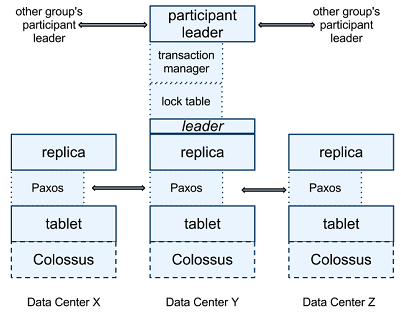
所有的写操作必须要由Leader发起,而读操作可以由数据时间戳满足更新状态的服务器直接完成。在跨Tablet的操作中,各个Paxosgroup的leader会进行协同工作。
== 相关研究,项目等 ==
Spanner的设计目标和Megastore很相似,Megastore的问题在于并发的写操作的吞吐率可能很差。没有详细的同类应用场合的测试数据作比较,只能相信Spanner论文的说法。从粗略的原理上看,个人理解Spanner能做得更好的原因大概是:
- 更细力度的Paxos状态机(Tablet v.s. entity group)减少了冲突的可能性
- Megastore的底层架构在HBase上,通讯开销较大,Spanner直接管理Tablet,简化了层次
- True Time API base的全局一致性的支持,简化了并发读写的实现逻辑(这点还要好好体会一下)

















 685
685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









