







 本文介绍了神经网络语言模型如何解决n元语法模型的数据稀疏问题,通过词向量表示使意义相近的词在空间中相似。讨论了词向量训练和基于词性困惑度的训练方法,并提供了PyTorch实现词嵌入的简单示例。
本文介绍了神经网络语言模型如何解决n元语法模型的数据稀疏问题,通过词向量表示使意义相近的词在空间中相似。讨论了词向量训练和基于词性困惑度的训练方法,并提供了PyTorch实现词嵌入的简单示例。
这次我们来讲讲神经网络语言模型,我们主要来谈谈为什么要使用神经网络。以及一些关键的点,更详细的内容,比如关于神经网络的结构之类的,就不在这细细讨论了,这方面网上的讨论很多。
用n元语法,我们都知道如何表示一一个词的概率。
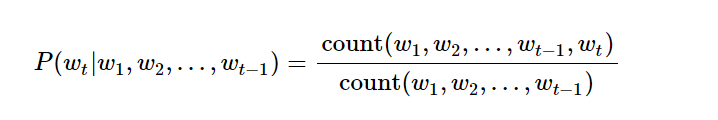
但是用这种方法有他的麻烦,我们都知道理论上,如果我们的n元数越大,结果应该是越精确的,但是实际中这种方法难以实行,原因在于随着我们的n元数增多,我们对数据数量的需求就越高。也就是说我们会面面临数据稀疏问题,举例来说吧。我们想知道 你 中国 后面接着 银行的概率,那我们的样本里面可能出现过很多次中国银行。这样的概率就很好统计,但是如果我们想预测 在北京的中国人民银行很 后面跟着好 的概率,那我们可能就会遇到概率为零的结果。因为我们训练语料里面没有出现这个词。我们训练数据应该尽可能地覆盖样本空间,才能得到一个满意得学习模型,但是随着我们参数维度升高,我们得样本空间指数级升高,而现实中得训练样本就那么多(一般训练样本获得得成本很大),所以在n元语法中,我们有时候会看到,随着n得数量升高,模型得性能反而下降。
以上是基于频率得概率统计得模型,但是如果我们在神经网络中使用n元模型,就可以解决这样得问题,这首先得益于我们对词得向量化表示,同时我们又通过词向量得训练使得意义相近得词他们得向量分布也相似。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3034
3034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









