






 本文介绍了四种基本的智能Agent程序类型,包括简单的反射Agent、基于模型的反射Agent、基于目标的Agent及基于实用性的质量的Agent,并阐述了它们的工作原理及适用场景。
本文介绍了四种基本的智能Agent程序类型,包括简单的反射Agent、基于模型的反射Agent、基于目标的Agent及基于实用性的质量的Agent,并阐述了它们的工作原理及适用场景。
AI 的任务是设计一个实现了 “agent 功能”的 “agent 程序”,它的目的是做“感知”到“行动”的映射关系。假设这个程序运行在某些具有物理感应器和行动器的计算设备上,我们称之为 architecture:
agent = architecture + program
显然,我们选择的 program 要适合这个 architecture ,如果 program 的行动是行走,那么 architecture 得有腿。architecture 可以是普通PC,或者一个有计算功能、感应器,摄像头的机器车。一般来说,architecture 让感应器的感知对 program 可用,然后运行 program,然后取出 program 的 action 到 actuators。
agent programs 的骨架基本相同:从sensor取得当前感知作为输入,返回 action 到 actuator。
还有coroutines的agent program,在环境中异步运行,每个coroutine都有一个输入和输出端口和一个循环,这个循环从输入端口读取感知然后向输出端口写入action。
“agent program”与“agent function”的不同是“agent program”只取当前的感知,而“agent function”取得整个感知历史。“agent program”只取当前的感知作为输入的原因是当前环境中也没有更多了。如果”agent function”需要依赖于整个感知序列,则需要记录感知。
这里有4种基本的agent program种类,体现了几乎所有智能系统的底层原理:
- 简单的反射agent
- 基于模型的 反射agent
- 基于目标的agent
- 基于实用性的质量的agent
简单的反射agent

基于当前的感知选择action,而无所谓其余的感知历史。比如前面的车停了,我也停车,这种叫做 condition–action rule或者说 if–then rules,写作 if car-in-front-is-braking then initiate-braking。
这种agent只有在环境是完全可见的情况下才能成功。
在部分可见的环境中,无限循环通常是不可避免的,如果可以随机化agent的action,则可以跳出无限循环。
基于模型的 反射agent

可以用model-based reflex agent处理部分可见的环境。
agent应该维护一些内部模型,这些内部模型依赖于感知历史,以及当前状态的不可见方面的一些反映。感知历史与action在环境上的影响可以由内部模型决定,而后像简单反射agent那样选择一个action。
把问题打碎,内部状态并不需要是多方面的,只需要摄像头的上一帧画面,让agent可以探测什么时候车边上的两个红灯持续亮或同时熄灭。对于其他的驾驶任务,比如改变航道,agent需要持续关注其他车辆在哪。还有,agent需要持续关注车钥匙在哪,以便能把车启动。
随着时间变化更新内部状态的信息需要在agent program中有两种知识:1,需要有关环境如何独立于agent变化的信息。2,需要agent自己的行动如何影响环境的信息。
这种关于“世界如何运转”的信息叫做“这个世界的model”。使用这个model的agent叫做model-based agent。
基于目标的agent

goal-based agent扩展了model-based agent的功能,goal信息描述了可取的情形,让agent在多个可能性中做出选择,选出那个能够到达目标状态的。涉及到AI的子领域:搜索和规划,以找到一个达到目标的action序列。
这种agent更灵活,因为支持其决定的知识是显式表示的,而且是可以修改的。
有时候知道当前的环境的状态也不能够决定要做什么,比如堵车时,车可以左转或右转,或直行,正确的决策取决于车要去哪里。换句话说,像当前的状态描述一样,agent需要一些goal信息,用于描述可取的情况,比如到乘客的终点。agent program 可以把它与model-based 反射agent组合起来选择action以完成目标。
基于实用性的质量的agent(utility based agent) utility == quality of useful

goal-based agent 只区分了 目标状态 和 非目标状态,其实可以定义某个特殊状态有多么可取的程度。这个程度可以通过utility function获取,而这个utility function将一个状态映射到状态的utility的程度上。
在大多数环境中,goal不能够生成高质量的行为。比如,很多个action序列可以到达目的地,但是有些更快,更安全,更便宜。goal只是单纯地划分“happy”或“unhappy”,而“happy”是不科学的,经济学家和计算机科学家使用utility代替。utility的意思是“实用性的质量”。
当goal有冲突时,只有部分可以达到(比如速度和安全),agent 的 utility function 会做权衡。
当所有goal都达不到时,agent 的 utility function 提供一种方式衡量goal成功的可能性,而不是goal的重要性。
一个 rational utility based agent 会选择能够最大化所期待的好的结果的action,也就是说,agent会根据每个结果的概率和utility权衡选择。utility based agent需要model并跟踪其环境,要做的足够好,涉及到perception, representation, reasoning, 和 learning。
learning agent
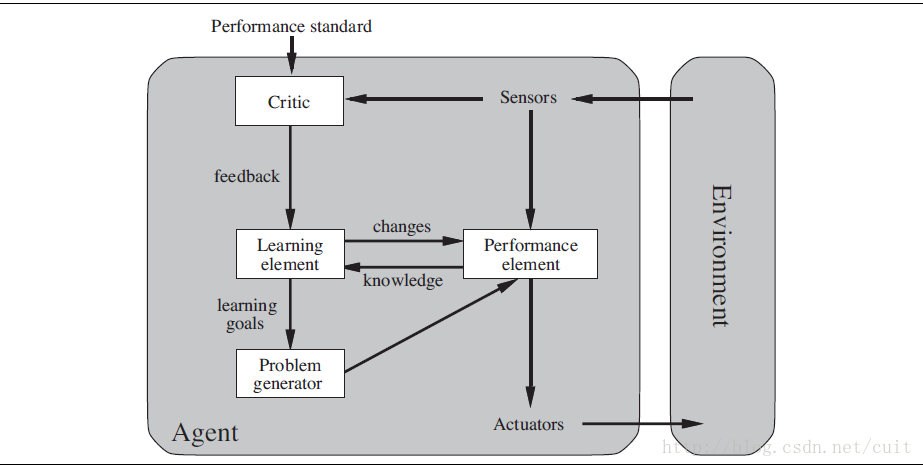
learning agent 可以让agent在未知环境中运行,而且可以变得更有能力。
learning agent 可以分成4块:learning element,负责改进。performance element,负责选择外部的action。learning element 从 critic 获取action的反馈以便决定如何改进。problem generator 负责建议能够带来新的且有信息量的经验的action。

















 2191
2191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









