







本着学习算法和锻炼英文水平的目的翻译了这篇颇具名气的《A* Pathfinding for Beginners》。这篇文章详细讲述了A*算法的基础,还在文后提出了很多相关的讨论主题,建议读者耐住性子通读全文,定会收益匪浅,且若是觉得中文翻译不够专业还请参阅原文。由于译者水平有限且自我锻炼的成分居多,翻译难免有谬误,还请不吝指教。
------------------------------------------------------------------------------------------------------------------------------------------
会者不难,A*(读作A星)算法,网上已经有很多文章介绍该算法,但是大多是写给那些已经了解算法基本原理的人看的,而这篇文章是写给真正的初学者的。
本文不求做到概括A*算法的全部工作,相反,是为了描述其算法基础及让读者做好准备以阅读和理解其他的文献资料。文章的最后给出了一些好的,以供深度阅读的链接。
最后,文章并没有给出具体的代码程序。你应当能够适应这里描述的原理适合于所有的编程语言。然而,也许和你期望的那样,文章最后我给出了一个例程的链接。这个样例程序包包含了两个版本:C++和Blitz Basic。同时包含了可执行程序以供观察A*的行为。
我们正在超越自己,让我们从头开始吧。。。
引言:搜索局域
假设我们希望从点A移动到点B,并且两点之间被一堵墙隔开。如下图所示,绿色代表起点A,红色代表终点B,蓝色的方块区域代表之间的墙。

图 1
首先,你应该已经注意到了,我们将搜索区域分成了方格网。像这样的简化搜索区域的工作往往是搜索路径的第一步。这一特定的方法将搜索区域简化成了一个简单的二维数组。数组中的每个元素代表方格网中的一个方格,另外其状态被标记为可通行的和不可通行的两种状态。我们需要找出从A到B需要经过的方格路径。当路径被找到之后,我们就可以从一个方格的中心移动到下一个方格的中心直到到达目标点。
这些中心点称作节点。当你在其他地方看到搜索路径的时候,经常会看到节点这一术语。为什么不称作方格呢?因为将路径搜索的区域划分成其他的形式也是可行的,例如长方形、六边形、三角形或其他任意图形。节点可以放置在这些图形的中心、边线和其他位置任何位置。我们选用这个系统是因为这是最简单的形式。
开始搜索
当我们将上图的栅格中的搜索区域划分成了合理个数的节点后,下一步是试图找到最短路径。我们从A点开始检测与其临近的方格,然后逐步向外扩散搜索直到找到最短路径。
我们通过以下步骤展开搜索:
1、 从点A开始,将其加入到一个待处理的“open list”方格链表中。open链表就像一张购物清单一样。到目前为止链表中只有一个节点,但是在以后的步骤中将会越来越多。链表中包含的方格可能在也可能不在你希望找到的最短路径中。基本上,这是一个需要检验的待处理链表。
2、检查与起点相邻的可到达或者可通过的方格,而忽略那些墙壁、水或者其他非法的障碍,也将他们加入到open链表中。对于这些新加入的方格而言,起点A是他们的“父方格”。父方格的概念对我们追溯路径及其重要,在后文中将详细介绍。
3、 将起点A从open链表中移出,加入到一个无需再进行检验的“close list”中。
此时,你应该可以得出下图所示的结果。如图所示,中间的深绿色的方格是起点方格,被淡蓝色框框住表示该方格已经加入到closed链表中。被放置到open链表中的与其相邻的方格被淡绿色的框框住,每个方格中有一个灰色的箭头指向他们的父方格,也就是起点方格。

图 2
下一步,我们在open链表中选择一个相邻方格,并或多或少地重复前面的步骤。但是该选择哪个方格呢?答案是具有最小F值的。
路径评分
找出最短路径中方格的关键是如下的等式:
F = G + H
其中
l G = 从起点A开始,沿着已经产生的路径到达给定方格的移动代价。
l H = 从当前给定的方格移动到终点B的预估移动代价。这也常被称作启发式的,这点有点令人疑惑。被称作启发式是因为这是一个猜测的过程。在找到路径之前,我们是无法获知真正的距离的,因为在路径中可能存在着各种类型的事物,例如墙壁、水等等。在网上,介绍计算H值方法的文章有很多种,但是本文仅仅给出了一种。
通过反复地遍历open链表并选出最小F值的方格而得到路径。本文将详细地介绍这个过程。首先,让我们更加详细地说明如何计算上面的等式。
承上所述,G等于从起点A开始,沿着已经产生的路径到达给定方格的移动代价。在本例中,我们假定每次水平移动和数值移动的代价为10,对角的移动代价为14。这些数值的由来是因为真正的对角移动是水平或者竖直移动的根号2倍,即大约1.414倍。为了简单起见,我们使用了10和14。这个比例大体正确,并且防止了计算开方和小数。这些数字对计算机来说也更快。你将很快发现,如果不使用这些捷径,路径搜索将是一个很慢的过程。
由于计算到给定方格的G值是沿着一条具体的路径,你可以首先计算其父方格的G值并加上10或者14,分别对应着直交线(非对角线)移动和对角线移动。在这个例子中,当我们从起点移动了超过一个方格时,这个过程将变得更加明晰。
计算H的方法有很多种,这里我们采用的是曼哈顿方法(Manhattan Method),这种方法计算从当前的方格水平移动或者竖直移动到目标点的方格总数,忽略了对角移动和障碍物。然后,将方格总数乘上水平或竖直移动一格的代价10。该方法称作曼哈顿方法的原因(可能)是在计算曼哈顿城区的街道时同样不能走街区的对角线的道理一样。
读完了上面的描述以后,你可能会猜想启发式方法仅仅是一个从当前的方格到目标点“笔直”距离的粗略估计,但是事实不是这样。实际上,我们试图沿着路径来估计剩余的距离。估计值越接近真实的剩余距离,算法的运算速度越快。然而,如果我们过多地估计了剩余距离,该算法不能保证会得出最短路径的结果。这种情况下,我们称作“不可接受的启发式”。
技术上,本例中使用的曼哈顿方法是不可接受的,因为它对剩余距离的估计稍微偏高。但是,我们仍然使用该方法,因为它够简单且仅仅稍微偏高。在仅有的少数不能得到最短路径的情况下,得出的结果也是接近最短的。想了解更过吗?你能在这里找到更多关于启发式的信息:http://www.policyalmanac.org/games/heuristics.htm
F是G和H的和。搜索的第一步结果如下图所示。F、G和H的值标记在每个方格中。正如起点的正右方的方格所示,F值标记在顶部左边,G在底部左边,H在底部右边。

图 3
让我们一同来看一下这些方格。如上图有字母在其中的方格,G=10,因为它仅在水平方向距离起点一个方格,起点方格的正上方、正下方的方格均有相同的G=10。对角线上的方格G=14。
H值通过上述的曼哈顿算法计算得到。使用这种方法得到在起点正右方的方格距离红色方格为3个方格,有H值30。其正上方有H值40。同样你能够看出其他方格的H值计算方法。
重复一遍,F值只是G和H的简单相加。
继续搜索
为了进一步搜索,我们选择在open链表中选择具有最小F值得方格。对所选方格进行如下的操作:
1、 将其从open链表中移出,加入到closed链表中;
2、 检查所有与其相邻的方格,忽略那些已经在closed链表中的和不可通行的(墙壁、水或者其他非法的地带),将不在open链表中的方格加入到open链表中,并将所选择的方格标记为他们的父方格;
3、 如果一个与其相邻的方格已在open链表中,检验到该方格的路径是否更优。换句话说,检查如果使用当前方格是否比所选的方格具有更小的G值,如果不是,就什么也不做;
另一方面,如果新路径的G值如果更小,就将选择的方格换成与其相邻的这个方格(如上图所示,改变箭头的方向,指向这个所选的方格)。最后,重新计算该方格的F值和G值。如果你还不够清楚,那就如下图所示。

图4
首先,我们将起点正右边的方格从open链表中移除,并加入到closed链表中(这也是将其用蓝色标记的原因)。然后我们逐一检测与其相邻的方格。所选方格的正右方是墙壁,忽略他们;正左方是已在closed链表中的起点方格,同样忽略他们。
其他的四个方格已经在open链表中了,我们要做的是检测利用该方格到达这些方格是否具有更小的代价。用G值作为指标。来检测一下所选方格的正上方的方格,目前的G值为14。如果我们利用目前所选的方格到达那里,G值将会达到20(10是起点达到所选点,再加上从所选方格数值移动一格的10)。20大于14,所以所选方格并不是一个更好的路径。这个结论很容易从图中看出。从起点直接对角移动一格比先水平移动一格再竖直移动一格更好。
对其他四个相邻的方格进行同样的检测,我们会发现利用所选方格到达他们的路径并没有优化,所以我们不做任何改变。现在我们检测完了所有的所选方格的相邻方格,下一步开始将检测下一个方格。
所以我们遍历open链表,目前有7个方格。我们挑选F值最小的方格。有趣的是,有两个方格的F值均为54。我们该选择哪个呢?其实这并不影响。为了加快算法速度,选择你最后加入到open链表中的那个更好。同样的偏好会在你更接近终点是得到体现。但是,这种偏好并不影响结果。(处理这种情况的方法不同会导致不同的A*算法得出的路径并不完全一致。)
所以,假定我们选择了如图所示的在起点右下方的方格。

图 5
此时,当我们检测与其相邻的方格时发现其正右方的方格是墙壁,忽略它。同样忽略其上方的方格。另外,我们忽略墙壁下方的方格,为什么呢?因为你无法不横切旁边的墙壁方格到达那里。你首先需要向下移动一格然后再移动到那里,以绕过墙壁方格。(注:横切墙角的规则是可选的,取决于你的节点的位置。)
如此,留下了5个需要检测的方格。该方格下方的两个方格不在open链表中,我们将他们加入open链表并将当前方格标记为他们的父方格。其他3个方格中的两个已经在closed链表中(即起点和所选点上方的方格,他们均在图中被标记为了蓝色),忽略他们。最后一个,在其正左方,需要检测其利用当前所选方格到达那里的G值是否更小。答案是否定的。所以我们需要检测open链表中的其他方格。
我们重复这样的过程将目标方格加入到了closed链表中,此时,有点像下图所示。

图 6
注意,与前图相比,起点方格下方第二个方格的父方格已经改变了。图5中该方格的G值为28,并指向左上方的方格。本图中,该方格的G值为20并指向其上方的方格。这个改变发生在搜索过程中,使用新路径时,该方格的G值更低,于是改变了其父方格并重新计算了其F值和G值。尽管这个改变在本例中无足轻重,但是很多情况下这样的数值检测对决定最短路径产生重要的影响。
所以,我们该如何决定路径呢?很简单,从红色的终点方格开始,沿着每个方格的箭头指向移动到父方格,最终将回到起点方格,就得到了路径。如下图所示,从起点A到终点B的路径仅仅是沿着路径的方格从一个方格的中心移动到下一方格的中心(节点)。
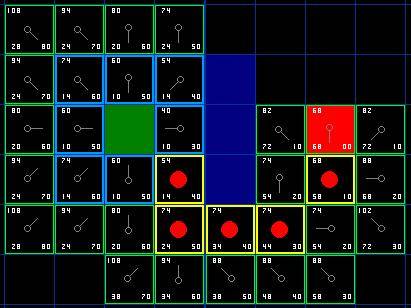
图 7
A*算法概要
好了,目前你已经跟着本文过了一遍,让我们将所有的算法步骤放到一起:
1、 将起点方格(节点)加入到closed链表中;
2、 重复以下步骤:
a) 在open链表中找具有最小F值的方格,将其标记为当前方格;
b) 将其加入到closed链表中;
c) 对其所有的8个相邻方格做如下操作:
l 如果该方格是不可通行的或者已经在closed链表中,则忽略他,否则,按以下步骤;
l 如果该方格不在open链表中,将其加入到open链表中,将当前所选的方格标记为其父方格,并计算F、G和H值;
l 如果该方格已经在open链表中,检测新路径到该方格的G值是否更优。更小的G值表明路径更好,如果是,则将该方格的父方格标记为所选方格,并重新计算F和G值。如果你的open链表是按F值排序的,此时则需要重新对链表进行排序;
d) 当以下情况发生则停止:
l 目标方格被加入到了closed链表中,此时路径被找到(注意以下的说明),或者
l 没有找到目标方格,并且open链表为空。此时,没有可行路径;
3、 保存路径。从终点回溯,沿着箭头所指方向移动到父方格直到到达起点方格,则得到了路径。
注意:在本文的早期版本中,写到了当目标方格(节点)被加入到open链表中就停止,而不是closed链表。这样的做法更快,并且在大多数情况下能得到最短路径,但并不总是这样。在倒数第二步向目标节点移动代价很大的情况下,结果会不一样。例如,两者之间有条不可逾越的河流的情况。
题外话
请恕我离题之嫌,你在阅读其他的A*算法文章或者分类论坛时,偶尔会发现有人将根本不是A*算法的代码说成是A*算法。你应该概括出上面讨论的A*算法的重要元素,例如open和closed链表,利用F、G和H值的路径评分。还有很多其他的路径搜索算法,但是他们并不是通常被认为是比很多其他算法更优的A*算法。本文后面的链接文章中Bryan Stout讨论了很多其他算法,列举了他们的优势和劣势。在有些情况下,其他算法的确更优,但是你要明白现在我们所讨论的主题。好了,废话很多了,让我们回到文章。
应用的注意事项
现在你已经了解了算法的基本原理,但是在写你自己的程序时仍然需要注意一些事项。以下内容是指我在写C++和Blitz Basic时遇到的,但是对其他语言同样有效。
1、 其他单位(防止碰撞):
如果你在研究我的样例代码,会发现程序完全忽略了屏幕中的其他单位。这些单位能够从彼此中间穿过。就这个游戏来说,这种情况可能是可接受的,也可能是不可接受的。如果你在搜索路径的时候希望考虑其他的单位,并希望他们互相绕行,我建议在搜索路径的时候仅仅考虑那些停止的或者是与对象单位相邻的单位,将他们目前的位置标记为不可通行的。对于移动的相邻单位,可以通过处罚那些处在移动路径上的节点来减少碰撞,同样可以鼓励对象单位寻找可替换的路径(详细请见条目2)。
如果你选择考虑那些移动的并且与对象单位不相邻的单位,需要找出一种方法可以及时预测这些单位在任意位置后将要移动到的位置,以保证他们不碰撞。否则,你将会得到一个曲折的路径去躲避已经移动走了的其他单位。
当然,由于随着时间的推移,无论你的路径在某个时候是多么的完美,一切都会随着时间改变,所以你需要写出一些碰撞检测的代码。如果碰撞发生了,该单位需要重新计算路径,或者如果其他的运动单位不是迎面而来,那就等待其通过再继续前进。
这些建议也许可以帮助你动手了。如果你还想了解更多,这里的链接也许对你有所帮助:
Steering Behavior for Autonomous Characters:作者Craig Reynold的这篇文章有别于搜索路径的操纵问题,但是可以将集成进来搜索路径问题,来完成一个更全面的运动和避碰系统。
The Long and Short of Steering in Computer Games:一篇有趣的关于操纵和路径搜索的调查文献。这是一个pdf格式文档。
Coordinated Unit Movement:作者是Age of Empires的设计者Dave Pottinger,他首次以两部分系列文章的形式就编队和分组运动问题展开讨论。
Implementing Coordinated Movement:Dave Pottinger系列文章的第二篇。
2、 不同的地带代价:本文和例程中,地带仅仅分为了可通行和不可通行两种形式。但是如果你想将某个地带设成可通行但是有更高的通行代价又该如何呢?例如沼泽地、山岭、地牢里的楼梯等等,这些都是可通行的但是具有比平坦开放的地带具有更高的通行代价的。类似地,道路拥有比周围地带更低的通行代价。
这个问题在你计算每个节点的G值时加上不同的地带代价就可以轻松解决。简单地说就是给这些节点加上额外的代价值。A*算法本质上就是寻找代价最低的路径,可以轻松解决这个问题。在我给出的简单的样例中,仅仅有可通行的和不可通行的两种地带,A*算法最终找到的是最短的、最直接的路径。但是在具有不同通行代价的地带环境中,最低代价的路径也许会具有更长的距离,例如绕着沼泽走而不是直接穿过它。
另外一个有趣的需要考虑的问题有个专业的名字叫“影响映射”,正如上面讨论的不同代价地带一样,你可以为实现AI而创建额外的点系统并将其应用到路径中。想象一下在一张地图上,一群单位阻止你穿过一块山地区域。每次电脑送来的某物试图通过这里,都将遭到重击。如果你希望的话, 你可以创建一个影响映射来惩罚大屠杀发生的区域。这将训练电脑找到更加安全的路径,不至于为了最短路径(但是更危险)而将部队源源不断地送死。
另一个可能的应用是惩罚那些处在周边其他运动单位路径上的节点。A*算法的一个弊端是当一群单位都试图找到通往相近目标的路径时,往往这些路径会发生很严重的重叠。给那些已经被占用的节点增加一定的惩罚有利于保证一定程度的路径分离,避免碰撞。然而不要将这些节点标记为不可通行的,因为在必要的情况下你仍然希望多个单位在狭小的通道中挤过去。同样,你只需要惩罚那些在搜索路径的单位附近的其他单位路径,并不是对所有的其他路径,否则,你将会导致你的单位在附近没有其他单位时出现奇怪的闪避动作。还有,你只能惩罚那些沿着你目前或者未来的路径上的节点,并不是目前的路径上那些已经访问过的节点。
3、 处理未知区域:你是否玩过这样的游戏,电脑总是知道该走哪条路,即使地图没有被探索过?这样的游戏中的路径搜索太完美了以至于不现实。幸运的是,这个问题可以很容易地解决掉。
解决方案是为每个不同的玩家和电脑对手创建一个分离的“已知可行”的数组(是玩家,不是每个单位,要是如此会消耗大量的内存空间)。每个数组包含了对应玩家已经探索过的区域,其他的区域默认为是可行的知道被证实。使用这种方法,在探索周围的区域之前,玩家的单位会走进死胡同,会犯同样的错误。然而,一旦地图被探索过了,路径搜索就会正常工作。
4、 更加平滑地路径: A*算法能够算出最短的、代价最低的路径,但是并不是会自动找到最平滑地路径。看一看例子中(图7)的最终路径,第一步路径在起点的右下方。如果用正下方的方格代替第一步会不会得到更加平滑地路径呢?
解决这个问题有很多不同的方法。在计算路径时,当路径方向改变时你可以给G值加上惩罚值。同样,你可以在路径计算完之后重新检查路径,选择路径节点相邻的节点代替路径节点后是否会得到更优的路径。想了解更多的关于这个问题,请查看Toward More Realistic Pathfinding,这篇文章(免费但是需要注册)在网站Gamasutra.com上,作者是Marco Pinter。
5、 非方格的搜索区域:在文章的例子中,使用的是一个简单的2D方格图形。其实你不需要采用这种方法,不规则的图形区域同样可以。参考棋盘游戏Risk及其上的国家,你可以像这个游戏一样为你的游戏设计路径搜索的方案。为了实现这个方案,你需要创建保存相邻国家信息的表格,以及从一个国家移动到下一个国家的G值,同样需要一个可行的方法来估计H值。剩下的问题就可以同上例一样处理。当向open链表中添加条目时,你可以仅仅简单地查看表中的相邻的国家,而不用使用相邻的方格。
相似地,你可以在一个固定的地图上为路径设计一个点系统。点系统通常指路径穿过点,也许是一条道路或者地牢中的关键隧道。作为游戏的设计者,你可以预先设计点系统。当两个路径点之间的连线上没有障碍物时认为他们是“相邻的”。在Risk游戏中,你可以讲这些相邻信息存放在一个查找表中,并在生成新的open链表条目时使用它。然后记录相关的G值(可以是两个节点之间的直线距离)和H值(可以是节点到目标点之间的直线距离)。其他的问题可以按正常方式处理。
Amit Patel 写过一篇概要文章(http://theory.stanford.edu/~amitp/GameProgramming/MapRepresentations.html)来探讨这些问题。关于在等轴RPG地图上使用非方格搜索区域的其他例子,请参见我的文章Two-Tiered A* Pathfinding。
6、 关于算法速度的建议:在开发你自己的A*算法程序或者改写例程时,你会发现路径搜索会消耗大量的CPU时间,特别是当有相当数目的路径搜索单位和相当大的地图时。如果你在网上阅读过相关的文章,你会发现这对设计Starcraft和Age of Empires游戏的专业人士来说同样是个问题。如果由于路径搜索而导致运行速度下降时,下面的点子可能会使运行速度快起来:
l 考虑使用更小的地图或者更少的单位。
l 不要在同时给多个单位使用路径搜索,可以将他们放在一个队列,并放到不同的游戏周期里。假设你的游戏如果是每秒40个周期,每人会发现这一改变,但是如果你同时计算这些路径,玩家就会发现游戏的速度下降了。
l 考虑使用更大的方格(或者你正在使用的图形)。这将减少寻找路径节点的总数。如果你觉得不够,在不同的路径长度时,可以设计在不同情形下使用的两个或者更多的路径搜索系统。专业人士经常这么干,为长路径使用大方格,并在接近目标时使用小方格/区域进行精细搜索。如果你对这个问题感兴趣,请参阅我的文章Two-Tiered A* Pathfinding。
l 对于一些长路径,考虑设计预先计算的路径并将其作为游戏的固有路径。
l 考虑预先处理地图,找出地图中不可达的区域。我将这些区域称作“岛”,现实中,他们可以是岛,也可以说既不能离开也不能进入的区域。A*算法的一个弊端就是一旦你让它搜索到达这些区域的路径时,它会搜索整个地图,在所有的可通行的方格/节点都被open和closed链表处理过后才停止。这将浪费很多的CPU时间。可以通过预先决策哪些区域是不可达的(通过洪水填满或类似方法)来解决,将这些信息记录在数组或者类似结构中,并在每次路径搜索之间检测它。
l 在拥挤的、类似迷宫的环境中,考虑使用像死胡同一样不能通向任何地方的标签节点。这样的节点可以在地图编辑器中手动预先指定,当然,如果你够有野心的话可以设计自动识别这些节点的算法。在给定的死区中的任何节点集合都会标上特殊的标志位,然后在路径搜索时仅仅在起点或者目标点在死区的情况下考虑这些死区,其他情况可以忽略这些死区。
7、 维护open链表:实际上这是A*算法最消耗CPU时间的部分。每次访问open链表时都需要找到具有最小F值的方格。有很多种方案可以使用,你可以根据需要保存路径节点,并仅仅在需要找到最小F值时遍历链表。这样是很简单,但是对长路径时会很慢。可以通过维护一个排序链表来提高性能,当需要找到F值最小的方格时,仅仅可以提取第一个元素。在我写这个程序的时候,我采用的是第一种方法。
这个方法对小地图很有效,但不是最快的方法。真正的A*算法程序员会使用二叉堆来获得提速,这也是我在代码中使用的。根据我的经验,这种方法在大多数情况下将至少提速2-3倍,对长路径是几何级数增速。如果你有兴趣了解更多关于二叉堆,参考我的文章Using Binary Heaps in A* Pathfinding。
另一个潜在的瓶颈是在路径搜索过程中的清理和维护数据格式问题。我个人更喜欢使用数组存放数据。当节点以面向对象的方式动态地生成、记录和维护时,我发现创建和删除这些对象时会消耗相当多得时间,这会导致额外不必要的时间天花板而使速度下降。然而,如果使用数组,每次访问都需要清理数据。在这种情况下你最不想做的就是在路径搜索之后花时间清除数组中的数据,特别是在有一张很大的地图时。
我是通过创建一个二维的数组whichList(x,y)解决时间天花板的,我将地图中节点通过数组标记为在open或者是closed中,在每次路径搜索之后并不需要清除该数组,而是在每次路径搜索时通过每次增加5或者其他来重置onClosedList 和onOpenList。我将F、G、H值同样存放在数组中,这样我就只需要覆盖已经存在的值而不必清除数组。
然而将数据存放在多维数组中消耗更多的内存,这需要折中处理。最后,你可以使用其他感觉好用的方法。
8、 Dijikstra算法:尽管A*算法被认为是最好的路径搜索算法(参见上面的题外话),至少还有一种其他的算法有着广泛的应用—Dijikstra算法。Dijikstra算法本质上与A*算法一样,只是没有启发式(H总为0)。由于其不具备启发性,其在每个方向上等价地向外扩张搜索。正如你所想的一样,由于Dijikstra算法在找到目标之前需要搜索更大的区域,所以使其比A*算法更慢。
所以为什么要使用它呢?有时我们并不知道目标点的位置。假设你有一个收集单位负责收集某种资源,它知道资源区域的位置,但是想去最近的一个。这里,Dijikstra算法比A*算法更优,因为我们无法知道哪个更近。唯一能做的就是重复使用A*算法知道找个每个路径的距离,然后选择最近。有无数种相似的情况,我们只知道我们需要搜索的区域,试图找到最近的区域,但是无法获知哪个会是最近的。
深度阅读
好了,目前你已经掌握了基本原理并了解了一些高级的概念,此时,我建议阅读我的源代码。代码包含有两个版本,C++和Blitz Basic。两个版本都有详细地注释,相对而言应该很容易理解。这里是链接。
l <a href="http://www.blitzcoder.com/cgi-bin/showcase/showcase_showentry.pl?id=turtle177604062002002208&comments=no">Sample Code: A* Pathfinder (2D) Version 1.9
如果你不能访问C++和Blitz Basic,这里有两个小的exe文件,Blitz Basic版本在Blitz Basic网站下载免费的Blitz Basic 3D(不是Blitz Basic Plus)运行。
同样你可以考虑阅读下面的网页,在你读完本文之后,阅读他们应该会容易很多。
l Amit's A* Pages:这是一篇Amit Patel的被广为引用的文章。在你读本文之前阅读可能会感到迷惑不解。非常值得阅读,参见Amit自己关于这个主题的思考:http://theory.stanford.edu/~amitp/GameProgramming/。
l Smart Moves: Intelligent Path Finding:这是一篇Bryan Stout的发表在Gamasutra.com上的文章,读者可以注册阅读。当然注册是免费的,仅仅为了这篇文章去注册都是值得的,更何况网站上还有很多其他的资源。Bryan用Delphi语言写程序帮助了我学习A*算法,也对我自己的A*算法程序有很大的启发。同时,他还讨论了A*算法的其他变种。
l Terrain Analysis:文章很高级但是很有趣,作者Dave Pottinger是一个Ensemble Studios的专家,他协助开发了Age of Empires和Age of Kings。不要期望完全理解这篇文章,但是会给你自己的问题带来一些启发。文章包含了多重贴图、影响力映射和其他高级的AI和路径搜索的概念。
其他值得参阅的网址:
· Game AI Resource: Pathfinding
好了,到此结束了。如果你正好将这里的概念写进你的程序我会很乐意看到,可以通过下面方式联系我:
pwlester@policyalmanac.org
好了,祝愿好运!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









