概述
传统的目标检测任务主要通过人工提取特征模型建立,常用的特征包括:HOG、SIFT、Haar等,特征提取模型之后进行支持向量机或者Adaboost的分类任务,进而得到我们所关注的目标结果。由于特征模型的局限性,我们引入卷积特征,也就是经过卷积神经网络得到的特征信息,包括浅层信息和深层信息,浅层信息指的是:前级的卷积层得到的特征图,感受野更加关注的是图像细节纹理等特征。深层信息包括:后级的卷积层卷积得到的特征图信息,在语义语境方面更加抽象的高层信息。人工神经网络是根据大脑神经突触联接的结构进行信息处理的数学模型,视觉模拟系统通过稀疏编码的方式组合成为合理并且高效的图像处理系统。
参考论文:
《What makes for effective detection proposals?》
《Region-based Convolutional Networks for AccurateObject Detection and Segmentation》
《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》
《You Only Look Once : Unified, Real-Time Object Detection》
《SSD: Single Shot MultiBox Detector》
《YOLO9000: Better, Faster, Stronger》
下面主要针对卷积神经网络的目标检测算法进行总结(包括以下(2)--(6)):
(1) 传统方法(DPM)
(2) R-CNN(卷积特征)
(3) SPP-NET/Fast R-CNN(卷积特征)
(4) Faster R-CNN(卷积特征)
(5) YOLO (v1 & v2)(卷积特征)
(6) SSD(卷积特征)
R-CNN
总体的步骤分为3个阶段:
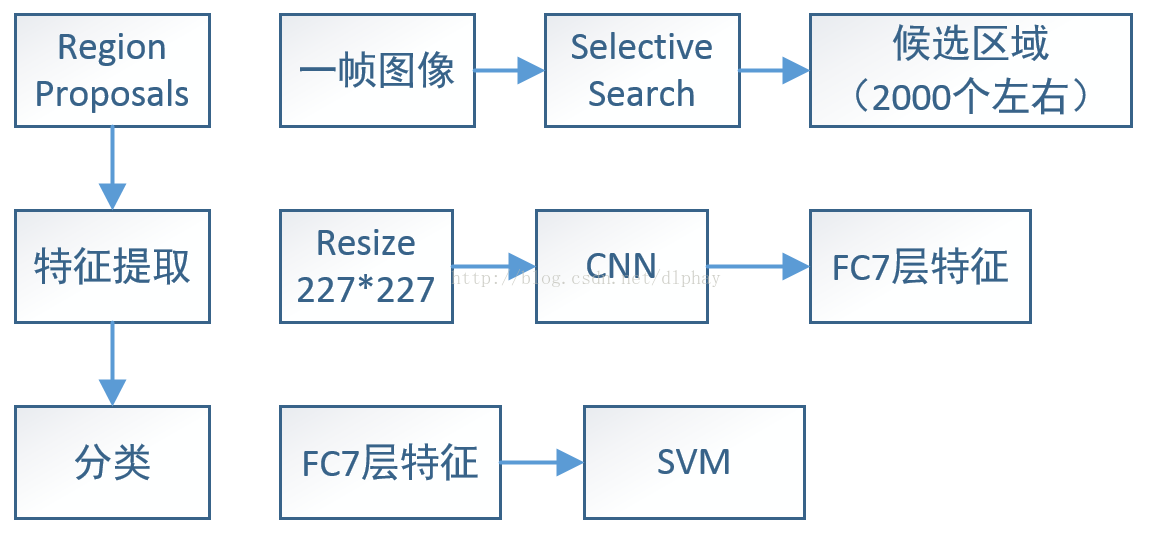
(1)第一阶段(Region Proposals阶段):对一帧图像采用Selective Search算法得到最有可能是目标的2000个左右的Region Proposals(候选区域),改善了传统滑窗的思想(复杂度在10万-100万个候选区域),Selective Search算法采用合并超像素生成proposals(具体的详细的介绍参考第一篇论文
《What makes for effective detection proposals?》)这是第一阶段,改善传统滑窗的笨方法,使得算法复杂度降低。
(2)第二阶段(特征提取):对于图像深层信息的理解,采用卷积神经网络抽取图像目标中卷积特征,这里需要主要的是:R-CNN会将上一阶段的2000张Region Proposals首先进行大小尺寸的归一化处理为227*227(像素大小),对每一个Region Proposals都要进行复杂的卷积计算(2000次同样的复杂卷积计算?对,没错,有一些细节差别很小的Region Proposals也要重新进行卷积计算,再强的GPU也HOLD不住这样折腾啊)。随后卷积层计算完成特征抽取完成之后,将全连接层的输出直接作为Region Proposals的特征信息,至此第二阶段完成。
(3)第三阶段(分类):这里跟传统的方法有似曾相识的感觉,根据特征(传统的方法利用人工特征模型,这里采用卷积神经网络全连接层输出作为卷积特征),利用支持向量机(这里我也做过一定的总结,有兴趣的可以作为参考)的方法将数据进行最大间隔可能的划分,使得分类效果达到预期效果。
效果(在GPU上完成计算):
速度:47s (最大的问题,这完全不能用好不好)
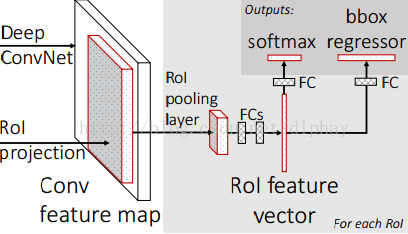
SPP-NET/Fast R-CNN
为什么把SPP-NET和Fast R-CNN模型放在一起进行讨论?两者只有细微的差别!
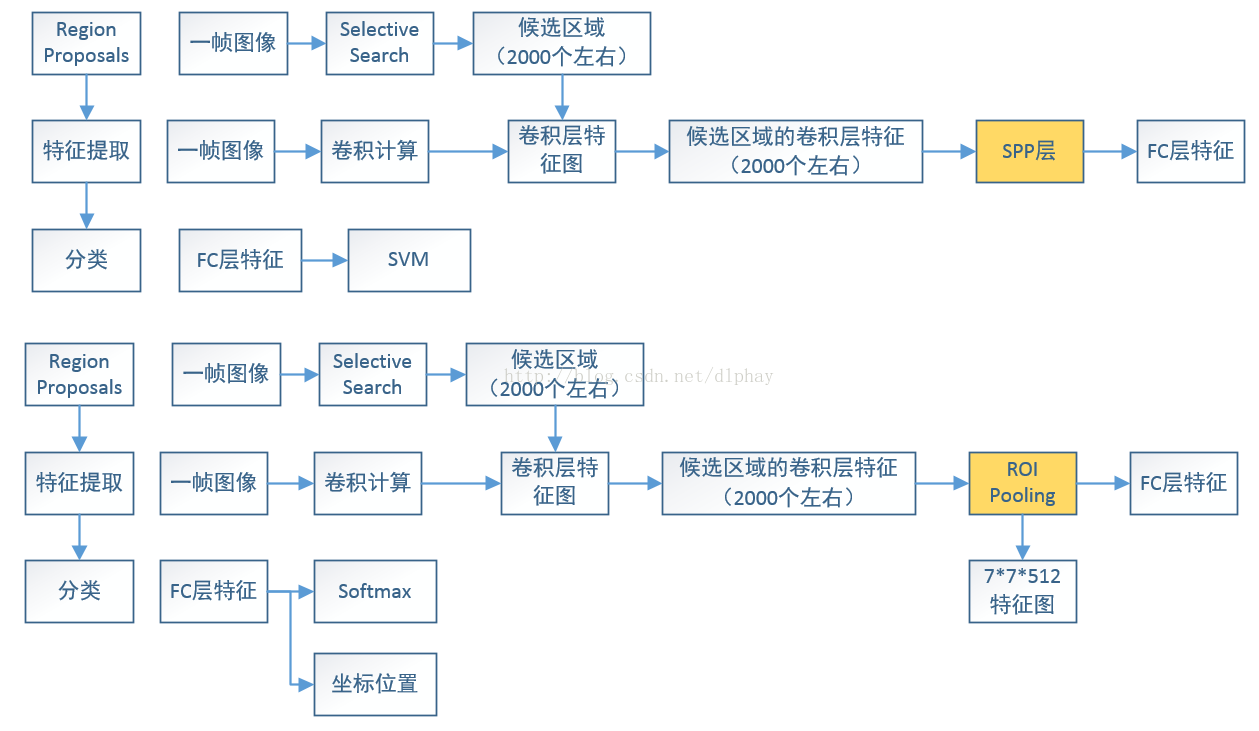
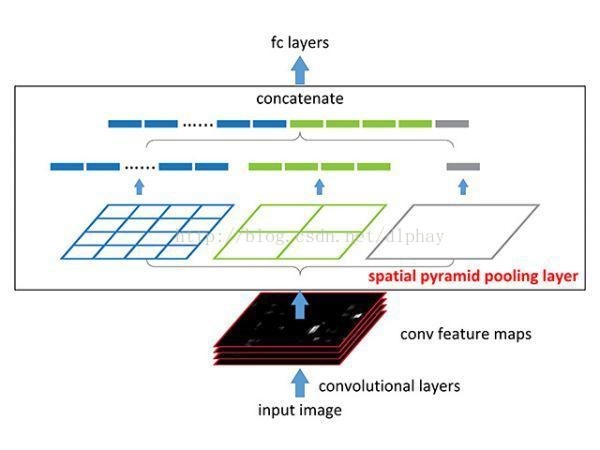
SPP-NET/Fast R-CNN都是在R-CNN基础上提出来的,也主要是对R-CNN的改进和优化。两者的改进是:第一点:减少不必要的卷积运算。第二点:SPP-NET模型特提出来SPP层对于Feature Maps大小尺寸不统一的问题;Fast R-CNN模型提出来ROI Pooling的方法进行解决问题(这里的问题是SPP-NET模型和Fast R-CNN模型共有的问题:简化卷积计算的过程中带来的Feature Maps大小各异问题,将2000个Feature Maps像素级归一化)。
同样这里也是三个阶段:
(1)第一阶段(Region Porposals):完全同R-CNN第一阶段,这里不再啰嗦。
(2)第二阶段(特征提取):这里是主要改进点!R-CNN是对2000个Region Proposals都要进行同样的卷积计算,模型在这里进行优化:对一帧图像复杂的卷积过程只进行一次,再通过特殊的映射方法将2000个Region Proposals映射为2000个Feature Maps。这样就解决了差异很小的Region Proposals进行大量相同卷积计算操作的运算量。接下来不具体介绍Feature Maps像素级归一化的过程,以下是两张图片。
(3)第三阶段(分类):Fast R-CNN提出了新的分类方法,在全连接层之后得到Roi Feature Vector,通过两部分进行分类:Softmax二分类作为概率层面(有无目标)的分类,再一部分是位置坐标的回归方法。
效果:
Region Proposals(Selective Search):2.5s 特征提取与分类:0.32s
可以看出来在Region Proposals阶段消耗的时间成为了主要焦点,我们可以想办法从这里再进行优化。就是接下来的Faster R-CNN,在准确性表现都不错的“端到端”卷积神经网络方法。
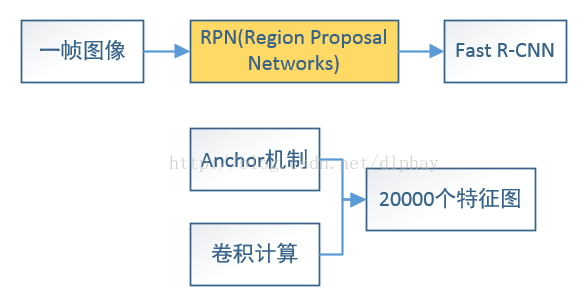
Faster R-CNN
同样Faster R-CNN是基于Fast R-CNN提出改进的优化网络,可以这么认为:Faster R-CNN = RPN + Fast R-CNN
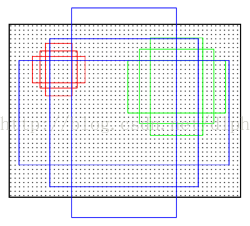
RPN的核心思想是:使用卷积神经网络直接产生region proposal,使用的方法本质上就是滑动窗口。RPN的设计比较巧妙,RPN只需在最后的卷积层上滑动一遍,因为anchor机制和边框回归可以得到多尺度多长宽比的region proposal。
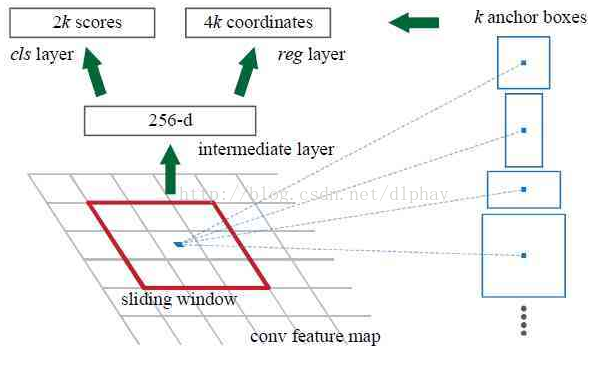
我们直接看上边的RPN网络结构图,给定一帧图像(假设分辨率为600*1000),经过卷积操作得到最后一层的卷积Feature Maps(大小约为40*60)。在这个Feature Maps上使用3*3的卷积核(滑窗)与特征图进行卷积,最后一层卷积层共有256个Feature Maps,那么这个3*3的区域卷积后可以获得一个256维的特征向量,后边接cls layer和reg layer分别用于分类和边框回归(跟Fast R-CNN类似,只不过这里的类别只有目标和背景两个类别)。3*3滑窗对应的每个特征区域同时预测输入图像3种尺度比(128,256,512),3种长宽(1:1,1:2,2:1)的region proposal,这种映射的机制称为anchor。所以对于这个40*60的feature map,总共有约20000(40*60*9)个anchor,也就是预测20000个region proposal。
RPN的总体Loss优化模型:
效果:
一帧图像的计算耗时:0.2s(仍然不能满足实时性,但是在准确率方面已经完全满足要求,比传统方法要好出很多。)
YOLO
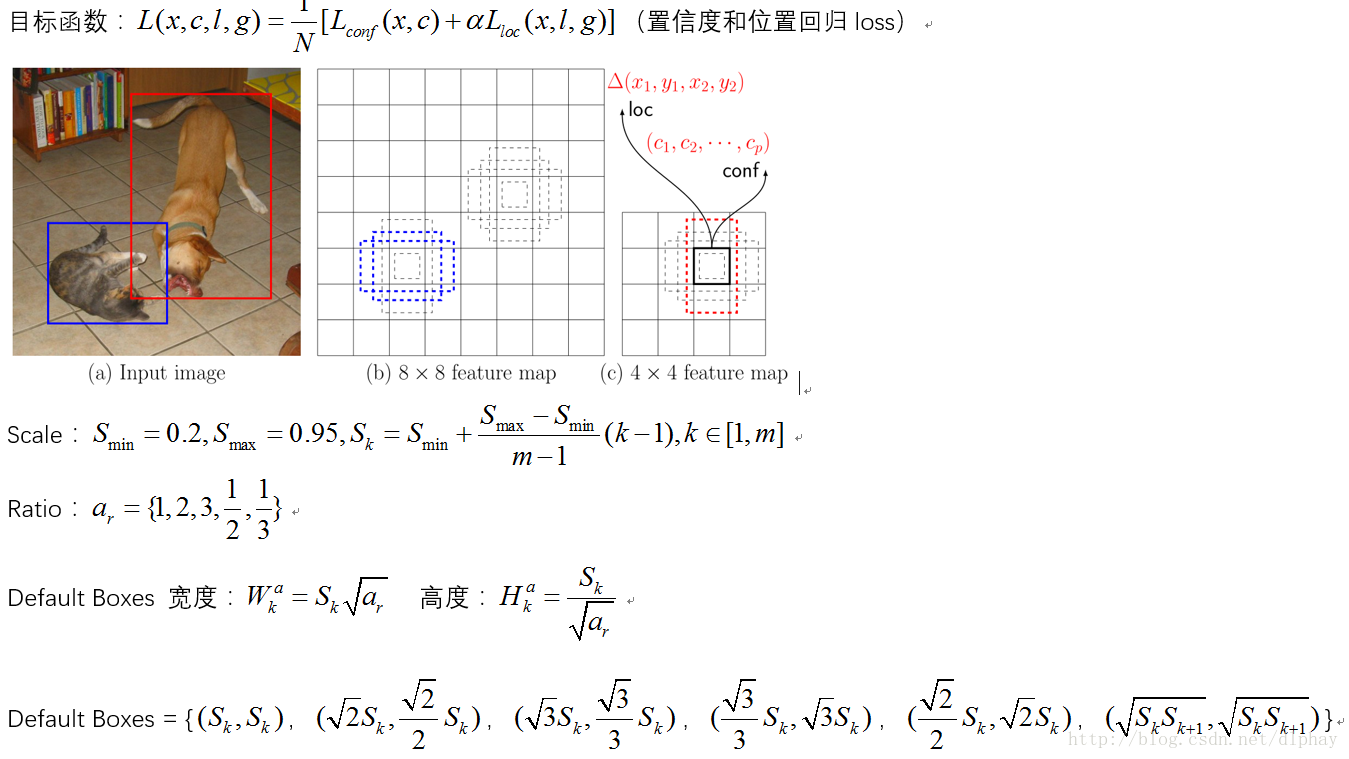
YOLO从本质上解决了目标检测领域一直无法实时性的棘手问题,“端到端”实现卷积神经网络结构。主要算法思路:将一帧输入图像直接经过网络端到端前向预测回归出具体类别概率以及坐标位置信息的回归模型,通过将一帧图像分解成为7*7的网格单元,每个网格单元预测出两个Bounding Boxes(可能是目标的Region Proposals),也就是7*7*2=98个潜在目标,网络回归为目标的位置信息(x,y)、尺寸信息(w,h)、置信度以及对应每个类别的概率信息(这里采用VOC数据作为举例说明)。
存在的问题就是:对于小目标和目标连接比较紧密的目标单位检测准确性比较差。
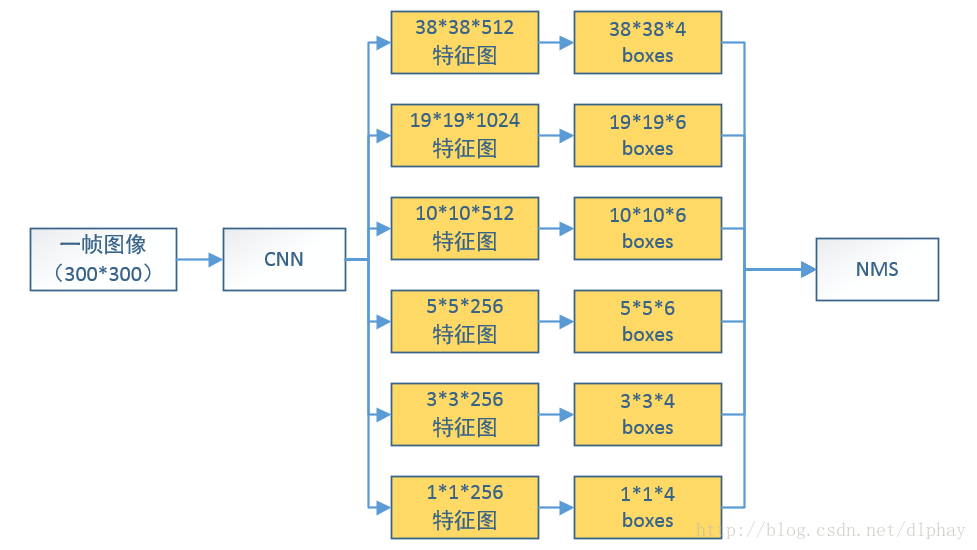
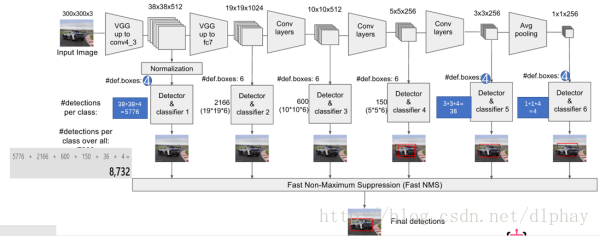
SSD
一帧图像经过卷积计算得到不同尺寸、不同位置的多类Boxes作为可能是目标的潜在目标作为识别,改进了YOLO目标位置准确性比较差的问题。最后经过NMS(非极大抑制)的方法筛选得到最终的检测结果。
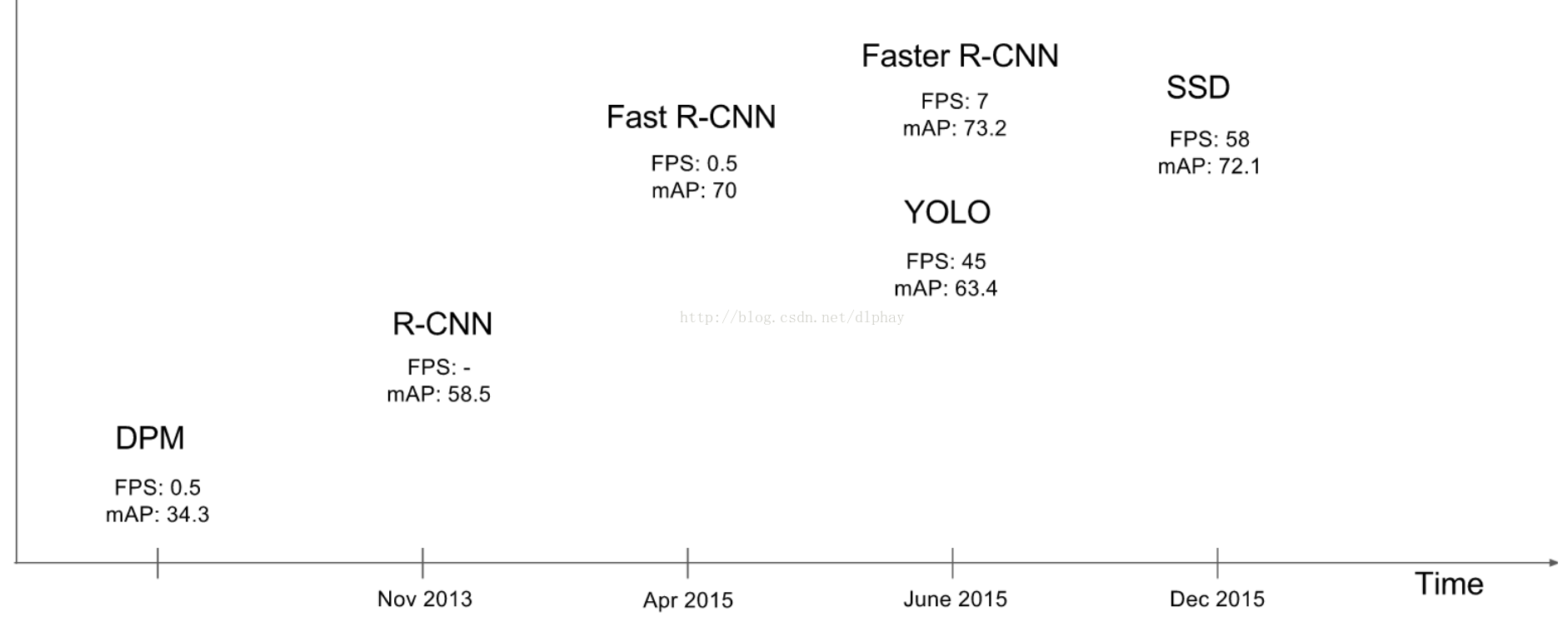
性能评估
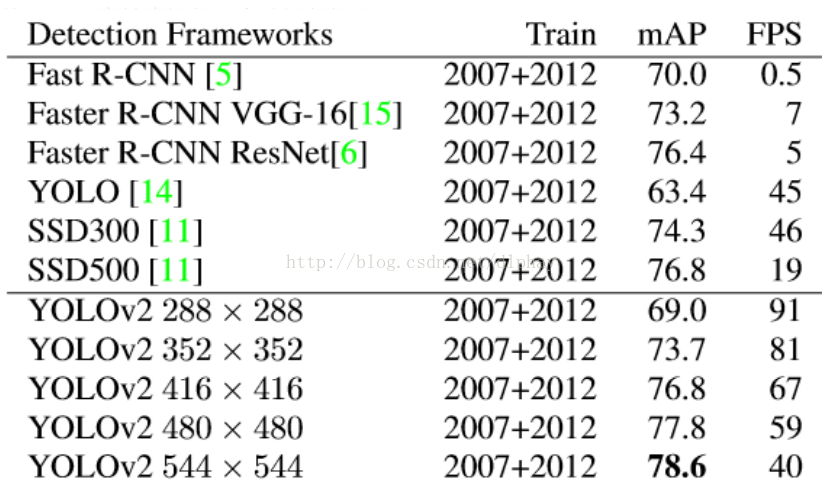
从FPS和mAP(VOC)对比










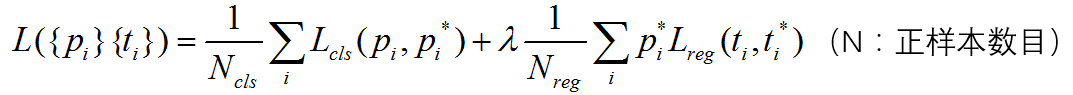















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









