







在ubuntu上通过maven构建mahout项目
经过3天的奋战,终于完成了mahout和eclipse的集合。之前已经用命令行运行过,但具体还是希望能通过IDE结合代码来定制。
m2eclipse
m2eclipse插件和它的安装方法。m2eclipse插件是一款一流的支持Apache Maven的eclipse插件。用户可以用它更方便的编辑Maven的pom.xml文件,可以在IDE上build一个Maven工程。
通过Help -> Install New Software…
Name:m2e
Location:http://download.eclipse.org/technology/m2e/releases
随后的安装都比较简单,安装完后eclipse会提示重启。
import mahout 源码
随后要做的事情比较关键。
通过File - Import,将已经编译过的mahout工程import进来。
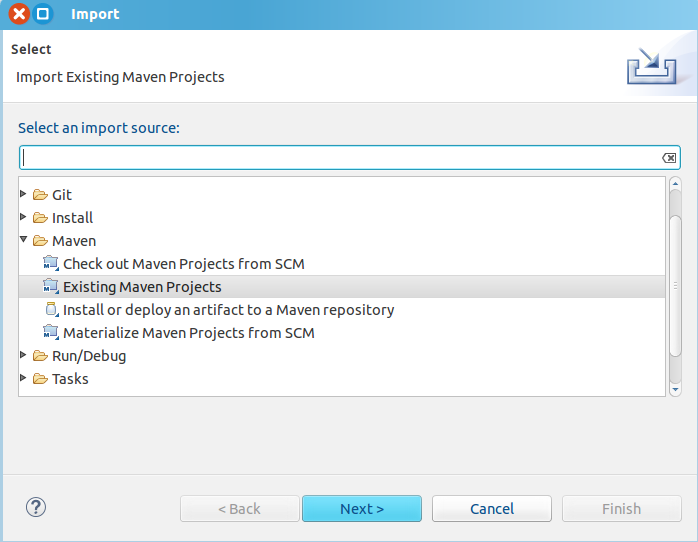
记住选择mahout的根目录,它会自动检索加载各个子目录的maven项目。

简单推荐算法的实现
接下来就可以直接新建一个Maven工程了。
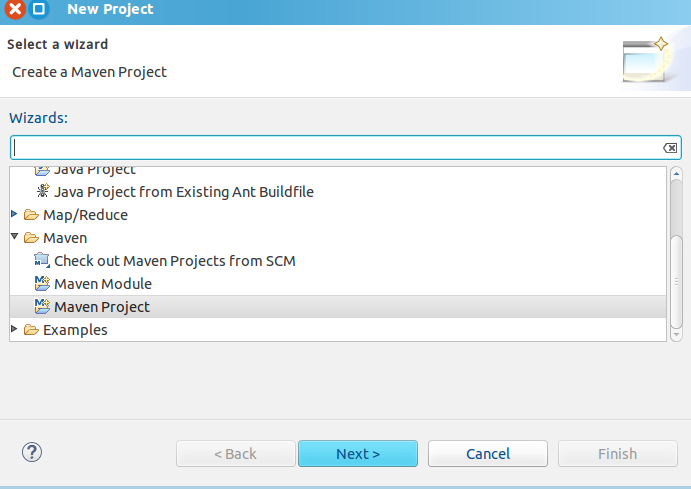
选择一个简单的工程create a simple project
命名,这里我使用了别人windows版本下的截图,其实是一样的

它会自动配置好一个Maven的项目,接下来修改pom.xml
什么是pom?
pom作为项目对象模型。通过xml表示maven项目,使用pom.xml来实现。主要描述了项目:包括配置文件;开发者需要遵循的规则,缺陷管理系统,组织和licenses,项目的url,项目的依赖性,以及其他所有的项目相关因素。
配置pom文件可以通过比较智能的GUI的方式。
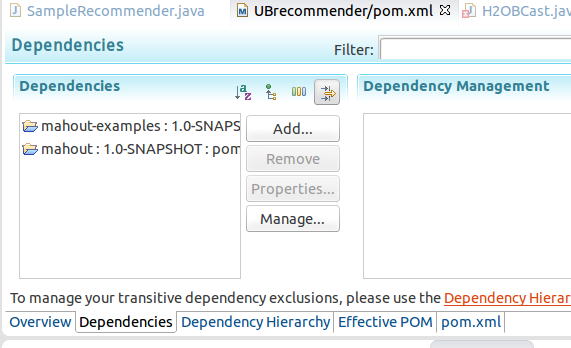
点击Add
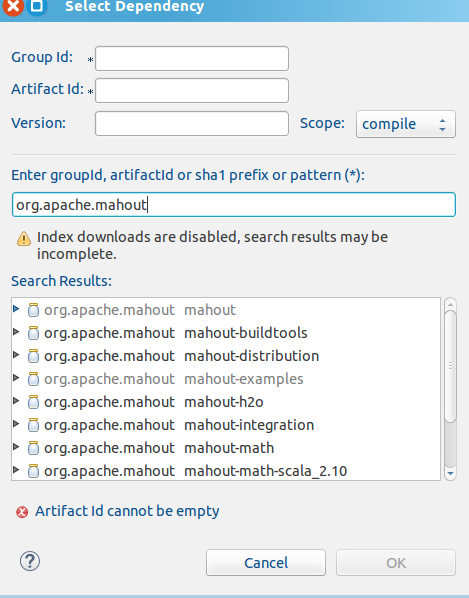
选中第一项org.apache.mahout 添加
接下来添加源代码,在src\main\java\下新建SampleRecommender.java
import java.io.File;
import java.io.IOException;
import org.apache.mahout.cf.taste.impl.model.file.FileDataModel;
import org.apache.mahout.cf.taste.impl.neighborhood.ThresholdUserNeighborhood;
import org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.cf.taste.recommender.UserBasedRecommender;
import org.apache.mahout.cf.taste.similarity.UserSimilarity;
import java.util.List;
public class SampleRecommender
{
public static void main(String[] args) throws IOException, Exception{
DataModel model = new FileDataModel (new File("dataset.csv"));
UserSimilarity similarity = new PearsonCorrelationSimilarity(model);
UserNeighborhood neighborhood = new ThresholdUserNeighborhood(0.1, similarity, model);
UserBasedRecommender recommender = new GenericUserBasedRecommender(model, neighborhood, similarity);
List<RecommendedItem> recommendations = recommender.recommend(2,3);
for (RecommendedItem recommendation : recommendations) {
System.out.println(recommendation);
}
}
}输入的文件命名为Dataset.csv,内容如下
1,10,1.0
1,11,2.0
1,12,5.0
1,13,5.0
1,14,5.0
1,15,4.0
1,16,5.0
1,17,1.0
1,18,5.0
2,10,1.0
2,11,2.0
2,15,5.0
2,16,4.5
2,17,1.0
2,18,5.0
3,11,2.5
3,12,4.5
3,13,4.0
3,14,3.0
3,15,3.5
3,16,4.5
3,17,4.0
3,18,5.0
4,10,5.0
4,11,5.0
4,12,5.0
4,13,0.0
4,14,2.0
4,15,3.0
4,16,1.0
4,17,4.0
4,18,1.0
运行项目,run as java application , 我们便得到推荐结果:
RecommendedItem[item:12, value:4.8328104]
RecommendedItem[item:13, value:4.6656213]
RecommendedItem[item:14, value:4.331242]
这个数据量不适合在mapreduce上运行,但是我们可以测试一下。
参考网址
Mahout – Clustering (聚类篇) 用了kaggle上的数据
http://www.coder4.com/archives/4181
一份比较完整的windows系统下的安装教程,给了我一些启发
http://youngfor.me/post/recsys/apache-mahout-ru-men-pian
maven tutorial: 这个版本有点过时
http://blogs.sourceallies.com/2011/06/maven-3-tutorial-project-setup/3/
mahout in action 的github code
https://github.com/tdunning/MiA















 1333
1333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









