







一个运行在伪分布式上的聚类例子
CSDN终于支持用markdown了,但是还是不支持直接从剪贴版粘贴图片。我决定把自己写的一些笔记搬出来和大家共享。
找到mahout1.0的api文档了:
https://builds.apache.org/job/Mahout-Quality/javadoc/
这样就修复了之前的找不到CLUSTERED_POINTS_DIRECTORY的问题。
在mahout新的版本中将它放在PathDirectory.CLUSTERED_POINTS_DIRECTORY中,同时要导入包:import org.apache.mahout.clustering.topdown.PathDirectory;
在mahout0.7的版本中,Kmeans算法可以通过kmeansClusterer 或KMeansDriver类来运行,但是我在1.0的版本中怎么也找不到前者,
另外,它的参数也发生了改变:
http://blog.csdn.net/fansy1990/article/details/9671977
对比可以看见,没有了measure的参数。
anyway,下面我还是在内存中生成一组数,然后将它们保存在分布式文件系统中,再从中读取进行聚类工作。
package myKmeans;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import org.apache.mahout.clustering.Cluster;
import org.apache.mahout.clustering.topdown.PathDirectory;
import org.apache.mahout.clustering.classify.WeightedPropertyVectorWritable;
import org.apache.mahout.clustering.kmeans.KMeansDriver;
import org.apache.mahout.clustering.kmeans.Kluster;
import org.apache.mahout.common.distance.EuclideanDistanceMeasure;
import org.apache.mahout.math.RandomAccessSparseVector;
import org.apache.mahout.math.Vector;
import org.apache.mahout.math.VectorWritable;
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class KmeansMR{
public static final double[][] points = {
{1, 1}, {2, 1}, {1, 2},
{2, 2}, {3, 3}, {8, 8},
{9, 8}, {8, 9}, {9, 9}};
public static void writePointsToFile(List<Vector> points,
String fileName,
FileSystem fs,
Configuration conf) throws IOException {
Path path = new Path(fileName);
SequenceFile.Writer writer = new SequenceFile.Writer(fs, conf,
path, LongWritable.class, VectorWritable.class);
long recNum = 0;
VectorWritable vec = new VectorWritable();
for (Vector point : points) {
vec.set(point);
writer.append(new LongWritable(recNum++), vec);
}
writer.close();
}
public static List<Vector> getPoints(double[][] raw) {
List<Vector> points = new ArrayList<Vector>();
for (int i = 0; i < raw.length; i++) {
double[] fr = raw[i];
Vector vec = new RandomAccessSparseVector(fr.length);
vec.assign(fr);
points.add(vec);
}
return points;
}
public static void main(String args[]) throws Exception {
int k = 2;
List<Vector> vectors = getPoints(points);
File testData = new File("clustering/testdata");
if (!testData.exists()) {
testData.mkdir();
}
testData = new File("clustering/testdata/points");
if (!testData.exists()) {
testData.mkdir();
}
//注意把配置文件放在java文件夹下可以省很多工作
Configuration conf=new Configuration();
Path input=new Path("clustering/testdata/points");
Path clustersIn=new Path("clustering/testdata/clusters");
Path output =new Path("clustering/output");
FileSystem fs = FileSystem.get(conf);
writePointsToFile(vectors, "clustering/testdata/points/file1", fs, conf);
Path path = new Path("clustering/testdata/clusters/part-00000");
SequenceFile.Writer writer = new SequenceFile.Writer(fs, conf, path, Text.class, Kluster.class);
for (int i = 0; i < k; i++) {
Vector vec = vectors.get(i);
Kluster cluster = new Kluster(vec, i, new EuclideanDistanceMeasure());
writer.append(new Text(cluster.getIdentifier()), cluster);
}
writer.close();
KMeansDriver.run(conf,
input,
clustersIn ,
output,
0.001,
10,
true,
0,
true);
SequenceFile.Reader reader = new SequenceFile.Reader(fs,
new Path(output+"/" + PathDirectory.CLUSTERED_POINTS_DIRECTORY+ "/part-m-0"), conf);
IntWritable key = new IntWritable();
WeightedPropertyVectorWritable value = new WeightedPropertyVectorWritable();
while (reader.next(key, value)) {
System.out.println(value.toString() + " belongs to cluster " + key.toString());
}
reader.close();
}
}如果将配置文件放在Java文件夹下,可以省去很多工作,如果在代码中添加,那么应该写成:
Path input=new Path("hdfs://localhost:9000/user/clustering/testdata/points"); Path clustersIn=new Path("hdfs://localhost:9000/user/clustering/testdata/clusters");
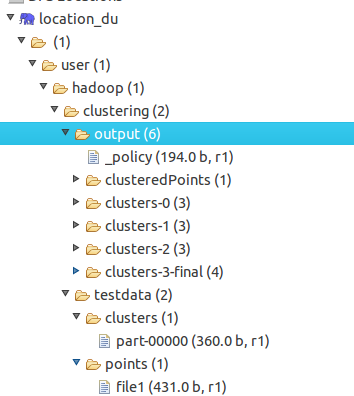
Path output =new Path("hdfs://localhost:9000/user/clustering/output"); 这个是和map-reduce的location配置对应的,运行结果可见:














 450
450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









