







本文首发于微信公众号:计算机视觉life
前面的文章分别介绍了三种深度相机的原理:TOF、RGB双目、结构光。看起来它们都各有利弊,那么在实际产品研发中如何选择深度相机呢?
为了读者能够有个清晰的思路,我
脑补
了苹果公司CEO蒂姆·库克(Tim Cook)和我的一段对话,我们就iPhone X如何选择深度相机深入交换了意见。

以下对话内容纯属虚构,如有雷同,肯定是抄我的。
--------------------------------------------------------------------------------------------------
Cook:Hi,sixgod,how are you?
Sixgod:I am fine. Thank you! And you?
Cook:I am fine, too.
我:我英语库存已经耗尽了。。。接不下去了。。。我们还是用中文吧!
库克:木问题!我最近在考虑一款新手机iPhone X,想要增加深度相机,我看了你公众号介绍的三种深度相机,写的不错,然而看完了我还是不知道该怎么选,你有什么建议吗?
我:谢谢!我最近正好想写一下,如何根据自身产品的需求选择合适的深度相机技术方案。简单来说,这三种深度相机没有最好,只有最合适。首先,这款用在手机上的深度相机,你打算放前置还是后置?
库克:前置。因为我们的深度相机主要是对人脸进行三维建模,然后在此基础上增加三维人脸识别来解锁手机,后面还有更多基于三维人脸的有趣应用。
我:要进行三维人脸识别,那看来使用距离很近了。另外,对深度相机的测量精度要求也很高啊!
库克:是啊,这次我们就是主打三维人脸解锁,要做就要做到最牛X,不然不好意思拿出手啊!
我:明白!那这么说,是不是也要随时随地人脸解锁了?不论室内室外,白天夜晚,效果都要杠杠的?
库克:那是必须,如果人脸解锁还要看环境条件,那消费者肯定不会买账的!三维人脸解锁本来就是要方便的啊,我们的目标是比指纹解锁还要方便快捷!
我:Got it!那我们现在可以先排除掉RGB的双目相机了。
库克:啊!这么快就排除一个了?那你得告诉我为啥要排除掉RGB双目方案。
我:RGB双目相机因为非常依赖纯图像特征匹配,所以在光照较暗或者过度曝光的情况下效果都非常差,另外如果被测场景本身缺乏纹理,也很难进行特征提取和匹配。你看看下面的图就懂了。

库克:嗯,这个点明白了。我们继续讨论吧。
我:我:别急,看下面的表格,我列出了对比结果。

库克:嗯,知道了。我们手机必须全天候实现三维人脸识别,RGB双目方案做不到,不考虑了。那还有两种呢,怎么选?
我:下面可以从分辨率、帧率、软件复杂度、功耗等方面来考虑吧。毕竟我们要用在移动设备上。
库克:OK。我们计划推出基于人脸的很多实用有趣的应用,比如人脸表情,人像光照,背景虚化等。攻城狮们正在努力加班中。后期可能还会推出AR相关的应用。所以对深度图分辨率还是有较高的要求的。
我:啊?你们也加班啊。。。关于分辨率,TOF方案深度图分辨率很难提高,一般都达不到VGA(640x480)分辨率。比如Kinect2的TOF方案深度图分辨率只有512x424。而Google和联想合作的PHAB2手机的后置TOF深度相机分辨率只有224x171。TOF方案受物理器件的限制,分辨率很难做到接近VGA的,即使做到,也会和功耗呈指数倍增长。
库克:那结构光的分辨率呢?
我:在较近使用范围内,结构光方案的分辨率会大大高于TOF方案。比如目前结构光方案的深度图最高可以做到1080p左右的分辨率了。
库克:嗯,这个分辨率够用了。那帧率和软件复杂度呢?我们要实现实时的应用,这点也很重要!
我:帧率的话,TOF方案可以达到非常高的帧率,差不多上百fps吧。结构光方案帧率会低点,典型的是30fps,不过这也基本够用了。软件复杂度方面,结构光因为需要对编码的结构光进行解码,所以复杂度要比直接测距的TOF高一些。
库克:嗯,看起来,帧率和软件复杂度方面TOF更有优势,不过差别对我们的需求影响不太明显,我们无所不能的算法工程师应该可以搞定。那功率呢?三维人脸解锁使用频率很高,功率是一个非常重要的考虑因素。
我:确实是啊,我之前用的iphone5s每天都得充电,出远门都得自带充电宝,心累啊。
库克:额。。。
我:扯远了啊。功耗的话TOF是激光全面照射,而结构光是只照射其中局部区域,比如PrimeSense的伪随机散斑图案,只覆盖了不到十分之一的空间。另外,TOF发射的是高频调制脉冲,而结构光投射图案并不需要高频调制,所以结构光的功耗要比TOF低很多。还是以伪随机散斑结构光为例,结构光方案功耗只有TOF的十分之一不到吧。
库克:Amazing! 有没有具体的对比表格?
我:有有有。下面是三种方案在分辨率,帧率,软件复杂度和功耗方面的对比结果。
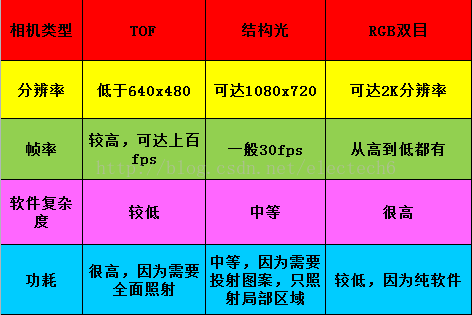
库克:嗯,看来我只能选择结构光方案了。其实,结构光方案还有一个优势在于技术成熟,我们收购的PrimeSense很早就把结构光技术用在kinect一代产品中了。既然技术这么成熟,想必结构光技术也有很多变种吧。
我:没错!目前结构光技术有如下几种:一种是单目IR+投影红外点阵,另外一种是双目IR+投影红外点阵,这样相当于结构光+双目立体融合了,深度测量效果会比前者好一些,比如Intel RealSense R200采用的就是双目IR+投影红外点阵,不足之处就是体积较大。而单目IR+投影红外点阵的方案虽然体积较小,但是效果会差一点。
库克:等下,体积是重点考虑因素啊!手机上空间本身就非常有限,消费者现在对全面屏也非常着迷。看来只能选择单目IR+投影红外点阵的方案了。我们前置深度相机的空间非常狭小,即使这样设计出来,看起来很可能像是女生的齐刘海。
我:那挺萌的啊!
库克:额。。。你继续说说计算复杂度。
我:嗯,计算方式也分几种:一是直接用ASIC(专用集成电路)进行计算,成本稍微高一点,但是处理速度快,支持高帧率和高分辨率深度相机,关键是比通用芯片功耗低。二是DSP+软件算法,成本跟用ASIC差不多,但支持不了高帧率高分辨率,功耗比ASIC稍高。三是直接用手机的AP(Application Processor)进行纯软件计算,这个不需要额外增加硬件成本,但是比较消耗AP的计算资源。同样也不支持高帧率高分辨率,功耗比较大。

库克:低功耗,计算速度快,高帧率高分辨率,嗯,ASIC方案比较适合iPhone X。
我:那您总结一下最后iPhone X的深度相机技术方案?
库克:嗯。我们最终选择方案是:结构光原理的深度相机。具体来说是:单目IR+投影红外点阵+ASIC方案。该方案在深度分辨率、深度测量精度上有较大优势,实时性处理和全天候工作也都有保障,功耗也相对较低,就是成本稍高了一些。
我:额,这么说,iPhone X的定价会比较高了?
库克:还好吧,不过是几杯咖啡的钱。
--------------------------------------------------------------------------------------------------------
我猛地从梦中惊醒,出了一身冷汗。手里攥着还没来得及泡的泡面,已被我捏的咔咔作响,那分明是心脏被震碎一地声音。我掐指算了算,嗯,只要再坚持吃半年泡面,我就能攒够买iPhone X的钱了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









