







背景
上次讲解代码以后,把rag这块遗留了下来,rag的代码相对来说比较复杂,一环套一环。我们今天先来拆解下分片的整体流程。
整体分为3个阶段
- 切片设置
- 启动任务
- 异步消费
我们挨个来解析下。
切片设置
查找接口

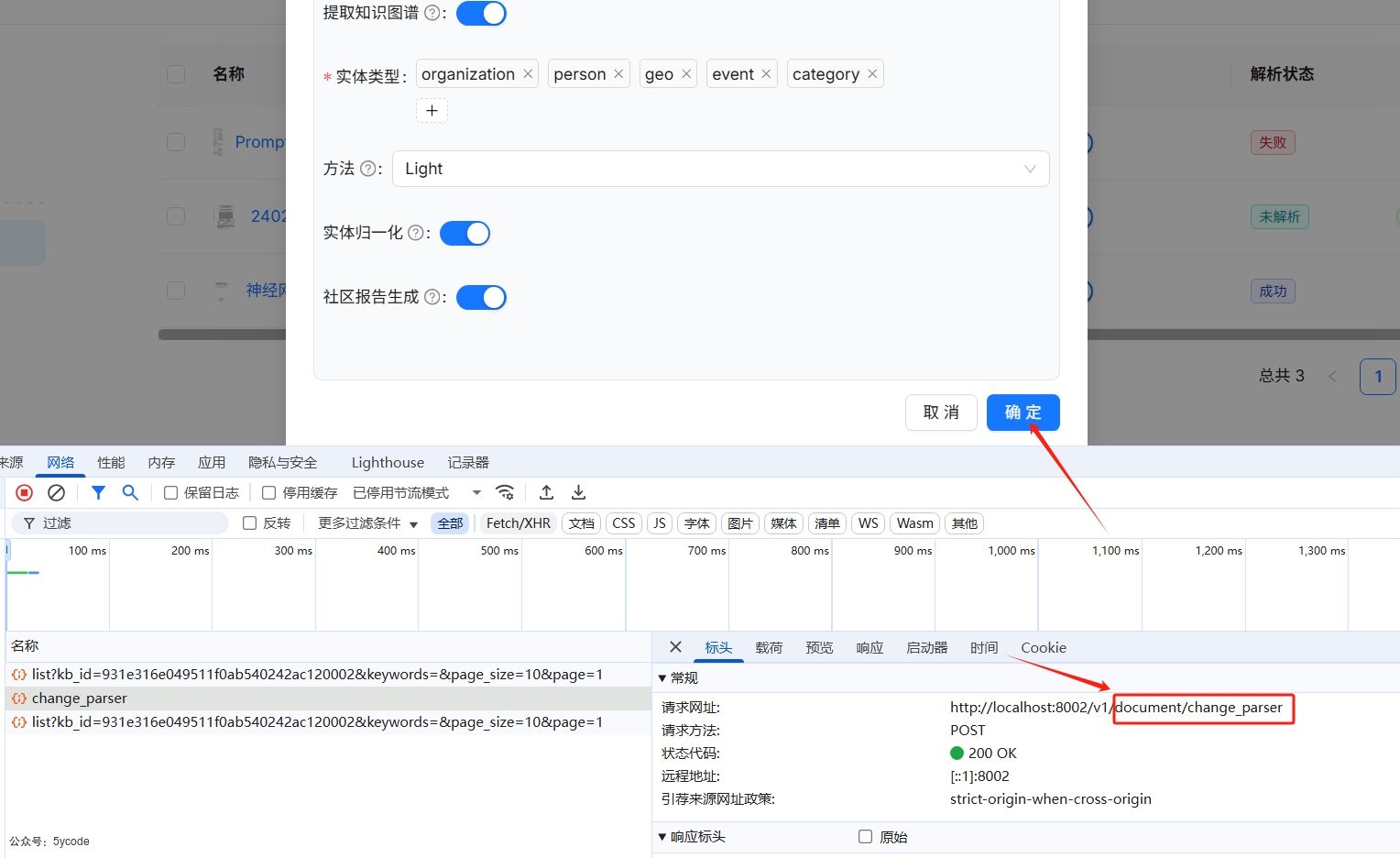
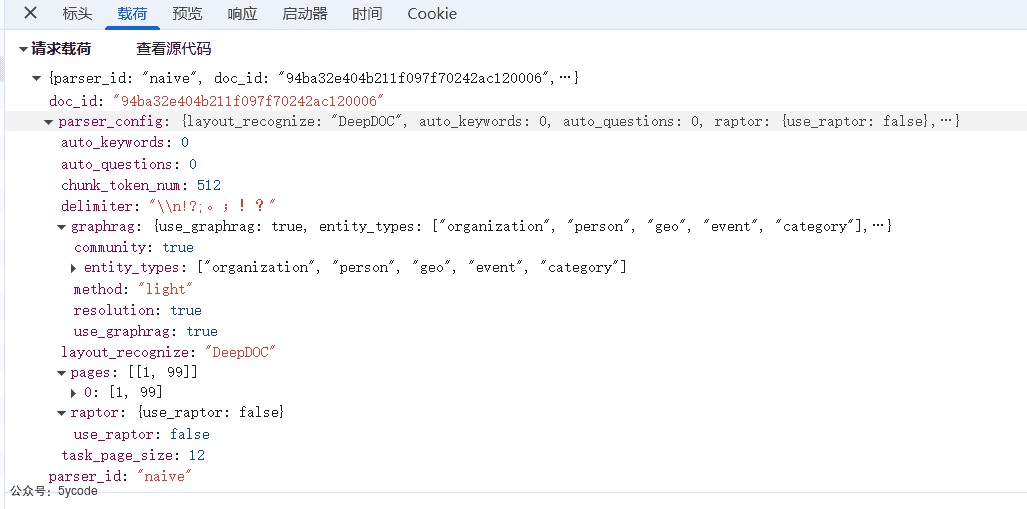
我们从接口的请求参数和界面对照,大致了解下
doc_id文档idparser_config文档解析配置task_page_size任务页面大小layout_recognize使用哪种解析器,默认用的DeepDOCchunk_token_num块token数delimiter分段标识符auto_keywords自动关键词抽取auto_questions自动问题抽取raptor:召回增强RAPTOR策略use_raptor: 是否开启
use_raptor使用召回增强RAPTOR策略graphrag: 知识图谱配置use_graphrag是否使用知识图谱entity_types实体类型method知识图谱方法community实体归一化use_graphrag社区报告
代码
我们按照上一篇解剖RAGFlow!全网最硬核源码架构解析讲的,找到documnet_app.py文件,搜索change_parser方法。
@manager.route('/change_parser', methods=['POST']) # noqa: F821
@login_required
@validate_request("doc_id", "parser_id")
def change_parser():
req = request.json
#权限校验,看下你有没有操作的权限
if not DocumentService.accessible(req["doc_id"], current_user.id):
try:
# 解析器切换验证,
e, doc = DocumentService.get_by_id(req["doc_id"])
if ((doc.type == FileType.VISUAL and req["parser_id"] != "picture")
or (re.search(
r"\.(ppt|pptx|pages)$", doc.name) and req["parser_id"] != "presentation")):
return get_data_error_result(message="Not supported yet!")
e = DocumentService.update_by_id(doc.id,
{"parser_id": req["parser_id"], "progress": 0, "progress_msg": "",
"run": TaskStatus.UNSTART.value})
if not e:
return get_data_error_result(message="Document not found!")
if "parser_config" in req:
DocumentService.update_parser_config(doc.id, req["parser_config"])
if doc.token_num > 0:
e = DocumentService.increment_chunk_num(doc.id, doc.kb_id, doc.token_num * -1, doc.chunk_num * -1,
doc.process_duation * -1)
if not e:
return get_data_error_result(message="Document not found!")
tenant_id = DocumentService.get_tenant_id(req["doc_id"])
if not tenant_id:
return get_data_error_result(message="Tenant not found!")
if settings.docStoreConn.indexExist(search.index_name(tenant_id), doc.kb_id):
settings.docStoreConn.delete({"doc_id": doc.id}, search.index_name(tenant_id), doc.kb_id)
return get_json_result(data=True)
except Exception as e:
return server_error_response(e)
这段代码
- 权限校验,看下你有没有操作的权限
- 解析器切换验证
- 视觉文件(FileType.VISUAL)只能使用"picture"解析器
- PPT类文件只能使用"presentation"解析器
- 更新文档的状态为
未启动 - 重置文档统计信息(token_num/chunk_num清零)
- 删除关联的搜索索引数据
这里只是把切片的配置做了设置。整体流程如下:
启动
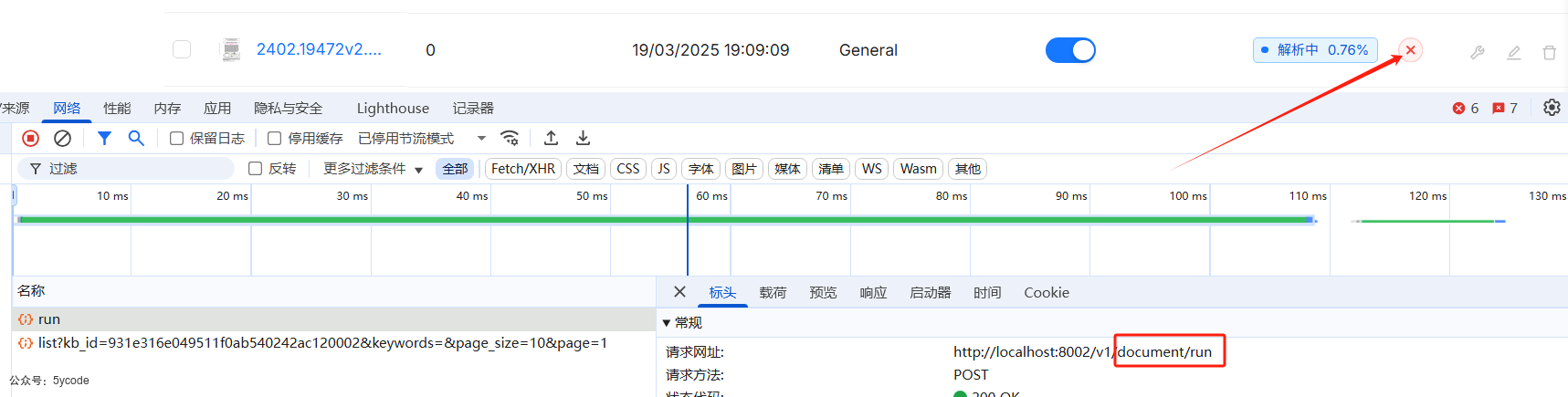
点击文档后面的启动按钮。可以看到调用的具体接口
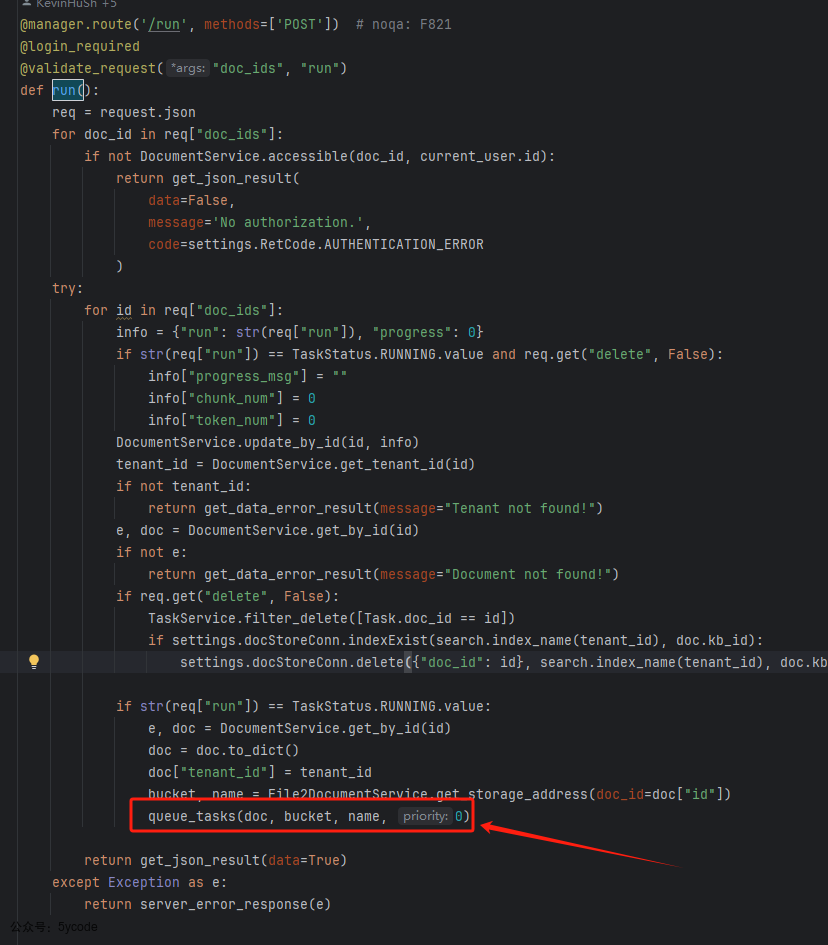
重点是这个方法,在api/db/services/task_service.py中
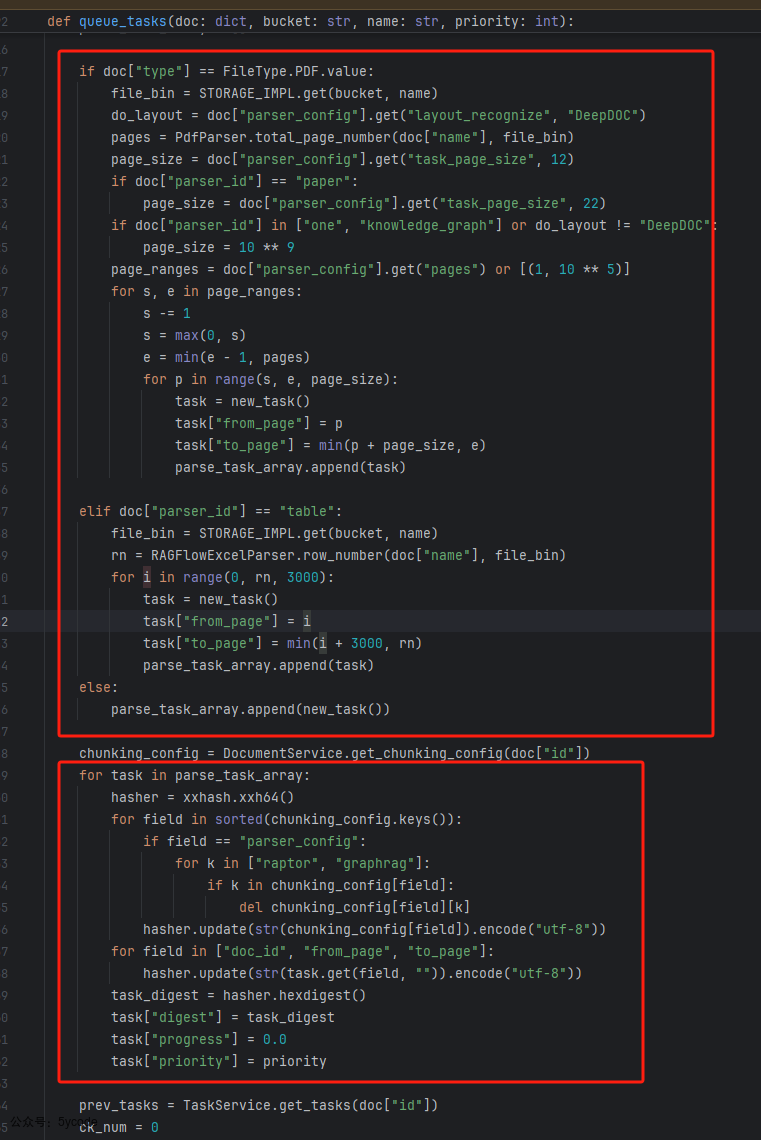
- 第一段代码在进行任务分割,不通类型的文档最后分割策略一样
- 默认每任务处理12页
- 学术论文 22页
- 单任务处理全部
- Excel每任务处理3000行
- 第二段代码是生成任务,包括:唯一task_digest 和初始进度,优先
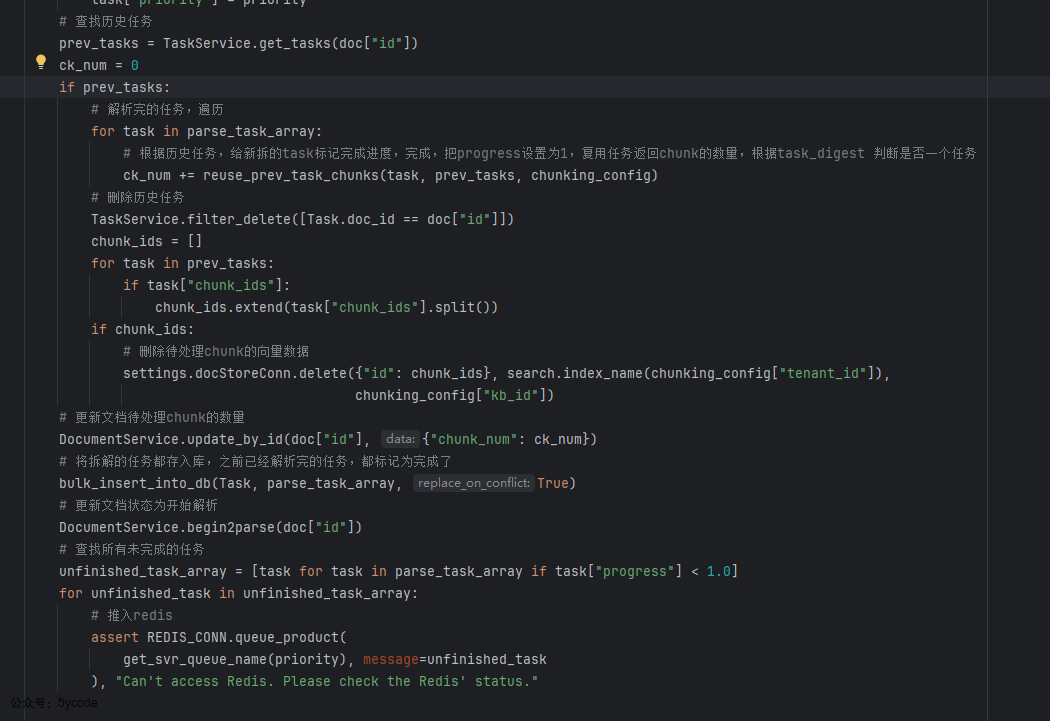
在这里我们要了解一个概念,一个task,会拆出多个chuck。使用的是redis的消息队列,根据优先级使用不同的队列名称,默认用rag_flow_svr_queue。这段代码看图片里的注释吧。
最后这块的整体流程如下:
任务消费与处理
在rag/svr/task_executor.py中
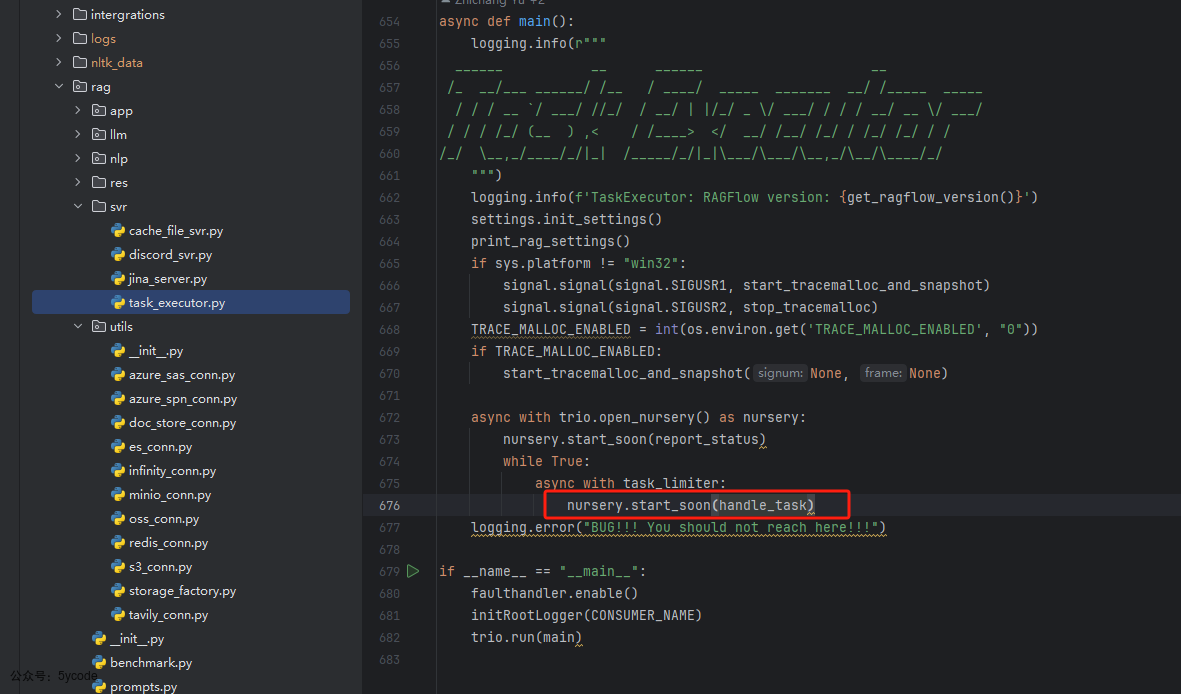
任务执行器启动以后,死循环执行
async def handle_task():
#通过redis消息队列从`rag_flow_svr_queue`获取任务
redis_msg, task = await collect()
if not task:
# 没有获取到,休眠5秒
await trio.sleep(5)
return
try:
# 状态记录
CURRENT_TASKS[task["id"]] = copy.deepcopy(task)
# 核心处理
await do_handle_task(task)
# 成功处理
DONE_TASKS += 1
except Exception as e:
# 异常处理
FAILED_TASKS += 1
set_progress(task_id, -1, str(e))
我们接着看do_handle_task 方法,
# 绑定进度回调
progress_callback = partial(set_progress, task_id, ...)
# 任务状态检查
if TaskService.do_cancel(task_id):
# 主动取消
progress_callback(-1, "Task canceled")
return
我们看下默认分片中的关键方法
# 分片,这个是核心
chunks = await build_chunks(task, progress_callback)
# 所有的分片向量化,并向量结果写入到每个chunk的["q_%d_vec" % len(v)] = v
token_count, vector_size = await embedding(chunks, embedding_model, task_parser_config, progress_callback)
简单看下build_chunks方法
async with chunk_limiter:
cks = await trio.to_thread.run_sync(lambda: chunker.chunk(task["name"], binary=binary, from_page=task["from_page"],
to_page=task["to_page"], lang=task["language"], callback=progress_callback,
kb_id=task["kb_id"], parser_config=task["parser_config"], tenant_id=task["tenant_id"]))
最后到了rag/app/naive.py 文件中的chunk方法。在这个方法里根据切片配置进行了处理。整体流程如下:
在最新的版本中,使用视觉模型,对图表进行增强。该代码还有发布。
整个异步处理如下:
后记
通过最近的源码解析,ragflow后面的升级有几块
agent添加了版本,最多保留20个版本agent增加团队权限功能- 复杂结构,通过视觉模型增强图表功能
相关资料
deepseek相关资料
https://pan.quark.cn/s/faa9d30fc2bd
https://pan.baidu.com/s/10vnv9jJJCG-KKY8f_e-wLw?pwd=jxxv
群友分享的一些dify工作流
https://pan.baidu.com/s/1aNne8dLz6YxoKhCwJclV5g?pwd=p4xc
https://pan.quark.cn/s/243a0de062e5
系列文档:
DeepSeek本地部署相关
ollama+deepseek本地部署
局域网或断网环境下安装DeepSeek
vlllm部署deepseek基准测试
DeepSeek个人应用
不要浪费deepseek的算力了,DeepSeek提示词库指南
服务器繁忙,电脑配置太低,别急deepseek满血版来了
DeepSeek+本地知识库:真的太香了(修订版)
DeepSeek+本地知识库:真是太香了(企业方案)
deepseek一键生成小红书爆款内容,排版下载全自动!睡后收入不是梦
最轻量级的deepseek应用,支持联网和知识库
当我把公众号作为知识库塞进了智能体后
个人神级知识库DeepSeek+ima 个人学习神器
dify相关
DeepSeek+dify 本地知识库:真的太香了
Deepseek+Dify本地知识库相关问题汇总
dify的sandbox机制,安全隔离限制
DeepSeek+dify 本地知识库:高级应用Agent+工作流
DeepSeek+dify知识库,查询数据库的两种方式(api+直连)
DeepSeek+dify 工作流应用,自然语言查询数据库信息并展示
聊聊dify权限验证的三种方案及实现
dify1.0.0版本升级及新功能预览
Dify 1.1.0史诗级更新!新增"灵魂功能"元数据,实测竟藏致命Bug?手把手教你避坑
【避坑血泪史】80次调试!我用Dify爬虫搭建个人知识库全记录
手撕Dify1.x插件报错!从配置到网络到Pip镜像,一条龙排雷实录
dify1.2.0升级,全新循环节点优化,长文写作案例
dify1.x无网环境安装插件
ragflow相关
DeepSeek+ragflow构建企业知识库:突然觉的dify不香了(1)
DeepSeek+ragflow构建企业知识库之工作流,突然觉的dify又香了
DeepSeek+ragflow构建企业知识库:高级应用篇,越折腾越觉得ragflow好玩
RAGFlow爬虫组件使用及ragflow vs dify 组件设计对比
从8550秒到608秒!RAGFlow最新版本让知识图谱生成效率狂飙,终于不用通宵等结果了
以为发现的ragflow的宝藏接口,其实是一个天坑、Chrome/Selenium版本地狱
NLTK三重降噪内幕!RAGFlow检索强悍竟是靠这三板斧
从代码逆向RAGFlow架构:藏在18张表里的AI知识库设计哲学
解剖RAGFlow!全网最硬核源码架构解析
扣子(coze)
AI开发新选择:扣子平台功能详解与智能体拆解
AI开发新选择:扣子平台工作流基础节点介绍
模型微调相关
📢【三连好运 福利拉满】📢
🌟 若本日推送有收获:
👍 点赞 → 小手一抖,bug没有
📌 在看 → 一点扩散,知识璀璨
📥 收藏 → 代码永驻,防止迷路
📤 分享 → 传递战友,功德+999
🔔 关注 → 关注5ycode,追更不迷路,干货永同步
💬 若有槽点想输出:
👉 评论区已铺好红毯,等你来战!


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









