







原文链接:http://blog.csdn.net/dream_angel_z/article/details/50867951
1.引言
分类算法有很多,不同分类算法又用很多不同的变种。不同的分类算法有不同的特定,在不同的数据集上表现的效果也不同,我们需要根据特定的任务进行算法的选择,如何选择分类,如何评价一个分类算法的好坏,正确率确实是一个很好很直观的评价指标,但是有时候正确率高并不能代表一个算法就好。比如某个地区某天地震的预测,假设我们有一堆的特征作为地震分类的属性,类别只有两个:0:不发生地震、1:发生地震。一个不加思考的分类器,对每一个测试用例都将类别划分为0,那那么它就可能达到99%的正确率,但真的地震来临时,这个分类器毫无察觉,这个分类带来的损失是巨大的。为什么99%的正确率的分类器却不是我们想要的,因为这里数据分布不均衡,类别1的数据太少,完全错分类别1依然可以达到很高的正确率却忽视了我们关注的东西。接下来详细介绍一下分类算法的评价指标。2.评价指标
(1)几个常用的术语这里首先介绍几个常见的模型评价术语,现在假设我们的分类目标只有两类,计为正例(positive)和负例(negtive)分别是:
a.True positives(TP): 被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数(样本数);
b.False positives(FP): 被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数;
c.False negatives(FN):被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数;
d.True negatives(TN): 被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数。
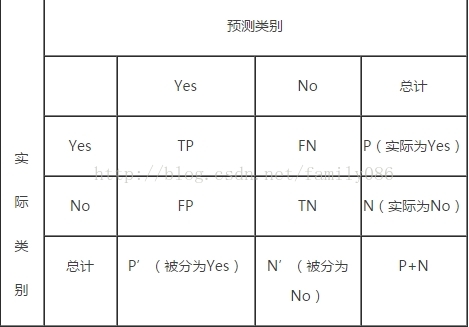
图是这四个术语的混淆矩阵,我只知道FP叫伪阳率,其他的怎么称呼就不详了。注意P=TP+FN表示实际为正例的样本个数,我曾经误以为实际为正例的样本数应该为TP+FP,这里只要记住True、False描述的是分类器是否判断正确,Positive、Negative是分类器的分类结果。如果正例计为1、负例计为-1,即positive=1、negtive=-1,用1表示True,-1表示False,那么实际的类标=TF*PN,TF为true或false,PN为positive或negtive。例如True positives(TP)的实际类标=1*1=1为正例,False positives(FP)的实际类标=(-1)*1=-1为负例,False negatives(FN)的实际类标=(-1)*(-1)=1为正例,True negatives(TN)的实际类标=1*(-1)=-1为负例。
(2)评价指标
a.正确率(accuracy)
正确率是我们最常见的评价指标,accuracy = (TP+TN)/(P+N),这个很容易理解,就是被分对的样本数除以所有的样本数,通常来说,正确率越高,分类器越好;
b.错误率(error rate)
错误率则与正确率相反,描述被分类器错分的比例,error_rate = (FP+FN)/(P+N),对某一个实例来说,分对与分错是互斥事件,所以accuracy =1 - error rate;
c.灵敏度(sensitive)
sensitive = TP/P,表示的是所有正例中被分对的比例,衡量了分类器对正例的识别能力;
d.特效度(specificity)
specificity = TN/N,表示的是所有负例中被分对的比例,衡量了分类器对负例的识别能力;
e.精度(precision)
精度是精确性的度量,表示被分为正例的示例中实际为正例的比例,precision=TP/(TP+FP);
f.召回率(recall)
召回率是覆盖面的度量,度量有多个正例被分为正例,recall=TP/(TP+FN)=TP/P=sensitive,可以看到召回率与灵敏度是一样的。
g.F1_SCORE = 2*recall*precision/(recall+precision)
实际当中,我们往往希望得到的precision和recall都比较高,比如当FN和FP等于0的时候,他们的值都等于1。但是,它们往往在某种情况下是互斥的,比如这种情况,50个正样本,50个负样本,结果全部预测为正,那么它的precision为1而recall却为0.5.所以需要一种折衷的方式,因此就有了F1-score。
h.ROC曲线
ROC(receiver operating characteristic),平面的横坐标是false positive rate(FPR)假阳率,纵坐标是true positive rate(TPR)真阳率。ROC计算过程如下:
首先每个样本都需要有一个label值,并且还需要一个预测的score值(取值0到1);
然后按这个score对样本由大到小进行排序,假设这些数据位于表格中的一列,从上到下依次降序;
现在从上到下按照样本点的取值进行划分,位于分界点上面的我们把它归为预测为正样本,位于分界点下面的归为负样本;
分别计算出此时的TPR(Recall)=TP/P和FPR(1-SP)=FP/N,然后在图中绘制(FPR, TPR)点。
从上往下逐个样本计算,最后会得到一条光滑的曲线。
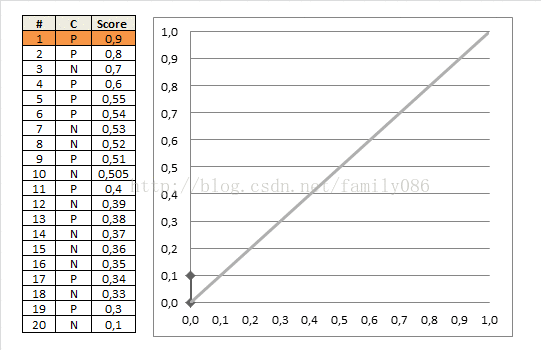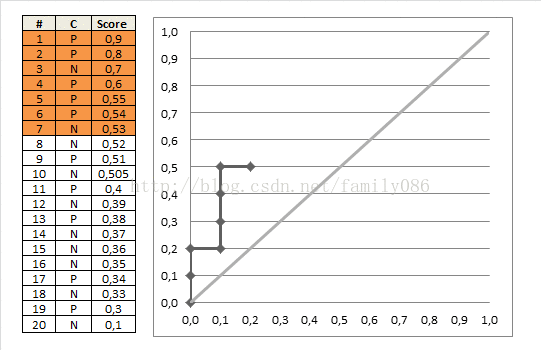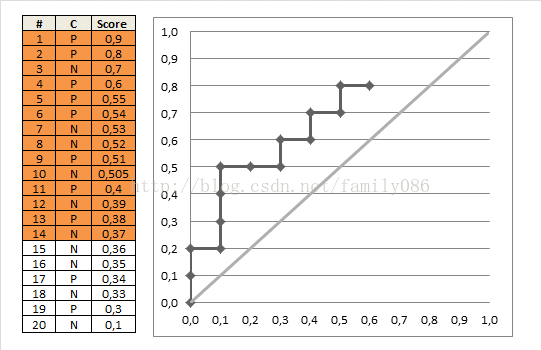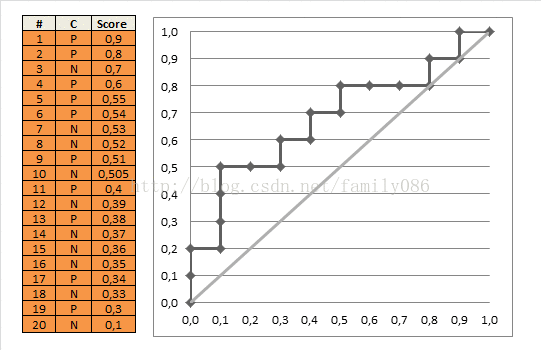
i.AUC
AUC(area under the curve)就是ROC曲线下方的面积,取值在0.5到1之间,因为随机猜测得到额AUC就是0.5。面积如下图所示,阴影部分即为AUC面积。















 3440
3440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









