







逻辑回归(Logistic Regression):该模型用于分类而非回归,可以使用logistic sigmoid函数( 可参考:http://blog.csdn.net/fengbingchun/article/details/73848734 )将线性函数的输出压缩进区间(0,1):
p(y=1| x;θ)=σ(θTx).
逻辑回归是一种广义的线性回归分析(可参考: http://blog.csdn.net/fengbingchun/article/details/77892193 )模型,因此与多重线性回归分析有很多相同之处。它们的模型形式基本上相同,都具有w’x+b,其中w和b是待求参数,其区别在于它们的因变量不同,多重线性回归直接将w’x+b作为因变量,即y=w’x+b,而逻辑回归则通过函数L将w’x+b对应一个隐状态p, p=L(w’x+b),然后根据p与1-p的大小决定因变量的值。如果L是logistic函数,就是logistic回归,如果L是多项式函数就是多项式回归。
Logistic回归的因变量可以是二分类的,也可以是多分类的。多类可以使用softmax方法(可参考 http://blog.csdn.net/fengbingchun/article/details/75220591 )进行处理。
优化逻辑回归的方法包括:梯度下降法、牛顿法、BFGS。优化的主要目标是找到一个方向,参数朝这个方向移动之后使得似然函数的值能够减少,这个方向往往由一阶偏导或者二阶偏导各种组合求得。这几种方法一般都是采用迭代的方式来逐步逼近极小值。
Logistic回归类似于线性回归模型,但更适用于因变量为二分变量的模型。逻辑回归中预测函数用到了逻辑函数即sigmoid函数(逻辑回归拟合函数)。逻辑回归中的损失函数(cost function)是基于最大似然估计推导的。
逻辑回归中的过拟合:对于逻辑回归或线性回归的损失函数构成的模型,可能会有些权重很大,有些权重很小,导致过拟合,使得模型的复杂度提高,泛化能力较差。一般多用正则化的方法来解决过拟合。
以下是参考OpenCV3.3中LogisticRegression类实现的二分类逻辑回归code:包括训练方法包括Batch和Mini Batch,并支持简单的正则化方法,实现code如下:
logistic_regression.hpp:
#ifndef FBC_NN_LOGISTICREGRESSION_HPP_
#define FBC_NN_LOGISTICREGRESSION_HPP_
#include <string>
#include <memory>
#include <vector>
namespace ANN {
template<typename T>
class LogisticRegression { // two categories
public:
LogisticRegression() = default;
int init(const T* data, const T* labels, int train_num, int feature_length,
int reg_kinds = -1, T learning_rate = 0.00001, int iterations = 10000, int train_method = 0, int mini_batch_size = 1);
int train(const std::string& model);
int load_model(const std::string& model);
T predict(const T* data, int feature_length) const; // y = 1/(1+exp(-(wx+b)))
// Regularization kinds
enum RegKinds {
REG_DISABLE = -1, // Regularization disabled
REG_L1 = 0 // L1 norm
};
// Training methods
enum Methods {
BATCH = 0,
MINI_BATCH = 1
};
private:
int store_model(const std::string& model) const;
T calc_sigmoid(T x) const; // y = 1/(1+exp(-x))
T norm(const std::vector<T>& v1, const std::vector<T>& v2) const;
void batch_gradient_descent();
void mini_batch_gradient_descent();
void gradient_descent(const std::vector<std::vector<T>>& data_batch, const std::vector<T>& labels_batch, int length_batch);
std::vector<std::vector<T>> data;
std::vector<T> labels;
int iterations = 1000;
int train_num = 0; // train samples num
int feature_length = 0;
T learning_rate = 0.00001;
std::vector<T> thetas; // coefficient
//T epsilon = 0.000001; // termination condition
T lambda = (T)0.; // regularization method
int train_method = 0;
int mini_batch_size = 1;
};
} // namespace ANN
#endif // FBC_NN_LOGISTICREGRESSION_HPP_#include "logistic_regression.hpp"
#include <fstream>
#include <algorithm>
#include <functional>
#include <numeric>
#include "common.hpp"
namespace ANN {
template<typename T>
int LogisticRegression<T>::init(const T* data, const T* labels, int train_num, int feature_length,
int reg_kinds, T learning_rate, int iterations, int train_method, int mini_batch_size)
{
if (train_num < 2) {
fprintf(stderr, "logistic regression train samples num is too little: %d\n", train_num);
return -1;
}
if (learning_rate <= 0) {
fprintf(stderr, "learning rate must be greater 0: %f\n", learning_rate);
return -1;
}
if (iterations <= 0) {
fprintf(stderr, "number of iterations cannot be zero or a negative number: %d\n", iterations);
return -1;
}
CHECK(reg_kinds == -1 || reg_kinds == 0);
CHECK(train_method == 0 || train_method == 1);
CHECK(mini_batch_size >= 1 && mini_batch_size < train_num);
if (reg_kinds == REG_L1) this->lambda = (T)1.;
if (train_method == MINI_BATCH) this->train_method = 1;
this->mini_batch_size = mini_batch_size;
this->learning_rate = learning_rate;
this->iterations = iterations;
this->train_num = train_num;
this->feature_length = feature_length;
this->data.resize(train_num);
this->labels.resize(train_num);
for (int i = 0; i < train_num; ++i) {
const T* p = data + i * feature_length;
this->data[i].resize(feature_length+1);
this->data[i][0] = (T)1; // bias
for (int j = 0; j < feature_length; ++j) {
this->data[i][j+1] = p[j];
}
this->labels[i] = labels[i];
}
this->thetas.resize(feature_length + 1, (T)0.); // bias + feature_length
return 0;
}
template<typename T>
int LogisticRegression<T>::train(const std::string& model)
{
CHECK(data.size() == labels.size());
if (train_method == BATCH) batch_gradient_descent();
else mini_batch_gradient_descent();
CHECK(store_model(model) == 0);
return 0;
}
template<typename T>
void LogisticRegression<T>::batch_gradient_descent()
{
for (int i = 0; i < iterations; ++i) {
gradient_descent(data, labels, train_num);
/*std::unique_ptr<T[]> z(new T[train_num]), gradient(new T[thetas.size()]);
for (int j = 0; j < train_num; ++j) {
z.get()[j] = (T)0.;
for (int t = 0; t < feature_length + 1; ++t) {
z.get()[j] += data[j][t] * thetas[t];
}
}
std::unique_ptr<T[]> pcal_a(new T[train_num]), pcal_b(new T[train_num]), pcal_ab(new T[train_num]);
for (int j = 0; j < train_num; ++j) {
pcal_a.get()[j] = calc_sigmoid(z.get()[j]) - labels[j];
pcal_b.get()[j] = data[j][0]; // bias
pcal_ab.get()[j] = pcal_a.get()[j] * pcal_b.get()[j];
}
gradient.get()[0] = ((T)1. / train_num) * std::accumulate(pcal_ab.get(), pcal_ab.get() + train_num, (T)0.); // bias
for (int j = 1; j < thetas.size(); ++j) {
for (int t = 0; t < train_num; ++t) {
pcal_b.get()[t] = data[t][j];
pcal_ab.get()[t] = pcal_a.get()[t] * pcal_b.get()[t];
}
gradient.get()[j] = ((T)1. / train_num) * std::accumulate(pcal_ab.get(), pcal_ab.get() + train_num, (T)0.) +
(lambda / train_num) * thetas[j];
}
for (int i = 0; i < thetas.size(); ++i) {
thetas[i] = thetas[i] - learning_rate / train_num * gradient.get()[i];
}*/
}
}
template<typename T>
void LogisticRegression<T>::mini_batch_gradient_descent()
{
const int step = mini_batch_size;
const int iter_batch = (train_num + step - 1) / step;
for (int i = 0; i < iterations; ++i) {
int pos{ 0 };
for (int j = 0; j < iter_batch; ++j) {
std::vector<std::vector<T>> data_batch;
std::vector<T> labels_batch;
int remainder{ 0 };
if (pos + step < train_num) remainder = step;
else remainder = train_num - pos;
data_batch.resize(remainder);
labels_batch.resize(remainder, (T)0.);
for (int t = 0; t < remainder; ++t) {
data_batch[t].resize(thetas.size(), (T)0.);
for (int m = 0; m < thetas.size(); ++m) {
data_batch[t][m] = data[pos + t][m];
}
labels_batch[t] = labels[pos + t];
}
gradient_descent(data_batch, labels_batch, remainder);
pos += step;
}
}
}
template<typename T>
void LogisticRegression<T>::gradient_descent(const std::vector<std::vector<T>>& data_batch, const std::vector<T>& labels_batch, int length_batch)
{
std::unique_ptr<T[]> z(new T[length_batch]), gradient(new T[this->thetas.size()]);
for (int j = 0; j < length_batch; ++j) {
z.get()[j] = (T)0.;
for (int t = 0; t < this->thetas.size(); ++t) {
z.get()[j] += data_batch[j][t] * this->thetas[t];
}
}
std::unique_ptr<T[]> pcal_a(new T[length_batch]), pcal_b(new T[length_batch]), pcal_ab(new T[length_batch]);
for (int j = 0; j < length_batch; ++j) {
pcal_a.get()[j] = calc_sigmoid(z.get()[j]) - labels_batch[j];
pcal_b.get()[j] = data_batch[j][0]; // bias
pcal_ab.get()[j] = pcal_a.get()[j] * pcal_b.get()[j];
}
gradient.get()[0] = ((T)1. / length_batch) * std::accumulate(pcal_ab.get(), pcal_ab.get() + length_batch, (T)0.); // bias
for (int j = 1; j < this->thetas.size(); ++j) {
for (int t = 0; t < length_batch; ++t) {
pcal_b.get()[t] = data_batch[t][j];
pcal_ab.get()[t] = pcal_a.get()[t] * pcal_b.get()[t];
}
gradient.get()[j] = ((T)1. / length_batch) * std::accumulate(pcal_ab.get(), pcal_ab.get() + length_batch, (T)0.) +
(this->lambda / length_batch) * this->thetas[j];
}
for (int i = 0; i < thetas.size(); ++i) {
this->thetas[i] = this->thetas[i] - this->learning_rate / length_batch * gradient.get()[i];
}
}
template<typename T>
int LogisticRegression<T>::load_model(const std::string& model)
{
std::ifstream file;
file.open(model.c_str(), std::ios::binary);
if (!file.is_open()) {
fprintf(stderr, "open file fail: %s\n", model.c_str());
return -1;
}
int length{ 0 };
file.read((char*)&length, sizeof(length));
thetas.resize(length);
file.read((char*)thetas.data(), sizeof(T)*thetas.size());
file.close();
return 0;
}
template<typename T>
T LogisticRegression<T>::predict(const T* data, int feature_length) const
{
CHECK(feature_length + 1 == thetas.size());
T value{(T)0.};
for (int t = 1; t < thetas.size(); ++t) {
value += data[t - 1] * thetas[t];
}
return (calc_sigmoid(value + thetas[0]));
}
template<typename T>
int LogisticRegression<T>::store_model(const std::string& model) const
{
std::ofstream file;
file.open(model.c_str(), std::ios::binary);
if (!file.is_open()) {
fprintf(stderr, "open file fail: %s\n", model.c_str());
return -1;
}
int length = thetas.size();
file.write((char*)&length, sizeof(length));
file.write((char*)thetas.data(), sizeof(T) * thetas.size());
file.close();
return 0;
}
template<typename T>
T LogisticRegression<T>::calc_sigmoid(T x) const
{
return ((T)1 / ((T)1 + exp(-x)));
}
template<typename T>
T LogisticRegression<T>::norm(const std::vector<T>& v1, const std::vector<T>& v2) const
{
CHECK(v1.size() == v2.size());
T sum{ 0 };
for (int i = 0; i < v1.size(); ++i) {
T minus = v1[i] - v2[i];
sum += (minus * minus);
}
return std::sqrt(sum);
}
template class LogisticRegression<float>;
template class LogisticRegression<double>;
} // namespace ANN#include "funset.hpp"
#include <iostream>
#include "perceptron.hpp"
#include "BP.hpp""
#include "CNN.hpp"
#include "linear_regression.hpp"
#include "naive_bayes_classifier.hpp"
#include "logistic_regression.hpp"
#include "common.hpp"
#include <opencv2/opencv.hpp>
// ================================ logistic regression =====================
int test_logistic_regression_train()
{
const std::string image_path{ "E:/GitCode/NN_Test/data/images/digit/handwriting_0_and_1/" };
cv::Mat data, labels;
for (int i = 1; i < 11; ++i) {
const std::vector<std::string> label{ "0_", "1_" };
for (const auto& value : label) {
std::string name = std::to_string(i);
name = image_path + value + name + ".jpg";
cv::Mat image = cv::imread(name, 0);
if (image.empty()) {
fprintf(stderr, "read image fail: %s\n", name.c_str());
return -1;
}
data.push_back(image.reshape(0, 1));
}
}
data.convertTo(data, CV_32F);
std::unique_ptr<float[]> tmp(new float[20]);
for (int i = 0; i < 20; ++i) {
if (i % 2 == 0) tmp[i] = 0.f;
else tmp[i] = 1.f;
}
labels = cv::Mat(20, 1, CV_32FC1, tmp.get());
ANN::LogisticRegression<float> lr;
const float learning_rate{ 0.00001f };
const int iterations{ 250 };
int reg_kinds = lr.REG_DISABLE; //ANN::LogisticRegression<float>::REG_L1;
int train_method = lr.MINI_BATCH; //ANN::LogisticRegression<float>::BATCH;
int mini_batch_size = 5;
int ret = lr.init((float*)data.data, (float*)labels.data, data.rows, data.cols/*,
reg_kinds, learning_rate, iterations, train_method, mini_batch_size*/);
if (ret != 0) {
fprintf(stderr, "logistic regression init fail: %d\n", ret);
return -1;
}
const std::string model{ "E:/GitCode/NN_Test/data/logistic_regression.model" };
ret = lr.train(model);
if (ret != 0) {
fprintf(stderr, "logistic regression train fail: %d\n", ret);
return -1;
}
return 0;
}
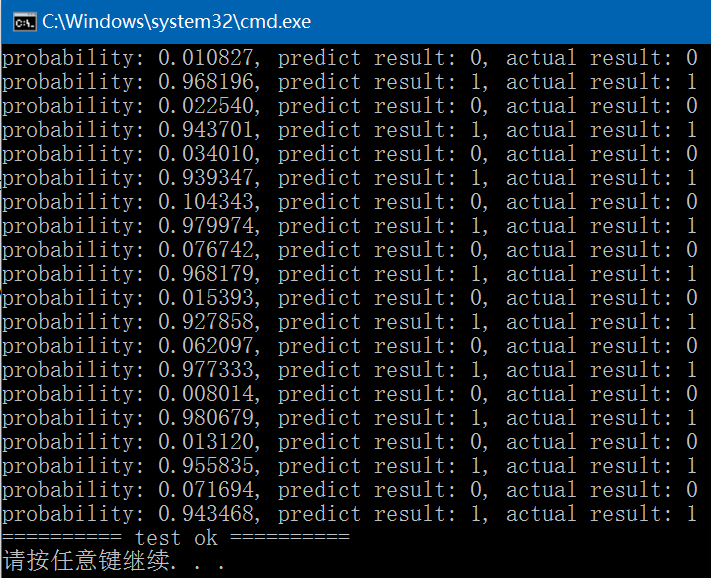
int test_logistic_regression_predict()
{
const std::string image_path{ "E:/GitCode/NN_Test/data/images/digit/handwriting_0_and_1/" };
cv::Mat data, labels, result;
for (int i = 11; i < 21; ++i) {
const std::vector<std::string> label{ "0_", "1_" };
for (const auto& value : label) {
std::string name = std::to_string(i);
name = image_path + value + name + ".jpg";
cv::Mat image = cv::imread(name, 0);
if (image.empty()) {
fprintf(stderr, "read image fail: %s\n", name.c_str());
return -1;
}
data.push_back(image.reshape(0, 1));
}
}
data.convertTo(data, CV_32F);
std::unique_ptr<int[]> tmp(new int[20]);
for (int i = 0; i < 20; ++i) {
if (i % 2 == 0) tmp[i] = 0;
else tmp[i] = 1;
}
labels = cv::Mat(20, 1, CV_32SC1, tmp.get());
CHECK(data.rows == labels.rows);
const std::string model{ "E:/GitCode/NN_Test/data/logistic_regression.model" };
ANN::LogisticRegression<float> lr;
int ret = lr.load_model(model);
if (ret != 0) {
fprintf(stderr, "load logistic regression model fail: %d\n", ret);
return -1;
}
for (int i = 0; i < data.rows; ++i) {
float probability = lr.predict((float*)(data.row(i).data), data.cols);
fprintf(stdout, "probability: %.6f, ", probability);
if (probability > 0.5) fprintf(stdout, "predict result: 1, ");
else fprintf(stdout, "predict result: 0, ");
fprintf(stdout, "actual result: %d\n", ((int*)(labels.row(i).data))[0]);
}
return 0;
}















 701
701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









