







《MATLAB神经网络编程》 化学工业出版社 读书笔记
第四章 前向型神经网络 4.2 线性神经网络
本文是《MATLAB神经网络编程》书籍的阅读笔记,其中涉及的源码、公式、原理都来自此书,若有不理解之处请参阅原书。
首先定义一些神经网络中常用的参数意义,如下图:

一,线性神经网络的构建。
1,生成线性神经元。
构建一个如下图所示的具有两个输入端的单神经元线性网络。
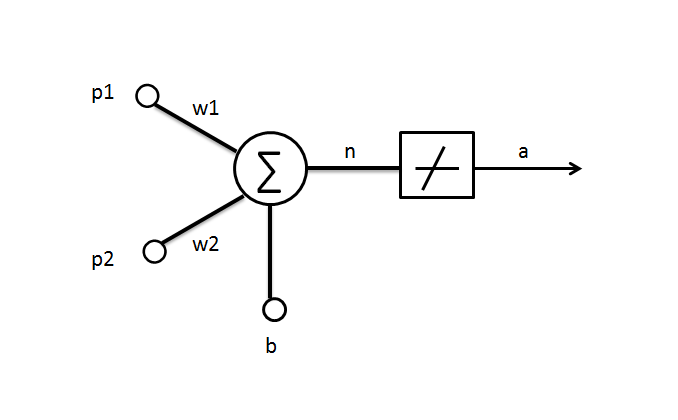
其权值矩阵W是一个行向量,网络输出a为:
a=purelin(n)=purelin(WP+b)=WP+b
或者:
a=w1,1*p1+w1,2*p2+b
与感知器一样,线性神经网络也有一个分界线,由输入向量决定,即n=0时,方程WP+b=0,分类示意图如下:
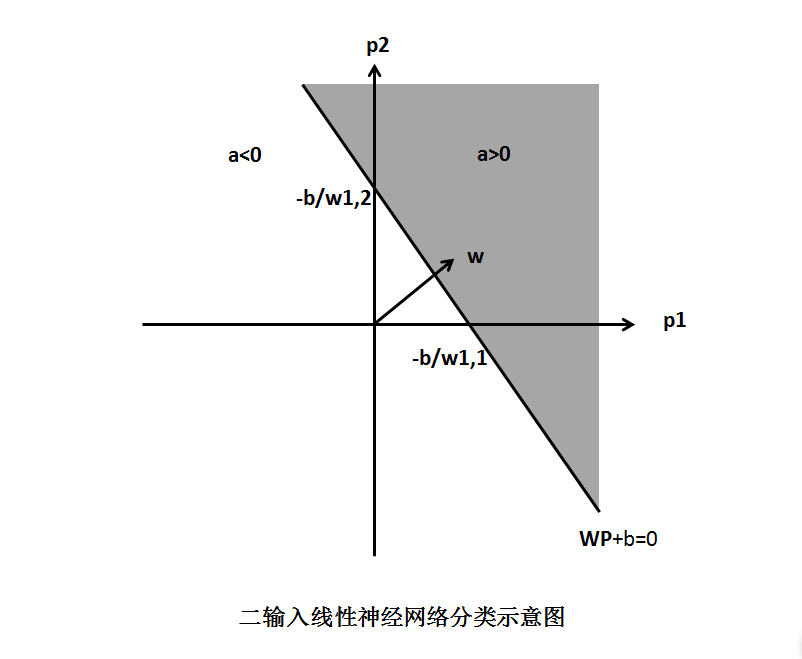
输入向量在分界线右上时,输出大于0;输入向量在左下时,输出小于0.这样,线性神经网络就可以用来研究分类问题;当然,前提是进行分类的问题是线性可分的,这与感知器的局限是相同的。
【例4-13】应用newlin设计一个双输入单输出线性神经网络,输入向量范围是[-1 1;-1 1],学习速率是1。
源代码是如下:
clear all
net=newlin([-1 1;-1 1],1); %此时网络权值和阈值默认为0
W=net.IW{1,1} %W=0 0
b=net.b{1} %b=0
net.IW{1,1}=[2 3]; %分别设置网络的权值、阈值
net.b{1}=[-4];
p=[5;6]; %p是输入向量
a=sim(net,p) %利用上面建立的网络判断p相应的输出a输出是:

2,线性滤波器。
首先是应用于线性神经网络中的触发延迟线(这个到底是什么我是在不明白)。
若在线性神经网络中应用了触发延迟线,则产生的线性滤波器的输出:
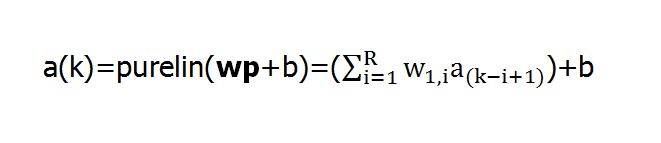
这样的网络可以应用于信号处理滤波。
【例4-14】假设输入向量P,期望输出向量T,以及初始输入延迟P1。
源代码如下:
clear all
P={1 2 1 3 3 2};
P1={1 3};
T={5 6 4 20 7 8};
%应用newlind函数构造一个网络以满足上面的输入/输出关系和延迟条件
net=newlind(P,T,P1);
Y=sim(net,P,P1) %验证网络的输出。输出为:

二,网络训练。
自适应线性元件的网络训练过程可以归纳为三个步骤:
(1),表达。计算训练的输出矢量a=wp+b,以及与期望输出之间的误差e=t-a.
(2),检查。将网络的输出误差的平方和与期望误差相比较,如果其值小于期望误差,或者训练已经达到事先设定的最大训练次数,则停止训练,否则继续。
(3),学习。采用W-H学习规则计算新的权值和偏差,并返回第一步。
每进行一次上述三个步骤,就认为是完成一个训练循环次数。
如果经过训练,网络仍然不能达到期望目标,可以有两种选择:一是检查一下所要解决的问题,是否适用于线性网络;二是对网络进行进一步的训练。
虽然只适用于线性网络,W-H学习规则仍然是重要的,因为它展现了梯度下降法是如何来训练一个网络的,此概念后来发展成反射传播法,使之可以训练多层非线性网络。
【例4-15】考虑一个较大的神经元网络的模式联想的设计问题。输入矢量和目标矢量分别是:
P=[1 1.5 1.2 -0.3;-1 2 3 -0.5;2 1 -1.6 0.9];
T=[0.5 3 -2.2 1.4;1.1 -1.2 1.7 -0.4;3 0.2 -1.8 -0.4;-1 0.4 -1.0 0.6];
这个问题可以通过线性方程组的方式求出唯一的解,这是比较复杂,此时就可以通过自适应线性网络的方式得出有一定误差的解。
源代码:
clear all;
P=[1 1.5 1.2 -0.3;-1 2 3 -0.5;2 1 -1.6 0.9];
T=[0.5 3 -2.2 1.4;1.1 -1.2 1.7 -0.4;3 0.2 -1.8 -0.4;-1 0.4 -1.0 0.6];
[S,Q]=size(T);
max_epoch=400; %最大训练次数
err_goal=100;
err_goal=0.001;
lr=0.9*maxlinlr(P);
%初始权值
W0=[1.9978 -0.5959 -0.3517;1.5543 0.05331 1.3660;...
1.0672 0.3645 -0.9227 ;-0.7747 1.3839 -0.3384];
B0=[0.0746;-0.0642;-0.4256;-0.6433];
net=newlin(minmax(P),S,[0],lr);
net.IW{1,1}=W0;
net.b{1}=B0;
a=sim(net,P);
e=T-a;
sse=(sumsqr(e))/(S*Q); %求误差平方和的平均值
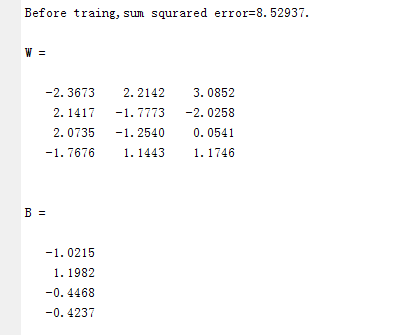
fprintf('Before traing,sum squrared error=%g.\n',sse); %显示训练前的网络均方差
net.trainParam.epochs=400; %最大循环次数
net.trainParam.goal=0.001; %期望误差(均方差)
[net,tr]=train(net,P,T);
W=net.iw{1,1}
B=net.b{1} %显示最终的权值输出的结果:
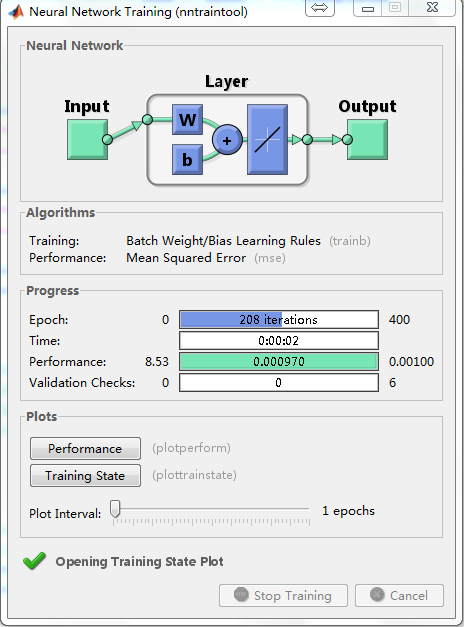
对于存在零误差的精确权值网络,若用函数newlind来求解,则更加简单,上例可以用源代码如下:
clear all;
P=[1 1.5 1.2 -0.3;-1 2 3 -0.5;2 1 -1.6 0.9];
T=[0.5 3 -2.2 1.4;1.1 -1.2 1.7 -0.4;3 0.2 -1.8 -0.4;-1 0.4 -1.0 0.6];
[S,Q]=size(T);
b=[];
w=[];
a=[];
for i=1:S
net=newlind(P,T(i,:)); %设计一个具有一个行向量的线性网络
w=[w;net.iw{1,1}]
b=[b;net.b{1}]
a=[a;sim(net,P)]
end
w %输出完整的偏差和权值
b
a %显示网络的最终输出

因为newlind是按(行)向量序列的方式来构造和设计一个线性网络的,所以对于具有多输出神经网络的设计,需要经过多次循环来获得最终成果。
通常可以直接判断一个线性网络是否有完美的零误差的解。如果每个神经元所具有的自由度(权值与阈值的数量和)等于或者大于限制数(即输入或者输出的矢量对)【可以认为是公式:R+1>=Q】,那么线性网络可以零误差的解决问题。不过这一结论在输入矢量线性相关或者没有阈值时不成立。














 196
196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









