







《MATLAB神经网络编程》 化学工业出版社 读书笔记
第四章 前向型神经网络 4.3 BP传播网络
本文是《MATLAB神经网络编程》书籍的阅读笔记,其中涉及的源码、公式、原理都来自此书,若有不理解之处请参阅原书
一,BP网络的限制
在人工神经网络的应用中,绝大部分的神经网络模型采用了BP网络及其变化形式,但这并不说明BP网络是完美的,其各种算法依然存在一定的局限性。BP网络的局限性主要有以下几个方面。
1,学习速率与稳定性的矛盾。
梯度算法进行稳定学习要求的学习速率较小,所以通常学习过程的收敛速度较慢。附加动量法通常比简单的梯度算法快,因为在保证稳定学习的同时,其可以采用很高的学习速率,但是对于许多实际应用仍然太慢。以上两种方法通常只适用于希望增加训练次数的情况。如果有足够的存储空间,即对于中、小规模的神经网络通常可采用Levenberg-Mrquardt算法:如果存储空间不足,则可采用其他多种快速算法,如对于大规模神经网络采用trainscg或者trainrp算法更合适。
2,学习速率的选择缺乏有效的方法。
对于非线性网络,选择学习速率是一件十分困难的事情。对于现行网络,学习速率选择的太大,会容易导致学习不稳定;反之,学习速率选择的太小,则可能导致无法容忍的过长的训练时间。不同于线性网络,还没有找到一个简单易行的方法以解决非线性网络选择学习速率的问题。对于快速训练算法,其默认参数值通常有裕量。
3,训练过程可能陷于局部最小
从理论上说,多层BP网络可以实现任意可实现的线性和非线性函数的映射,从而克服了感知器和线性神经网络的局限性。但是在实际应用中,BP网络通常在训练过程中也可能找不到某个具体问题的解,比如在训练过程中陷入局部最小的情况。当BP网络在训练过程中陷入误差性能函数的局部最小时,可以通过改变其初始值和经过多次训练来获得全局最小。
4,没有确定隐层神经元个数的有效方法
确定多层神经网络隐层神经元数也是一个很重要的问题,太少的神经元会导致网络“欠适配”,太多的隐层神经元会导致“过适配”。
二,BP方法的改进。
由于在人工神经网络中,反向传播法占了非常重要的地位,所以最近十几年来,许多研究人员对其做了深入的研究,提出了许多改进方法。主要目标是为了加快训练速度、避免陷入局部最小和改善其他能力。本文主要讨论前面两种性能的改建方法。
1,附加动量法
附加动量法使网络在修正其权值时,不仅考虑误差在梯度上的作用,还考虑在误差曲面上变化趋势的影响,其作用如同一个低通滤波器,其允许网络忽略网络上的微小变化特性。在没有附加动量的作用下,网络可能陷入浅的局部极小值,利用附加动量的作用则可能划过这些极小值。
该方法是在反向传播法的基础上,在每一个权值的变化上加上一项正比于前次权值变化量的值,并根据反向传播法来产生新的权值变化。带有附加动量因子的权值调节公式为:
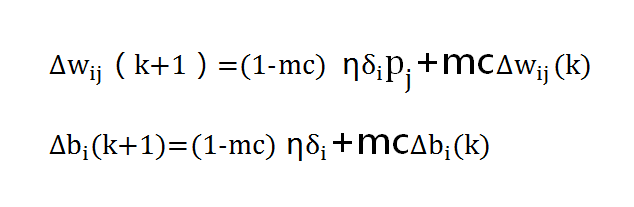
其中,k为训练次数;mc为动量因子,一般取值0.95左右。
附加动量法的实质是将最后一次权值变化的影响通过一个动量因子来传递。当动量因子取值为0时,权值的变化根据梯度下降法产生;当动量因子取值为1时,新的权值变化则设置为最后一次权值的变化,而依据梯度法产生的变化部分则被忽略了。以此方式,当增加了动量项后,促使权值的调节向着误差曲面底部的平均方向变化,当网络权值进入误差曲面底部的平坦区时,δi将会变得很小,于是 :
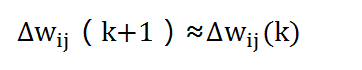
从而防止了:Δw_ij(k)=0的出现,有助于使网络从误差曲面局部极小值中跳出。
根据附加动量法的设计原则,当修正的权值在误差中导致太大的增长结果时,新的权值应该被取消而不被采用,并使动量停止下来,以使网络不进入较大的误差曲面;当新的误差变化率对于其旧值超过一个事先设定的最大误差变化率时,也得取消所计算的权值变化。 其最大误差变化率可以是任何大于或等于1的值,典型值取1.04。所以在进行附加动量法的训练程序设计时必须加进条件判断以正确使用其权值修正公式。
训练过程中对采用动量法的判断条件是:

所有这些判断过程的细节均包含在MATLAB工具箱的traingdm函数中,只要在调用 train的算法项中选用“traingdm”即可,另外需要对 动量因子赋值:
net.trainParam.mc=0.95
如果不赋值,表示函数的默认值为0.9。其他值不用赋。
【例4-36】采用附加动量法的反向传播网络的训练。
源码:
clear all;
% 初始化
P=[-6.0 -6.1 -4.1 -4.05 5.0 -5.1 6.0 6.1];
T=[0 0 0.97 0.99 0.01 0.03 1.0 1.0];
[R,Q]=size(P);
[S,Q]=size(T);
disp('The bias B is fixed at 3.0 and will not learn');
Z1=menu('Intialize Weight with:',... %作菜单
'W0=[-0.9]; B0=3;',... %按给定的初始值
'Pick Values with Mouse/Arrow Keys',... %用鼠标在图上任点初始值
'Random Intial Condition [Default];') %随机初始值(缺省情况)
disp('');
B0=3;
if Z1==1
W0=[-0.9];
elseif Z1==3
W0=rand(S,R);
end
% 作权值-误差关系图并标注初始值
% 作网络误差曲线图
error1=[];
net=newcf(minmax(P),[1],{'logsig'}); %创建非线性单层网络
net.b{1}=B0;
j=[-1:0.1:1];
for i=1:21
net.iw{1,1}=j(i);
y=sim(net,P);
err=sumsqr(y-T);
error1=[error1 err]
end
plot(j,error1) %网络误差曲线图
hold on;
Z2=menu('Use momentiurn constant of:',... %作菜单
'0.0',...
'0.95 [Default]');
if Z1==2
[W0,dummy]=ginput(1);
end
disp('');
% 训练网络
if Z2==1
momentum=0;
else
momentum=0.95;
end
ls=[]; error=[];w=[];
max_epoch=500; err_goal=0.01;
lp.lr=0.05; lp.mc=momentum; %赋初值
err_ratio=1.04;
W=W0; B=B0;
A=logsig(W0*P+B0*ones(1,8));
E=T-A; SSE=sumsqr(E);
for epoch=1:max_epoch
if SSE<err_goal
epoch=epoch-1;
break;
end
D=A.*(1-A).*E;
gW=D*P';
dw=learngdm([],[],[],[],[],[],[],gW,[],[],lp,ls); %权值的增量
ls.dw=dw; %赋学习状态中的权值增量
TW=W+dw; %变化后的权值
TA=logsig(TW*P+B*ones(1,8));
TE=T-TA; TSSE=sumsqr(TE); %求输出结果
if TSSE>SSE*err_ratio %判断赋动量因子
mc=0;
elseif TSSE<SSE
mc=momentum;
end
W=TW; A=TA; E=TE; SSE=TSSE;
error=[error TSSE]; %记录误差
w=[w W]; %记录权值
end
plot(w,error,'or'); %作误差随权值的变化图
hold off;
disp('按任意键继续'); pause;
figure; plot(error); %训练误差图
误差曲线如下:
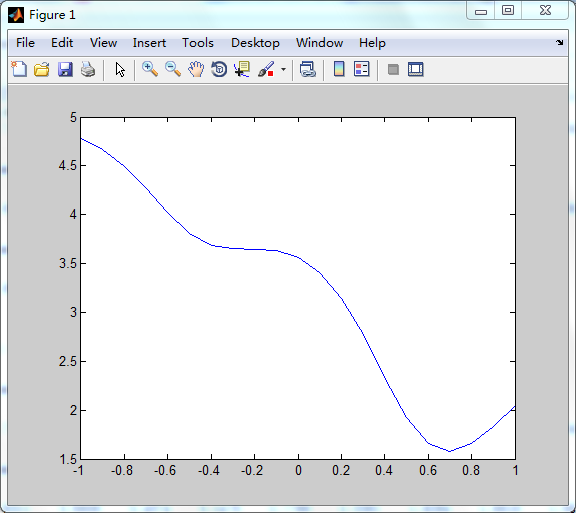
可见误差曲面上有两个误差最小值,左边的是局部极小值,右边的是全局最小值。
如果动量因子mc取值为0,网络以纯梯度法进行训练,此时训练结果如下:
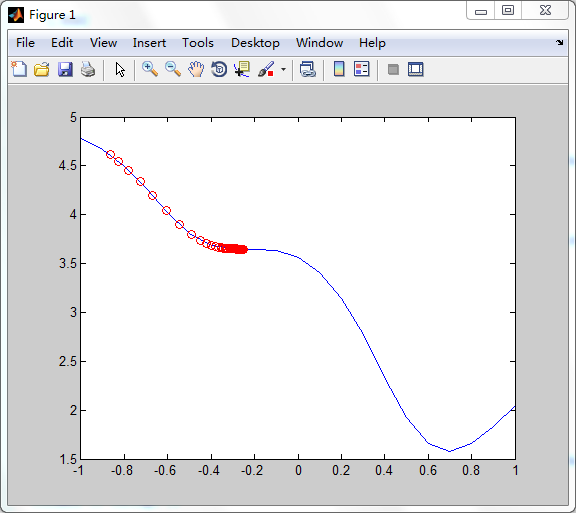
其误差的变化趋势是以简单的方式”滚到“局部极小值的底部就停止再也不动了。
当采用附加动量法之后,网络的训练则可以自动的避免陷入这个局部极小值。这个结果如下图:
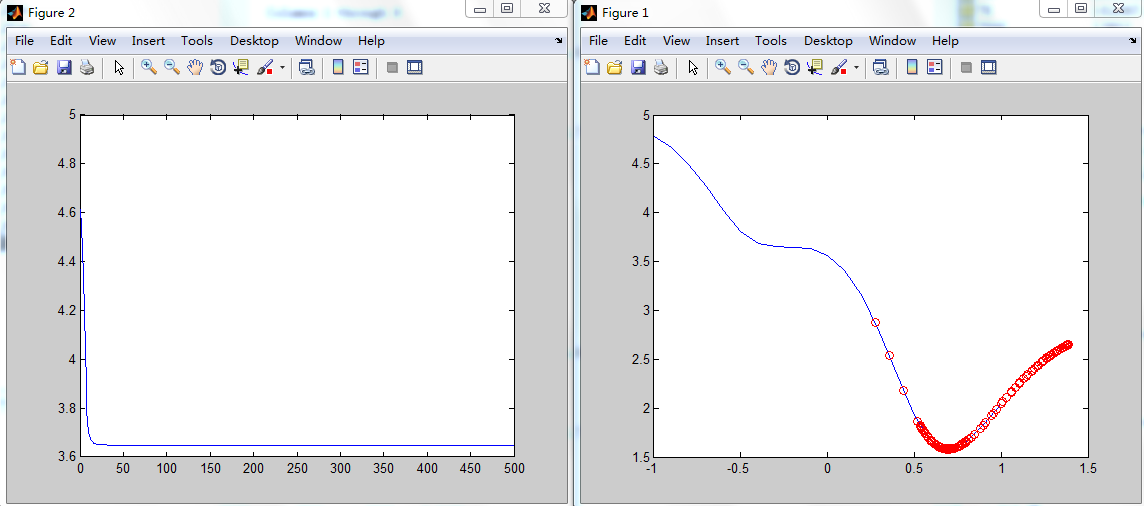
左边是误差记录,右边的是带有附加动量的训练结果。网络的训练误差先是落入局部极小值,在附加动量的作用下,继续向前产生一个正向斜率的运动,并跳出较浅的峰值,落入全局最小值。然后,仍然在附加动量的作用下,达到一定的高度后(即产生一个SSE>1.04*SSE)自动返回,并像弹子滚动一样来回左右摆动,直至停留在最小值点上。
2,自适应学习速率
对于一个特定的问题,要选择适当的学习速率不是一件容易的事情。通常是凭借经验获取(经验是最难的地方),即使这样,训练开始初期功效较好的学习速率,不见得对后来的训练也合适。为了解决这一问题,人们自然回想到使网络在训练过程中自动调整学习速率。通常调整学习速率的准则是:检查权值的修正值是否真正降低了误差函数,如果的确如此,说明所选取的学习速率值小了,可以对其增加一个量;如果不是这样,则产生了过调,那么就应该减小学习速率的值。 与采用附加动量法时的判断条件相仿,当新的误差超过旧的误差一定的倍数时,学习速率将减少;否则其学习速率保持不变;当新的误差小于旧的误差时,学习速率将被增加。 此方法可以保证网络稳定学习,使其误差继续下降,提高学习速率,使其以更大的学习速率进行学习。一旦学习速率调的过大,而不能保证误差继续减小,即应该减小学习速率,直到其学习过程稳定为止。
下式是一种自适应学习速率的调整公式:

初始学习速率η(0)的选取范围可以有很大的随意性。
实践证明,采用自适应学习速率的网络训练次数只是固定学习速率网络训练次数的几十分之一,所以具有自适应学习速率的网络训练是极有效的训练方法。
3,弹性BP算法
BP网络通常采用S型激活函数的隐含层。S型函数常被称为”压扁“函数它把一个无限的输入范围压缩到 一个有限的输出范围。其特点是当输入很大时,斜率接近0,这将导致算法中的梯度幅值很小,可能使得对网络权值的修正过程几乎 停顿下来。
弹性BP算法只取偏导数的符号,而不考虑偏导数的幅值。偏导数的符号决定权值更新的方向 ,而权值变化的大小由一个独立的”更新值“确定。如如果在两次连续的迭代中,目标 函数对某个权值的偏导数的符号不变号,则增大相应的”更新值“(如在前一次”更新值“的基础上乘以1.3);若变号,则减少相应的“更新值”(如在前一次“更新值”的基础上乘以0.5)。
在弹性BP算法中,当训练发生振荡时,权值的变化量将会减少;当在几次迭代过程中权值都朝一个方向变化时,权值的变化量将增大。因此,一般来说,弹性BP算法的收敛速度要比前述几种方法快得多,而且算法也不复杂,更不需要消耗更多的内存。
上述三种改进算法的存取量要求相差不大,各个算法的收敛速度依次加快,其中弹性BP收敛速度远远大于前面两者。大量实际应用已经证明弹性BP算法非常有效。因此,在实际应用的网络训练中,当采用附加动量法乃至可变学习速率的BP算法仍然达不到训练要求时,可以采用弹性BP算法。















 574
574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









