







kernel density estimation是在概率论中用来估计未知的密度函数,属于非参数检验方法之一,由Rosenblatt (1955)和Emanuel Parzen(1962)提出,又名Parzen窗(Parzen window)。Ruppert和Cline基于数据集密度函数聚类算法提出修订的核密度估计方法。
可以参考 http://www.mvstat.net/tduong/research/seminars/seminar-2001-05/
核密度估计 ,主要是根据密度函数来计算 集合中个项的分布情况。其中密度函数是以各个数值为中心进行计算。
下面从一维数据来介绍 核密度估计。
如下图1左图所示,有12个数据点,分布在横轴坐标上,现在以箱子(直方图中的小正方块)来对数据点分布情况进行描述,每个箱子的宽度为0.5 (对应 binwidth =0.5) ,图中纵轴表示在横轴区域中出现点的数目。
当以同样的宽度,将最右边的箱子往右移动0.25,那么箱子的堆积方式变为图1右图所示。
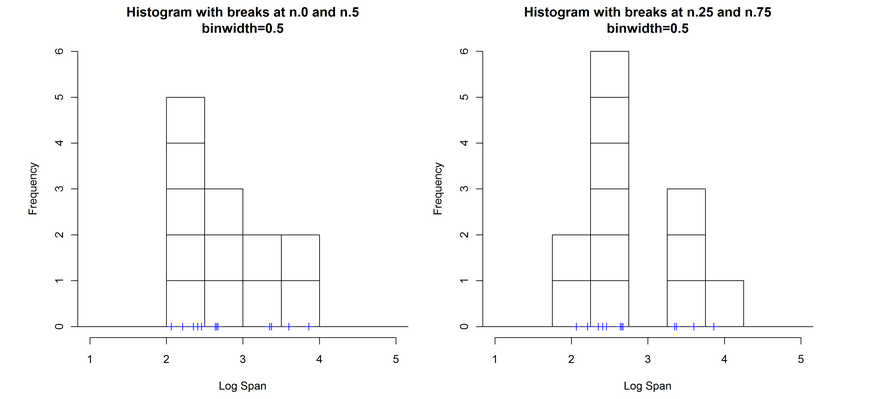
图1
从对比图1中左右两直方图,我们可以发现,这些用这些箱子来表示这些点的分布情况存在以下三点缺陷:
① 分布不够平滑
②分布依赖与最后一个箱子的位置
③分布依赖箱子的宽度
而 核心密度估计,引入核心的概念,即将箱子放到每个点上,使得点集中心为箱子的中心,箱子高度为1/6,宽度为0.25,上述点分布变为如下图2所示。
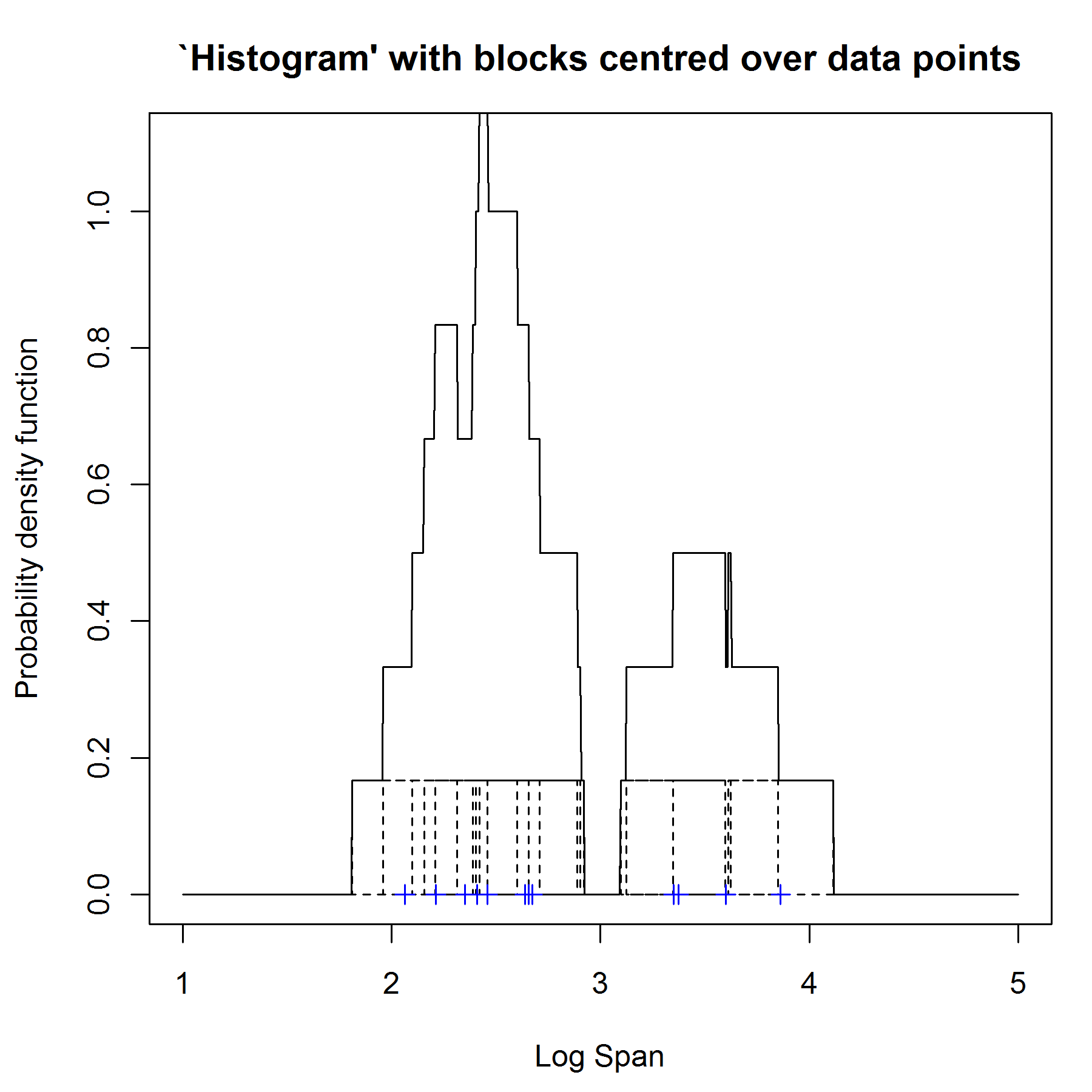
图2
上图2就是 我们所说的 box kernel density estimate 然而,这样做可以解决上述一个问题,
① 不平滑
②不依赖箱子的最后位置
③依赖箱子宽度
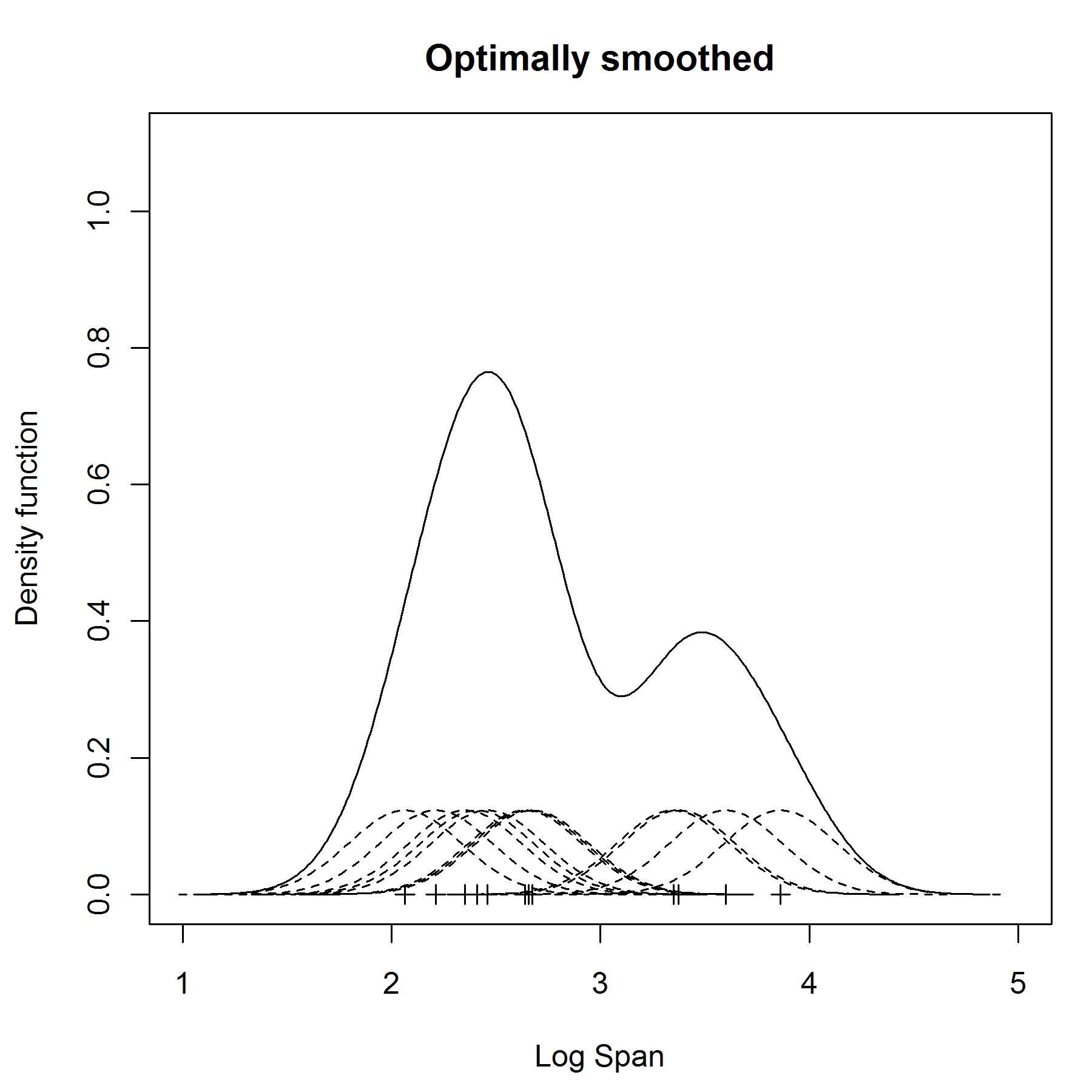
为了解决平滑的问题,我们需要选择一个合适的宽度 width ,太小(如下图undersmoothed)或者太大(如下图 oversmoothed )都不合适。
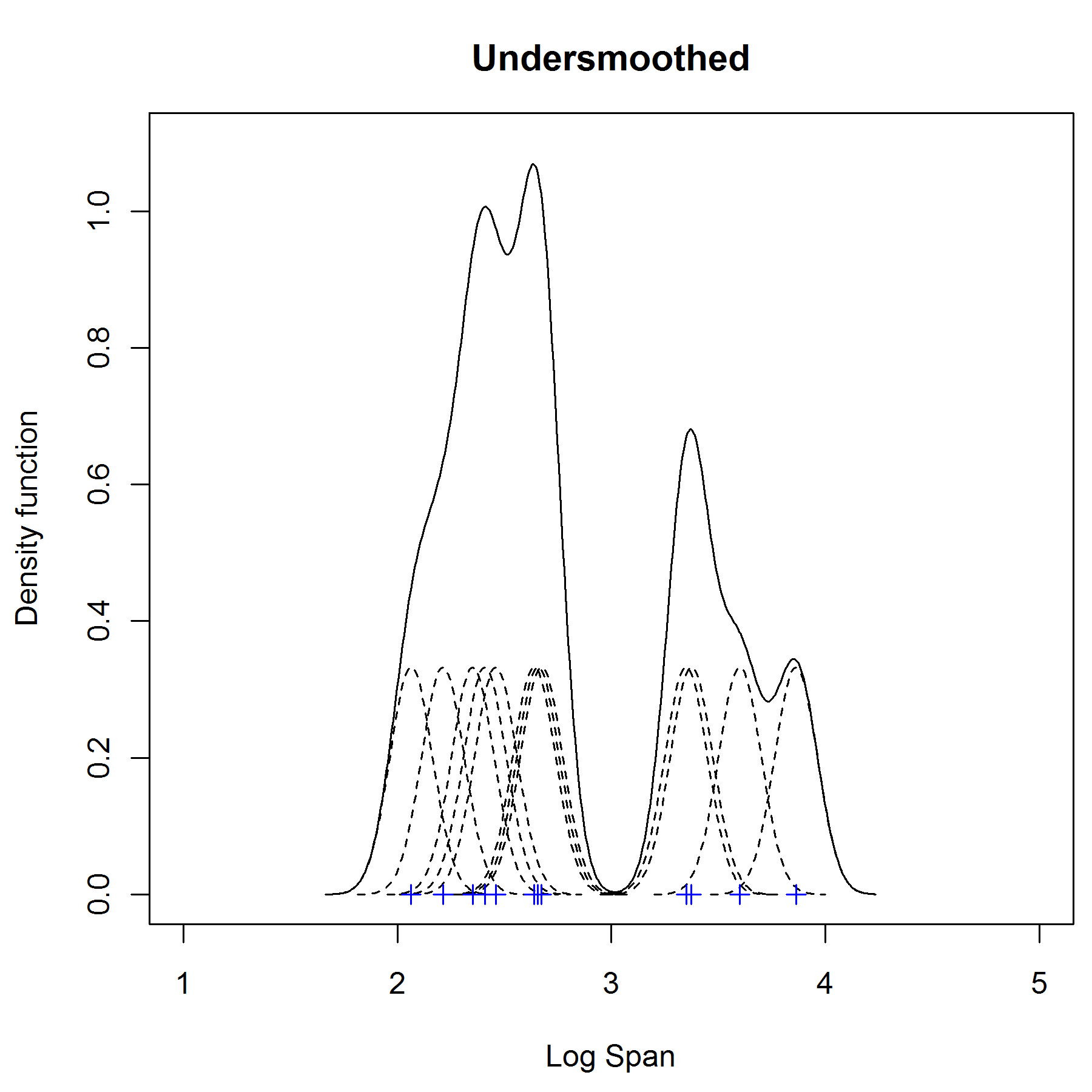
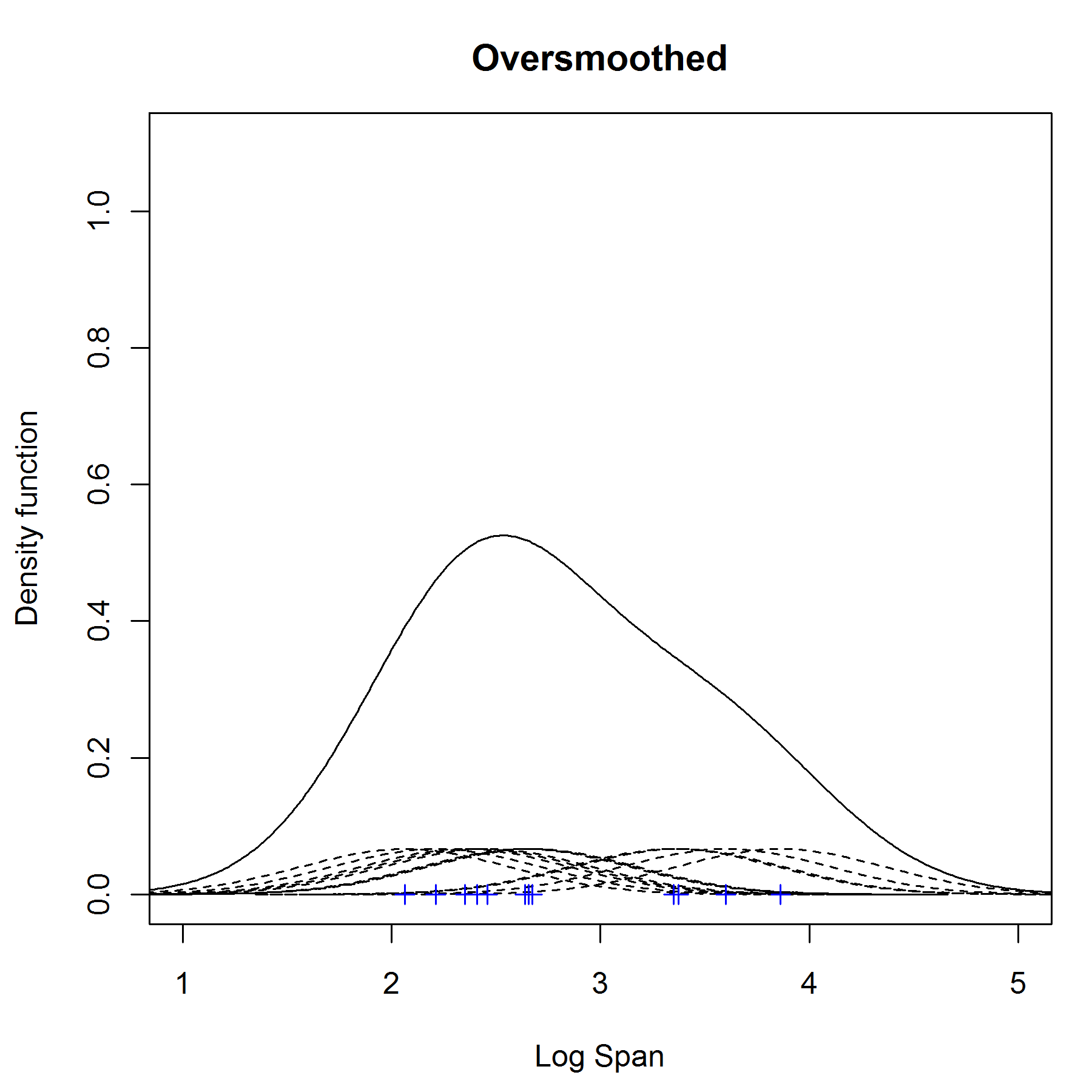
那么如何选择合适的 width 宽度呢?常见的方法是 渐进的积分方差(AMISE = Asymptotic Mean Integrated Squared Error)
bandwidth = min(AMISE) 最优的bandwidth为AMISE最小值
然而,AMISE还是依赖数据的真实的密度,但是这样渐进的到的最小值可以保持平滑,并且能包含数据的分布特征。
上述例子的最优 bandwidth = 0.25, 如下图所示
到此,我们对核心密度函数有了初步的了解,然而,这只是针对一维数据,还有针对二维,多维的情况。














 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









