







利用kmeans算法进行非监督分类
1.聚类与kmeans
- 引例:2004美国普选布什51.52% 克里48.48% 实际上,如果加以妥善引导,那么一有小部分人就会转换立场,那么如何找到这一小部分人以及如何在有限预算采取措施吸引他们呢?答案就是聚类(<<机器学习实战>>第十章)
- kmeans,k均值算法,属于聚类算法中的一种,属于非监督学习。
- 聚类中的一个重要的知识就是”簇”,简单说簇就是相似数据的集合,而在kmeans中主要是进行簇之间距离的运算,所以引入”质心”的概念,所谓质心就是代表这一簇的一个点(类比圆心),由于簇中有很多点,那么质心的选取就是利用了”均值”,簇中所有点的平均值就是簇的质心,通过簇,一堆数据被分成k类,这就成了算法的名字“k均值”的直观解释.
2.kmeans伪代码以及思想
Kmeans是发现给定数据集的k个簇的算法,k是用户给定的。
主要工作流程伪代码如下
create k个点作为质心 (通常是随机选取)
while任意一个簇存在变化时
—— for 数据集中的数据点
——— for 每个质心
————- 计算质心到点的距离
————- 打擂台 找到最小的两者距离 记录id
——— 将数据点分配到最近的簇(打擂台记录了id)
—— 更新分配后的簇的质心(簇中所有点的均值)
返回质心列表以及分配的结果矩阵
3.二分-kmeans伪代码以及思想
主要思想
将每个簇一分为二 选取最小更新
伪代码
while 簇个数小于k
—— for 每个簇
———- 记录总误差
———- 在给定的簇上进行k=2的kmeans算法
———- 计算一分为二后的总误差
—— 选择最小误差的那个簇进行划分操作
返回簇以及分配情况

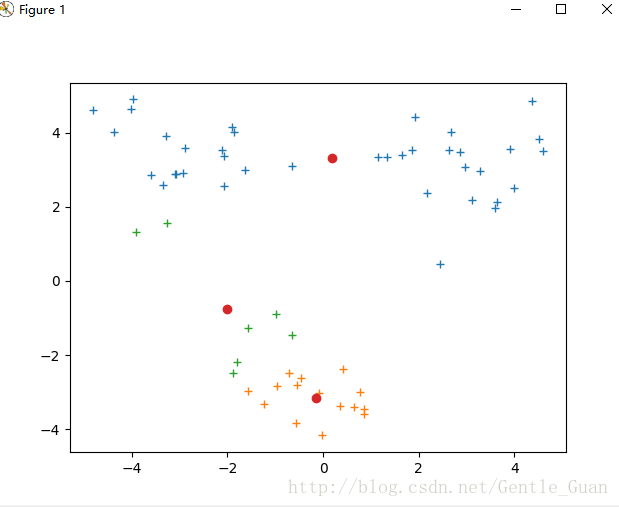
kmeans错误分类
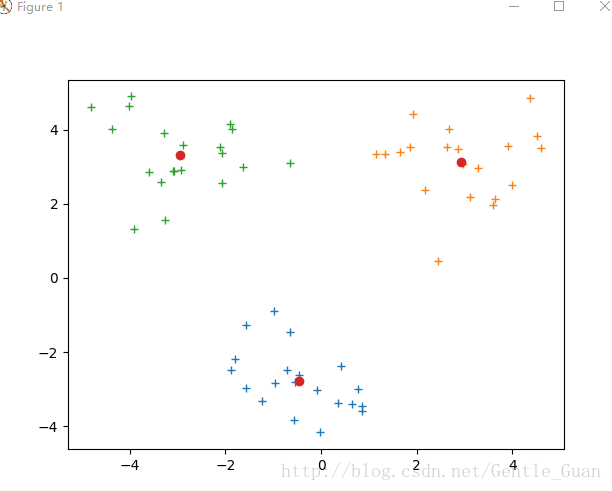
kmeans正确分类
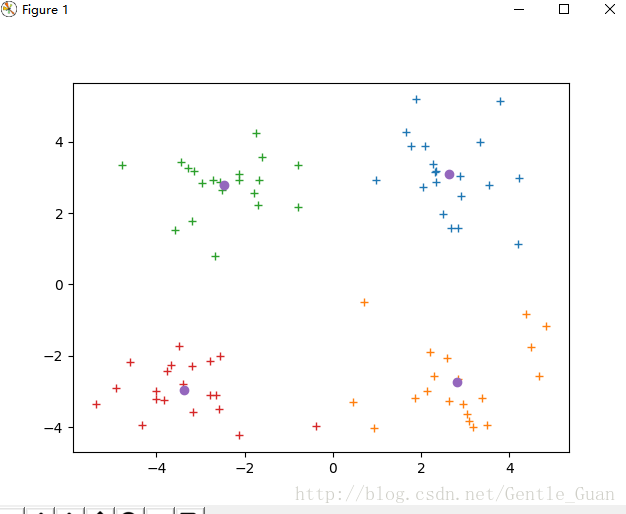
二分-kmeans未翻车
# -*- coding:utf-8 -*-
from numpy i 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









