







 本文介绍了两种寻找K-means聚类中最佳簇内误差平方和inertia的方法:一种是通过循环不断更新最小值,另一种是利用字典存储并比较。关键步骤包括初始化、模型训练、inertia比较和结果索引获取。
本文介绍了两种寻找K-means聚类中最佳簇内误差平方和inertia的方法:一种是通过循环不断更新最小值,另一种是利用字典存储并比较。关键步骤包括初始化、模型训练、inertia比较和结果索引获取。
法1
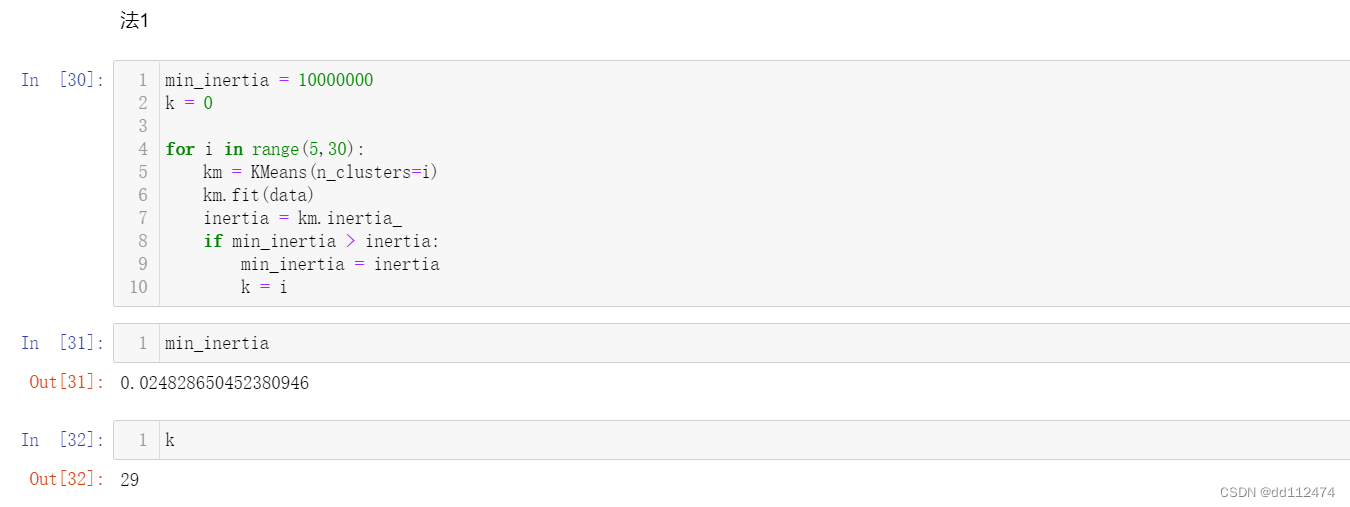
思想:最终是要找簇内误差平方和inertia最小,以及对应的k,那可以先给最后得到的min_inertia赋一个很大的值,每找到一个更小的就进行替换
先给最后得到的min_inertia赋一个很大的值,k初始值为0用来储存最后得到的n_clusters
min_inertia=1000000000
k=0
构建kmeans模型,套上循环
for i in range(2,30)
km=KMeans(n_clusters=i)
km.fit(data)
判断inertia大小,将min_inertia替换成小的,同时把此时的i赋值给k
if min_inertia > km.inertia_:
min_inertia = km.inertia_ #用到两次km.inertia,可以将其单独赋值给一个变量inertia,减少计算量
k=i
法2
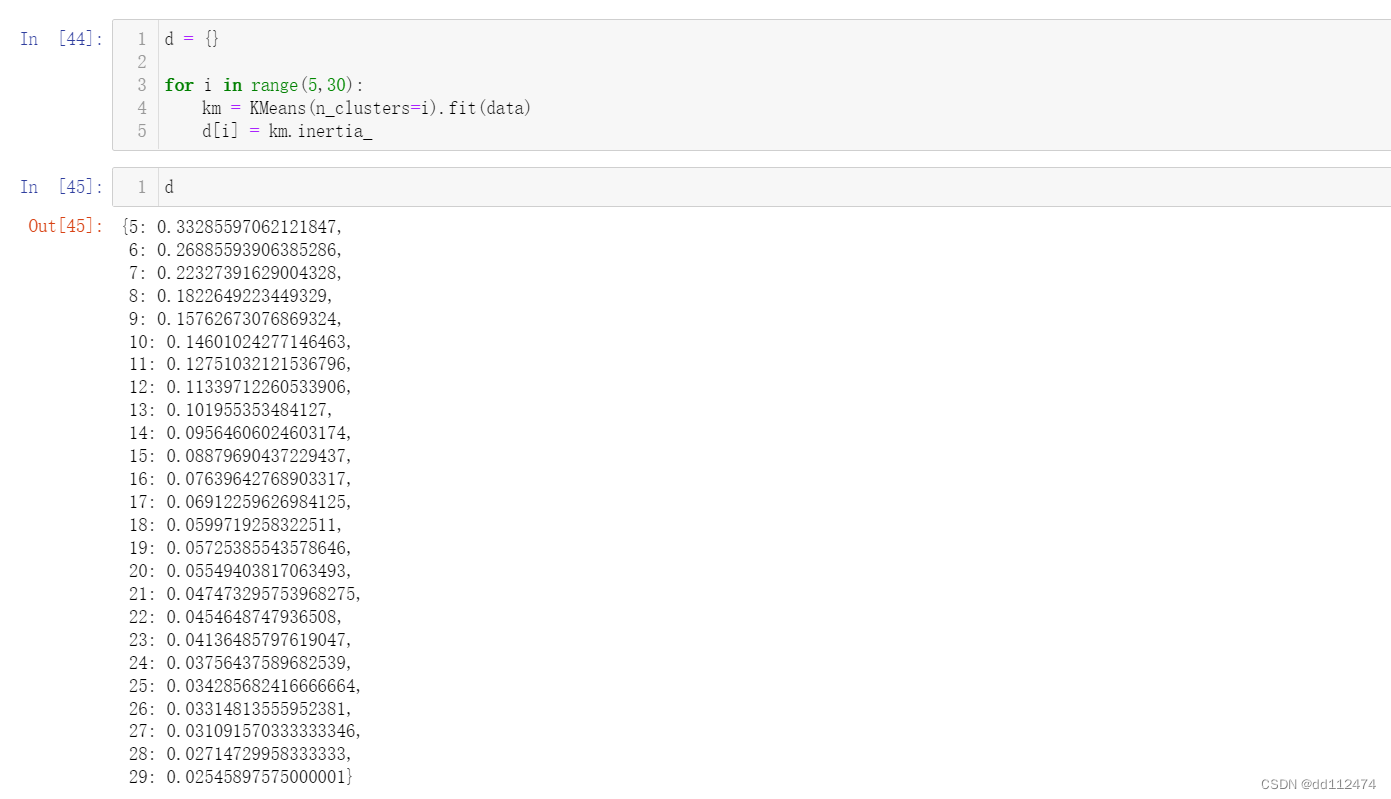
构建一个字典
d{}
遍历生成键值对 key = i ; value = km.inertia_
for i in range(5,30):
km=KMeans(inertia=i)
km.fit(data)
d[i]=km.inertia_
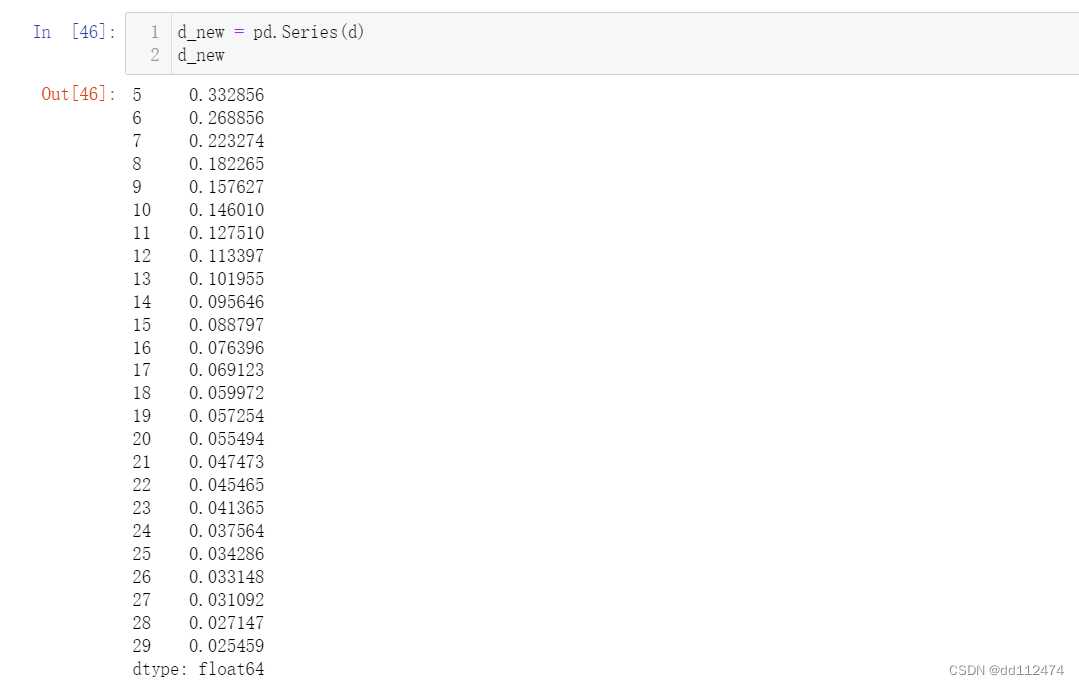
可以将字典生成一个一维数组更直观 .series()
d_new = d.series(d)
找最小值
1,用.idxmin() 返回在请求轴上第一次出现最小值的索引
d.idxmin()

2,也可以用argmin()找索引
d.argmin()

注意这俩返回的索引不一样,但是对应值是一样的

















 1566
1566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









