






写在前面的话
可怜了我这个系列的博客,写的这么好,花了很多心思去写的,却没有人知道欣赏。就像我这么好也没有人懂得欣赏,哈哈哈,我好不要脸。。。
如果您有任何地方看不懂的,那一定是我写的不好,请您告诉我,我会争取写的更加简单易懂!
如果您有任何地方看着不爽,请您尽情的喷,使劲的喷,不要命的喷,您的槽点就是帮助我要进步的地方!
1.划分数据集
1.1 基本概念
在度量数据集的无序程度的时候,分类算法除了需要测量信息熵,还需要划分数据集,度量花费数据集的熵,以便判断当前是否正确的划分了数据集。
我们将对每个特征数据集划分的结果计算一次信息熵,然后判断按照那个特征划分数据集是最好的划分方式。
也就是说,我们依次选取我们数据集当中的所有特征作为我们划定的特征,然后计算选取该特征时的信息增益,当信息增益最大时我们就选取对应信息增益最大的特征作为我们分类的最佳特征。
下面是我们的数据集:

我们用Python语言表示出这个数据集
dataSet= [[1, 1, ‘yes’], [1, 1, ‘yes’], [1, 0, ‘no’], [0, 1, ‘no’], [0, 1, ‘no’]]
在这个数据集当中有两个特征,就是每个样本的第一列和第二列,最后一列是它们所属的分类。
我们划分数据集是为了计算根据那个特征我们可以得到最大的信息增益,那么根据这个特征来划分数据就是最好的分类方法。
因此我们需要遍历每一个特征,然后计算按照这种划分方式得出的信息增益。信息增益是指数据集在划分数据前后信息的变化量。
1.2 具体操作
划分数据集的方式我们首先选取第一个特征的第一个可能取值来筛选信息。然后再选取第一个特征的第二个可能的取值来划分我们的信息。之后我们再选取第二个特征的第一个可能的取值来划分数据集,以此类推。
e.g:
[[1, 1, ‘yes’], [1, 1, ‘yes’], [1, 0, ‘no’], [0, 1, ‘no’], [0, 1, ‘no’]]
这个是我们的数据集。
如果我们选取第一个特征值也就是需不需要浮到水面上才能生存来划分我们的数据,这里生物有两种可能,1就是需要,0就是不需要。那么第一个特征的取值就是两种。
如果我们按照第一个特征的第一个可能的取值来划分数据也就是当所有的样本的第一列取1的时候满足的样本,那就是如下三个:
[1, 1, ‘yes’], [1, 1, ‘yes’], [1, 0, ‘no’]
可以理解为这个特征为一条分界线,我们选取完这个特征之后这个特征就要从我们数据集中剔除,因为要把他理解为分界线。那么划分好的数据就是:
[[1, ‘yes’], [1, ‘yes’], [0, ‘no’]]
如果我们以第一个特征的第二个取值来划分数据集,也就是当所有样本的第二列取1的时候满足的样本,那么就是
[[1, 1, ‘yes’], [1, 1, ‘yes’], [0, 1, ‘no’], [0, 1, ‘no’]]
那么得到的数据子集就是下面这个样子:
[[1,’yes’],[1,’yes’],[1, ‘no’], [1, ‘no’]]
因此我们可以很容易的来构建出我们的代码:
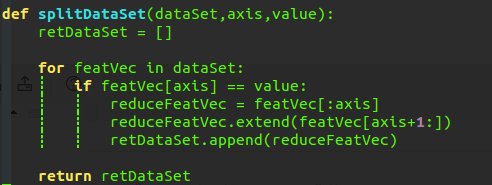
下面我们来分析一下这段代码,
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
总的来说,这段代码的功能就是按照某个特征的取值来划分数据集。
为方便您测试实验我们在贴出这段代码:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
在这里我们可以注意到一个关于链表的操作:
那就是extend 和append
它们的用法和区别如下所示:
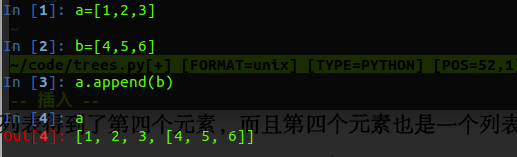
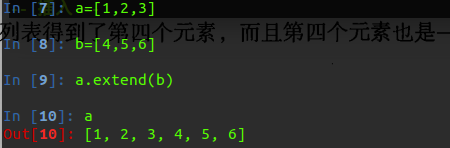
下面我们再来测试一下我们的数据:
先给出实验的完整代码
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
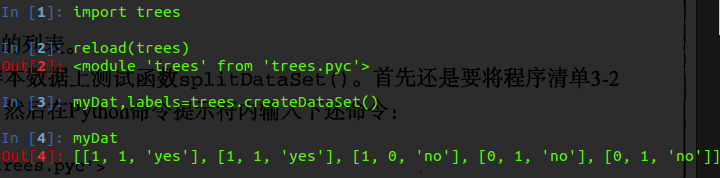
我们输入下面代码测试一下,你可以在Linux系统的终端中输入python或者是ipython 来进行测试:

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
知道怎么划分数据集之后,我们接下来的工作就是遍历整个样本集合的特征值,然后循环计算香农熵,找到最好的特征划分方式。
2.计算信息增益
我们主要是要找到划分数据前后的最大信息增益,然后找到根据那个特征来做划分,分类出来的效果更好。
下面给出代码是怎么实现的
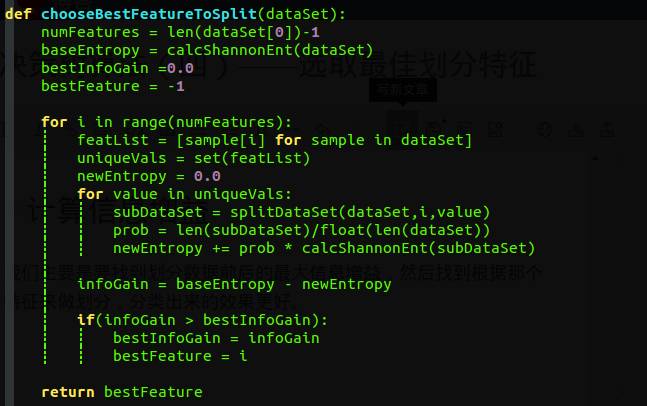
我们来分析一下代码:
注意: 在使用这段代码的时候我们对处理的数据是有要求的。
1.数据集必须是链表的表示出来的
2.数据集的每一个样本也是链表形式
3.数据集的每一个样本都必须是前面的所有列都是样本的特征值的取值范围,所有样本的最后一列是样本的类别。
4.每个样本的列数必须相同
首先我们的样本集合是:

dataSet = [[1,1,’yes’],
[1,1,’yes’],
[1,0,’no’],
[0,1,’no’],
[0,1,’no’]] # 我们定义了一个list来表示我们的数据集,这里的数据对应的是上表中的数据
我们的目的已经很明确了,就是依次遍历每一个特征,在这里我们的特征只有两个,就是需不需要浮出水面,有没有脚蹼。然后计算出根据每一个特征划分产生的数据集的熵,和初始的数据集的熵比较,我们找出和初始数据集差距最大的。那么这个特征就是我们划分时最合适的分类特征。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
被我标注的有点恶心,我在贴一遍代码,方便大家测试:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
难点
下面我们来重点解释一下刚才我们没有说的那句代码:
newEntropy += prob * calcShannonEnt(subDataSet)
为什么根据这个代码就可以计算出划分子集的熵了呢?
首先我们还是要回顾一下计算数学期望的方法,我们必须明确熵是信息的数学期望。
对于随机变量要计算它的数学期望我们是这样来计算的:
| X | X1 | X2 |
|---|---|---|
| p | p1 | p2 |
E(x)=P1*X1 + P2 *X2
我么都以第一特征值来说明问题
同理,我们可以先计算出按照第一个特征值的第一个可能取值划分满足的子集的概率,和第一个特征值的第二个可能取值划分满足子集的概率。之后分别乘以它们子集计算出的香农熵。
| 香农熵 | H1 | H2 |
|---|---|---|
| 特征值划分出子集概率 | p1 | p2 |
E(H)=H1×P1+H2×P2
e.g. 第一个特征为例
这是我们的数据集

我们按照第一个特征的第一个取值划分得到的数据集是:

得到了两个数据集,那么占总的数据集就是2/5
我们按照第一个特征的第二个取值划分得到的数据集是:

得到了三个数据集,那么占总的数据集就是3/5
我们分别来计算一下它们的香农熵


××××××
我们观察一下数据,也充分的验证了分类越多,香农熵会越大,当我们的分类只有一类是香农熵是0
××××××
我们采用列表法来计算一下熵:
| 某个特征的不同取值对应的香农熵 | 0.0 | 0.9182958340544896 |
|---|---|---|
| 特征值划分出子集概率 | 0.4 | 0.6 |
根据期望的定义,我们在第一章讲过的公式,那么就可以计算出这个特征的信息熵
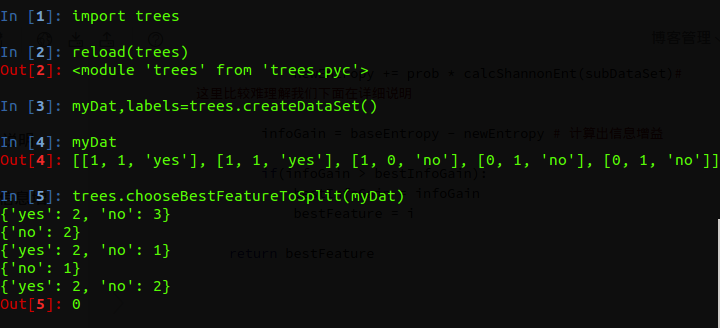
我们来测试一下结果:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
我们可以看出计算的结果是根据第一个特征划分比较好。
这个其实也很明显了,我们可以观察一下我们的数据按照第一个特征来划分,当特征为1时生物分组有两个属于鱼类,一个属于非鱼类,另一个分组全部属于非鱼类。
如果按照第二个特征分类,一组中两个属于鱼类,两个属于非鱼来,另一组中只有一个是非鱼类。也就是按照第二特征来划分,错误率比较大。
完整的代码:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
写在后面的话
要么就不做,要做就做最好














 566
566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









