







上一篇《LDA主题模型学习笔记1:模型建立》中,我们已经对一个文档集的生成过程建立了三层的LDA主题模型,模型参数是
α,β
,引入了隐变量
θ,z
,接下来就是要确定这些参数,也就是参数估计问题。
原始论文《Latent Dirichlet Allocation》中,作者使用EM算法来估计参数,只是由于模型本身有些复杂,在E-step求解隐变量期望时使用了变分推断,并找到log似然函数的tightest lower bound代替log似然函数,在M-step中用拉格朗日乘数法求解参数
β
,用牛顿方法求解参数
α
。
由于原始论文中写作顺序是自下而上的,而笔者习惯于自上而下的思路,所以刚开始看变分推断的时候一头雾水,沉迷于细节中无法自拔,在后面看到EM算法时颇有“柳暗花明又一村”之感,而在经典神书PRML中重新温习了EM算法(见《EM算法学习笔记》)之后,才算是理解了作者求解参数的思路。所以要搞清参数求解过程,私以为需要先梳理好这里面的EM思想。
有文档集 D=[w1,w2,...,wM] ,对D建立LDA模型,其实与生成D的过程是刚好是逆向的。生成D时,我们是对于每一篇document,选择topic,选择word,而建模时,是对于每一篇document,根据观测到的word,来估计它的topic的分布,即为该document建立主题模型。
所以我们的目标是,找到一个主题模型,它生成我们所观测到的word分布的概率最大,这样就成了一个最大似然问题,log似然函数如下:
我们希望找到合适的 α,β 来使这个似然函数最大化。不能直接用最大似然方法求解的情况下,我们使用EM算法。
E-step
首先我们要求隐变量
θ,z
的期望,隐变量的后验概率可以计算得到:
不幸的是,这个后验概率很难计算出来,因为在 p(w|α,β) 的概率分布都展开,可以得到:
可以看出, θ 对参数 α 有指数幂,且与 β 的乘积要基于隐变量 z 求和, θ,β 之间存在耦合关系,因而对两个参数求导都不能消掉它,所以无法计算上述对于隐变量的边缘分布。
所以作者考虑变分推断的方法。简化原先的LDA模型,找一个与原来不能直接求解的后验概率等价或近似的分布q,这个q要好解,一般比较简单粗暴的方法就是直接假设q中
θ,z
相互独立。
对原模型去掉
θ,z,w
之间的边,删掉
w
,这样
θ和z
就相互独立了。
模型图:
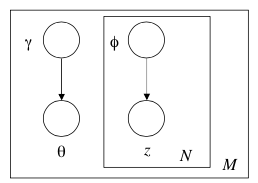
从模型中可以得出
θ,z
的分布q:
新分布中引入了两个变分参数:Dirichlet参数 γ ,多项分布参数 (ϕ1,...,ϕN) 。我们要用q来代替p,当然希望q与p越近似越好,所以对于q的确定,也就是 γ,ϕ 的选取,我们的目标是如下的一个优化问题:
这里引入了两个分布之间的KL Divergence来度量两个分布(p,q)的相似度。
然后用变分推断算法迭代得到最优的变分参数
(γ∗,ϕ∗)
,这样就等于已经确定了分布q,也就可以拿
q(θ,z|γ,ϕ)
来代替后验概率
p(θ,z|w,α,β)
。
并且在用变分推断求解上述优化问题时,作者还通过使用Jensen不等式,找到了原log似然函数
logp(|α,β)
的一个tightest lower bound:
L(γ,ϕ|α,β)
,用它来代替原log似然函数。
具体步骤见《LDA学习笔记3:变分推断算法》
M-step
这一步,我们根据E-step求出来的
(γ,ϕ)
,最大化
L(γ,ϕ|α,β)
,求解模型参数
α,β
:用拉格朗日乘数法求解参数
β
,用牛顿方法求解参数
α
。
具体步骤见《LDA学习笔记4:求解模型参数》
主要参考资料《Latent Dirichlet Allocation》















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









