







本文参考《利用python进行数据分析》的第五章 pandas入门
1 pandas数据结构介绍
pandas有两种主要的数据结构:series和DataFrame
Series:一种类似于一维数组的对象,由一组数据(各种Numpy数据类型)以及一组与之对应的数据标签(索引)组成。

第一列为索引,从0开始,第二列为数据值。
可以通过values属性获取数组的表示形式,通过index属性获取索引对象:

索引可以自己定义:

可以通过索引,选取Series中单个或一组值:

进行numpy数组运算,都会保留索引和值之间的链接:
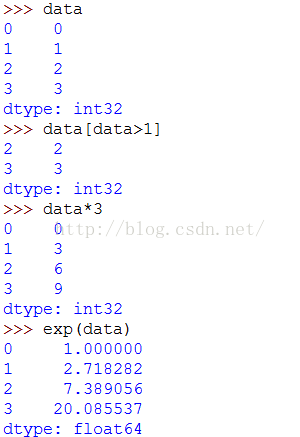



可以将Series看成是一个定长的有序字典, 它是索引值到数据值的一个映射,可以用在许多原本需要字典参数的函数中:
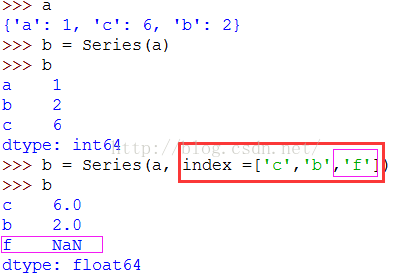
如果数据被存放在Python字典中,可以直接通过这个字典来创建Series:
如果只传入一个字典(上图),则Series中的索引就是原字典的键;如果传入index(下图),与索引匹配的值会被找出来并放到相应的位置,没有匹配的,则为NaN(缺失值)。
pandas的isnull和notnull可以检测确实数据,也可使用b.isnull(), b.notnull(),效果一样:
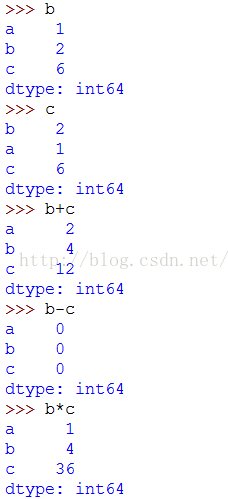
Series的最重要的一个功能是:在算术运算中汇自动对齐不同索引的数据
Series对象本身及索引都有一个name属性:

Series的索引可以通过赋值的方式就地修改(会把b.index.name删掉):

DataFrame:
DataFrame是一个表格型的数据结构,它含有一组有序的列:每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有行索引,也有列索引,可以被看做由Series组成的字典(共用同一个索引)。
构建DataFrame最常用的方法是直接传入一个由等长列表或Numpy数组组成的字典:

DataFrame会自动加上索引,且全部列会被有序排列;如果需要列按照指定顺序排列,需指定列序号:

跟Series一样,如果传入的列在数据中找不到,就会产生NaN值:

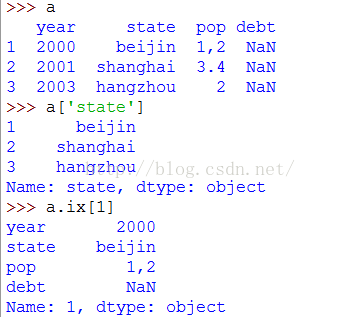
将DataFrame的列获取为一个Series,返回的Series拥有原DataFrame相同的索引,且其name属性也被相应的设置好了;行也可以通过相应的位置或名称的方式获取,比如用索引字段ix:
列可以通过赋值的方式进行修改,可以赋值一个标量或者一组值:

将列表或数组赋值给某个列时,其长度必须跟DataFrame的长度匹配。如果赋值是一个Series,就会精确匹配DataFrame的索引,所有的空位都将被填上缺失值:

为不存在的列赋值会创建出一个新列;关键字del用于删除列:

警告:通过索引方式返回的列是相应数据的视图,而不是副本,因此对返回的Series所做的任何就地修改都会反应到源DadaFrame上。
另一种常见的数据形式是嵌套字典,将他传入DataFrame,被解释为外层字典的键作为列,内层的键作为索引:

转置操作:
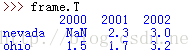
内层字典的键会被合并、排序以形成最终的索引。如果显式指定索引,则不会这样:


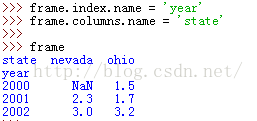
设置索引和列的名字:
索引对象

obj.index就是一个索引对象,不可修改。
















 490
490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









