






原文题目:Heap Data Structure
By Arman S. | 7 Mar 2007
原文链接:点这里
简介
本文简要介绍数据结构 堆 的概念并提供了实现源码: CHeapTree类。CHeapTree类的实现是基于一个自动增长的数组。
什么是堆
堆是一种特殊的二叉完全树。堆的一个主要特点是它以一定的偏序(a partial order)来保存所有节点[译者注:此处的偏序是指不完全的排序,堆只需要满足父节点大于两个子节点,而子节点之间没有要求]。作为一颗完全树,一层中的节点是从左到右填满的。如果一个节点没有左儿子,那么它一定没有右儿子。并且在第h层中如果存在节点,那么第h-1层必须是填满的。
以下是堆的正式定义(摘自Computer Algorithms by S. Baase and A. Van Gelder):
一个二叉树V是一个堆,当且仅当它满足以下条件:
- V从根节点至h-1层是完全树
- 所有的叶子节点只存在于h与h-1层上
- 所有到达h层叶子节点的路劲都在到达h-1层叶子节点路径的左侧
堆有两种:最大堆和最小堆。最小堆中每个节点的优先级小于或者等于它的子节点;最大堆则相反,每个节点的优先级都大于或者等于它的子节点。
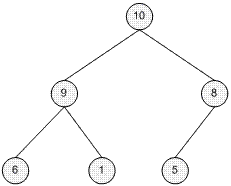
图示最大堆(左)和最小堆(右):
实现细节
CHeapTree类通过一个数组,从上至下、从左至右地保存树中的节点来实现堆。因此,上述图示中的最大堆就可以表示为10,9,8,6,1,5。在这种表示方式中,第j个节点的子节点和父节点的表达如下(假设起始索引值是0):
- 左子节点 = j*2-1
- 右子节点 = j*2 = 左子节点+1
- 父节点 = (j-1)/ 2
如果索引值越界,则该节点不存在。
代价
建堆过程中的比较次数:O(n)
删除堆的比较次数:2*n*lg(n)[译者注:删除一个元素的比较次数为2*lg[n],所以要删除所有元素需要n*2*lg(n)]
堆排序的平均时间复杂度是n*lg(n)
CHeapTree declaration(实现细节省略)
CHeapTree类实现了堆的基本操作。每个节点中排序基准的数据类型是TDATA类型。所以,如果TDATA是一种用户自定义的数据类型,需要实现<,=,>的运算符重载,即该类型的比较逻辑需由用户给出。TID是用来唯一表示一个节点的值。
默认情况下,CHeapTree是一个最小堆即TDATA中最小值具有最高的排序优先权。如果需要一个最大堆,将TDATA类型的比较运算符的逻辑倒置即可。
如何使用
使用该CHeapTree类很简单,可以如下所示:















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









