






前面所介绍的KNN算法可以实现多分类任务,但是它最大的缺点就是无法给出数据的内在含义 。决策树的主要优势就是在于数据形式非常容易理解。
决策树的一个重要任务就是为了数据中所蕴含的知识信息,因此决策树可以使用不熟悉的数据集合,并从中提取到一系列规则,在这些机器根据数据创建规则时,就是机器学习的过程。
优点: 计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。
缺点: 可能会产生过拟合问题
熵: 信息的期望值
python代码分析
step1 计算给定数据的熵
from math import log
def calShannonEnt(dataset):
#dataset 为list 并且里面每一个list的最后一个元素为label
# 如[[1,1,'yes'],
# [1,1,'yes'],
# [1,0,'no'],
# [0,0,'no'],
# [0,1,'no']]
numEnt = len(dataset) #获得list的长度 即实例总数 注(a)
labelcounts={} # 创建一个字典,来存储数据集合中不同label的数量 如 dataset包含3 个‘yes’ 2个‘no’ (用键-值对来存储)
for featVect in dataset: # 对数据集合的每一个样本进行for遍历
currentlabel = featVect[-1] # 获得样本的标签
if currentlable not in labelcounts.keys(): # 如果当前标签在字典键值中不存在
labelcounts[currentlabel]= 0 # 初值
labelcounts[currentlabel] += 1 # 若已经存在 该键所对应的值加1
shannon = 0.0
for key in labelcounts:
prob = float(labelcounts[key])/numEnt
shannonEnt -= prob*log(prob,2)
return shannonEnt注
(a)如果 dataset为矩阵时:
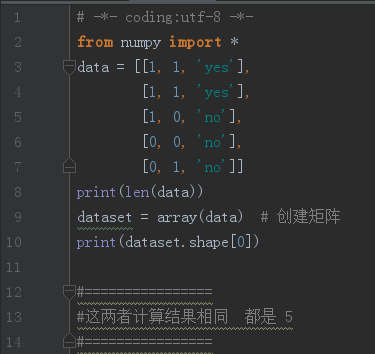
(b)我们可以创建一个例子来验证一下
def creatdata():
data = [[1,1,'yes'], # 特征和标签
[1,1,'yes'],
[1,0,'no'],
[0,0,'no'],
[0,1,'no']]
labels=['no surfacing','flippers'] #属性值 Attributes
return data,labels 输出:
0.9709505944546686
step 2 计算信息增益 (判断哪个属性的分类效果好)
def choseBestFeature(dataset): # 定义函数 选择分类能力最好的属性
numFeature = len(dataset[0])-1 # 取出list中的第一个元素 再取长度-1 就为属性的个数
baseEntropy = calShannonEnt(dataset) # 调用函数计算熵 Entropy(S)
bestGain = 0.0
bestfeature = -1 # 为属性的索引值。由于从0开始。所以初始值设为-1
for i in range(numFeature):
featList = [example[i] for example in dataset] # 注(a)
uniqueVals = set(featList) # 在这里作用相当于matlab的 unique() 去除重复元素 注(b)
newEntropy = 0.0
for value in uniqueVals:
subdataset = splitdataset(dataset,i,value) # 调用函数返回属性i下值为value的子集
prob = len(subdataset)/float(len(dataset))
newEntropy += prob * calShannonEnt(subdataset) # 计算每个类别的熵
Gain = baseEntropy - newEntropy # 求信息增益
if (Gain>bestGain):
bestGain = Gain
bestfeature = i
return bestfeature # 返回分类能力最好的属性索引值
def splitdataset(dataset,attribute,value): # 划分数据集函数
retdataset = [] # 注(c)
for feat in dataset:
if (feat[attribute]==value): # 将符合特征的数据抽取出来 比如 属性wind={weak,strong} 分别去抽取: weak多少样本,strong多少样本
reduceFeatVec = feat[:attribute] # 0-(attribute-1)位置的元素
reducedFeatVec.extend(feat[attribute+1:]) # 去除了 attribute属性
retdataset.append(reducedFeatVec) # 注(d) extend() 和 append()区别
return retdataset # 返回 attribbute-{A} 注
(a) [example[i] for example in dataset] 返回 dataset所有元素 中的 第1元素 并且为list、

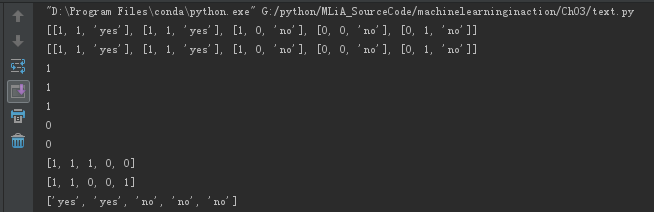
(b)
python中的集合(set)数据类型,与列表类型相似,唯一不同的是 set类型中元素不可重复
(c)
python语言不考虑内存分配问题,该语言在函数中传递的列表的引用,在函数内部对列表对象的修改,将会影响该列表的整个生存周期。为了消除这个不良影响,我们需要在函数的开始生命一个新列表对象。
(d)list的append() 和extend()的区别
前者:要添加的元素作为list的元素添加到尾部
后者:扩展list。 序列的元素逐个添加到list的尾部

step3 递归构建决策树
def creatTree(dataset, attribute):
classlabel = [example[-1] for example in dataset] # 获得标签list
if classlabel.count(classlabel[0]) == len(classlabel):
return classlabel[0] # 注(a)
if len(dataset[0]) == 1:
return majorityCnt(classlabel) # 注 (b)
bestFeat = choseBestFeature(dataset) #分割数据 返回索引值
bestFeatlabel = attribute[bestFeat] # 获得最佳属性
mytree = {bestFeatlabel:{}} # 创建 树 字典,存储树的信息 最佳属性为keys,
del(attribute[bestFeat]) # 一定要有 否则会出错!!!注(c)
featValues = [example[bestFeat] for example in dataset]
uniqueVals = set(featValues)
for value in uniqueVals:
sublabels = attributes[:] # 相当于复制。 之所以这样做的原因是 参考上面的 注(c)
mytree[bestFeatlabel][value] = creatTree(splitdataset(dataset,bestFeat,value). sublabels)
return mytree
def majorityCnt(classlist):
classcount={}
for vote in classlist:
if vote not in classcount.keys():
classcount[vote] = 0
classcount[vote] += 1
sortedclasscount = sorted(classcount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedclasscount[0][0] 注
(a) 类别完全相同,返回相同标签, 停止继续划分
Python count() 方法用于统计字符串里某个字符出现的次数.
比如:
classlabel = [1,1,1,1,1]
则:classlabel.count(classlabel[0])=5
(b) 如果属性值为空 遍历完所有特征是返回出现次数最多的 (调用 majorityCnt())
(c)
如果没有这一句,结果为:

加上这一句:

原因:
因为在调用splitdataset()函数之后,属性A已经被减去,比如属性原来的位置1 变为了位置0.
假如 在第一次调用时 返回索引值0,第二次还是返回索引值0, 如果不del这一个属性(比如说根属性),下次还是输出同样的属性。
总结
决策树的核心代码应经分析完毕,但是可视化不好,而python对数据的可视化非常好,所以下节课将学习python怎样去可视化 决策树















 405
405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









