









此文是斯坦福大学,机器学习界 superstar — Andrew Ng 所开设的 Coursera 课程:Machine Learning 的课程笔记。力求简洁,仅代表本人观点,不足之处希望大家探讨。
课程网址:https://www.coursera.org/learn/machine-learning/home/welcome
Week 2:Linear Regression with Multiple Variables笔记:http://blog.csdn.net/ironyoung/article/details/47129523
Week 3:Logistic Regression & Regularization
Logistic Regression
- 对于分类问题而言,很容易想到利用线性回归方法,拟合之后的 h θ (x)>0.5 则为True,其余为False.
- 但是线性回归有一个问题,拟合出的值都是离散的,范围不确定。为了方便分析,我们希望将拟合出的值限制在0~1之间。因此,出现了逻辑回归。
- 逻辑回归的模型是一个非线性模型:sigmoid函数,又称逻辑回归函数。但它本质上又是一个线性回归模型,因为除去sigmoid映射函数关系,其他的步骤,算法都是线性回归的。
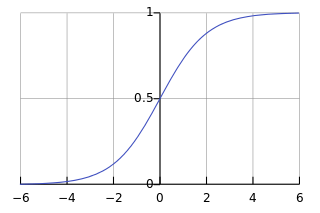
- sigmoid函数(或,逻辑回归函数):
g(z)=1/(1+e −z )
。其函数图像为:
这个函数的特征非常明显
- 函数值一直在0~1范围内;
- 经过 (0,0.5) 点。这个很容易作为区分0,1类的分界线。
- 逻辑回归中,对于原本线性回归中拟合而成的hypothesis函数,需要经过sigmoid函数的修饰:
h θ (x)=θ T x⇛h θ (x)=g(θ T x)
此时, h θ (x) 的含义发生了变化, h θ (x)=P(y=1|x;θ) 。成为
- ”the probability that y=1, given x, parameterized by θ ”
- 因此有, P(y=0|x;θ)+P(y=1|x;θ)=1
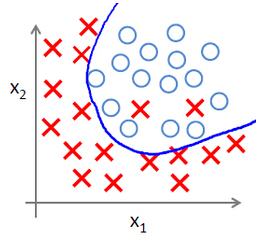
- Decision Boundary。表示的是 hypothesis 函数确定之后,划分数据分类的界限,并不一定可以百分百区分数据集,只是函数的属性之一。下图蓝色曲线即为某个 Desicision Boundary。
Cost Function
回忆线性回归的 cost function,我们在其中插入 cost 函数的概念: J(θ 0 ,θ 1 )=12m ∑ i=1 m (h θ (x (i) )−y (i) ) 2 =1m ∑ i=1 m cost(h θ (x (i) ),y (i) )=1m ∑ i=1 m cost(h θ (x),y)
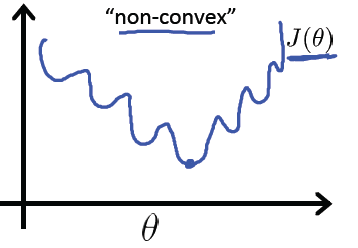
完全照搬线性回归的 cost function 到逻辑回归中,因为sigmoid函数的非线性,会造成 J(θ) 取值的不断震荡,导致其是一个非凸形函数(non-convex)。表示在“ J(θ)—θ ”二维图中如下:
- 我们需要构造一种新的 cost 函数。出发点为:
- 当 y=1 时,若hypothesis函数拟合结果为0,即为“重大失误”,cost 趋于无穷大;
- 当 y=0 时,若hypothesis函数拟合结果为1,即为“重大失误”,cost 趋于无穷大;
构造的新 cost 函数:
cost(h θ (x),y)={−log(h θ (x)),y=1−log(1−h θ (x)),y=0
如果进一步合并,可以得到最终逻辑回归的cost函数。并且值得指出的是,代入这个cost函数通过梯度下降法得到的 θ 更新函数依然成立:cost(h θ (x),y)=−ylog(h θ (x))−(1−y)log(1−h θ (x))
θ j :=θ j −α1m ∑ i=1 m [(h θ (x (i) )−y (i) )x (i) j ]
梯度下降法的优化
- 对于梯度下降法的优化有很多,但是都需要 J(θ) 与 ∂J(θ)∂θ j 的代码。
- 以此为基础的对于梯度下降法的优化(视频中都没有具体介绍,有兴趣的同学可以点击链接)有:
- 这些优化方法的特点也很一致:
- 不需要人为选择 α ,自适应性
- 更复杂,更慢
- 这里提到了两个MATLAB的非线性优化函数:
- optimset:创建或编辑一个最优化参数选项。具体调用在MATLAB中 help optimset 命令查看;
- fminunc:最小值优化。具体调用在MATLAB中 help fminunc 命令查看;
- 个人建议:Ng在优化这一部分讲的过于简略,基本等于什么都没说……还是要根据这几个方法名称在使用时搜索更多。
one vs. all (one vs. rest)
- 如果需要进行多类的分类,需要一种精妙的修改,使得两类的分类问题得以适用于多类的分类。
- 现已知有n类样本需要区分开(1,2,3,……);
- 以原1类为新1类,剩余的原2,3,……作为新2类。原本的多类问题变成了二类问题, h (1) θ (x)=P(y=1|x;θ) ;
- 以原2类为新1类,剩余的原1,3,……作为新2类。再分类, h (2) θ (x)=P(y=2|x;θ) ;
- …… h (i) θ (x)=P(y=i|x;θ) ;
- 对于任意一个
x
而言,如何分辨是哪一类呢?于是,求出所有的
h (1) θ (x),h (2) θ (x),h (3) θ (x),……,h (n) θ (x) ,值最大对应的 i (表示y=i 的概率最大)即为 x 的所属分类
- 如果需要进行多类的分类,需要一种精妙的修改,使得两类的分类问题得以适用于多类的分类。
Regularization(正则化)
- 拟合会产生三种情况:
- underfitting(欠拟合)=high bias,大部分训练样本无法拟合
- overfitting(过拟合)=high variance,为了拟合几乎每一个训练样本。导致拟合函数极为复杂,易产生波动,泛化(generalize)能力差,虽然训练样本几乎百分百拟合,但是测试样本很可能因为极大波动而极少拟合成功
- just right,对于训练样本,拟合得不多不少刚刚好,并且泛化到测试样本拟合效果同样较好
- 欠拟合,比较好解决,创造并引入更多的特征即可。例如:对于
x,y 而言,可以引入 x 2 ,y 2 ,xy 等等新的特征 - 过拟合,则比较复杂。可用的方法有两个:
- Reduce number of features,降维(PCA?)
- Regularization,正则化。保持所有的特征数量不变,而去改变特征前的度量单位 θ j (若 θ j 趋于0,则此特征可视为无影响)
- 解决过拟合的正则化方法,因此需要引入全新的优化目标到 cost function 中。原先的 cost function 只是希望适合拟合更为接近,现在还需要使得特征前的度量单位
θ j
的最小。因此有:
J(θ 0 ,θ 1 )=12m [∑ i=1 m (h θ (x (i) )−y (i) ) 2 +λ∑ i=1 m θ 2 j ]
正则化方法处理之后, ∂J(θ)∂θ j 发生对应变化,因此我们有:
θ j :=θ j −α[(1m ∑ i=1 m (h θ (x (i) )−y (i) )x (i) j )+λm θ j ]:=θ j (1−αλm )−α1m ∑ i=1 m (h θ (x (i) )−y (i) )x (i) j
若 λ 非常大(例如 10 10 ),则正则化方法会导致结果 underfitting。这也很好理解,因为优化目标中有使得 λ∑ i=1 m θ 2 j 尽可能小,这样会导致 θ 全部趋于 0。一般来说, α,λ,m>0 ,所以 (1−αλm )<1 ,常见使其取值0.99 左右
- 拟合会产生三种情况:
Regularization for Normal Equation
- 课程视频中缺少证明,因此我们仅需掌握结论使用即可
对于 Week 2 中的Normal Equation方法,原本需要求解的方程 θ=(x T x) −1 x T y 做一个小小的改动:
θ=(x T x+λ⎛ ⎝ ⎜ ⎜ ⎜ ⎜ ⎜ 00⋮0 01⋮0 ……⋱… 00⋮1 ⎞ ⎠ ⎟ ⎟ ⎟ ⎟ ⎟ ) −1 x T y
若样本拥有n个特征,则 ⎛ ⎝ ⎜ ⎜ ⎜ ⎜ ⎜ 00⋮0 01⋮0 ……⋱… 00⋮1 ⎞ ⎠ ⎟ ⎟ ⎟ ⎟ ⎟ 表示的是(n+1) * (n+1)维的对角矩阵,除了(0, 0)取值为 0,其余对角位置取 1。
- non-invertibility:非不可逆性……好拗口,意思就是对于原本的 (x T x) 矩阵可能会出现不可逆的情况。但是,对于正则化之后的矩阵 (x T x+λ⎛ ⎝ ⎜ ⎜ ⎜ ⎜ ⎜ 00⋮0 01⋮0 ……⋱… 00⋮1 ⎞ ⎠ ⎟ ⎟ ⎟ ⎟ ⎟ ) 一定是可逆的(未提供证明)。















 941
941











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









