






<防止Notion某一天打不开做的简单备份,日期2022/09/28>
💡 以下笔记来自 Bilibili - 黑马程序员3天快速入门python机器学习
机器学习算法分类
监督学习
目标值:离散型的数据、类别 - 分类问题
k-近邻算法、贝叶斯分类、决策树、随机森林、逻辑回归
目标值:连续型的数据 - 回归问题
线性回归、岭回归
无监督学习
目标值:无
聚类 k-means
机器学习开发流程
1)获取数据
2)数据处理
3)特征工程
4)机器学习算法训练 - 模型
5)模型评估
6)应用
回归:就是在历史数据特征集的基础上做拟合并预测,属于定量输出
分类:字面意思,属于定性输出
学习阶段可以用的数据集:
1)sklearn
2)kaggle
3)UCI
Scikit-learn工具介绍
sklearn数据集的加载
sklearn.datasets
load_* 获取小规模数据集
fetch_* 获取大规模数据集
加载sklearn小数据集
鸢尾花数据集(小)
sklearn.datasets.load_iris()
加载sklearn大数据集
20类新闻文本数据集(大)
sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
数据集的返回值
datasets.base.Bunch(继承自字典)
dict[“key”] = values(用字典方式获取键值对)
bunch.key = values(用圆点方式获取键值对)
数据集的划分
训练数据:用于训练,构建模型
测试数据:在模型检验时使用,用于评估模型是否有效
测试集 20%~30%
数据集划分函数sklearn.model_selection.train_test_split(arrays, *options)
需要传入的参数:
- x 数据集的特征值
- y 数据集的标签值
- test_size(非必填)测试集的大小,0到1的浮点数,默认取0.2
- random_state(非必填)随机数种子,指数据集里、将哪些数据作为训练集、哪些数据作为测试集,不同的种子会造成不同的采样结果。
- return 返回值,返回值是有顺序的,可用如下变量名命名返回值,
训练集特征值(x_train),测试集特征值(x_test),训练集目标值(y_train),测试集目标值(y_test)
特征工程
使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
pandas:数据清洗、处理 → sklearn:特征工程
特征抽取/特征提取/特征值化
什么玩意儿能被当作“特征”?怎么样让这种特征能被计算机识别?
- 字典(特征离散化)
- 文本
- 图像(深度学习)
特征提取API:sklearn.feature_exrtraction
字典特征提取
文本特征提取
标准化、归一化
将所有的数据映射到同一尺度,并且无量纲化。
• 最值归一化*(normalization)*,把所有数据映射到0~1之间
X s c a l = x − x m i n x m a x − x m i n X_{scal}=\frac{x-x_{min}}{x_{max}-x_{min}} Xscal=xmax−xminx−xmin
API:
from sklearn.preprocessing import MinMaxScaler
transfer = MinMaxScaler() # 归一化
• Z-score(standardization),也称为标准化分数,这种方法根据原始数据的均值和标准差进行标准化,即均值为0,标准差为1。
它表示的是原始值与均值之间差多少个标准差,是一个相对值,有去除量纲的作用。
X s c a l = X i − μ σ X_{scal}=\frac {X_ {i} - \mu} {\sigma} Xscal=σXi−μ
API:
from sklearn.preprocessing import StandardScaler
transfer = StandardScaler() # 标准化
降维
这里的“降维”指的是“降低特征的个数”,指在某些限定条件下,降低特征个数、从而得到一组“不相关”的主变量的过程。
降维的两种方式:特征选择和主成分分析(可以理解为一种提取特征的方式)
-
特征选择
-
Fliter过滤式(通过关联性去除冗余数据)
方差选择法:低方差特征过滤。如果在一组数据集中存在一种特征,它们的方差很低,说明这种特征比较集中,可以将其过滤来达到降维的目的。
sklearn.feature_selection.VarianceThreshold(threshold=0.0)VarianceThreshold.fit_transform(X)
X是array格式的数据,
返回值是删除了方差低于threshold的数据。 -
相关系数:衡量的是特征与特征之间的相关程度。当一组数据集中的两种特征有较强的相关性时,说明可能存在冗余,进一步处理后可以达到降维的目的。
皮尔逊相关系数 (-1 < r < 1)
r>0正相关,r<0负相关,|r|=1表示完全相关,|r|=0表示完全不相关,
|r|越接近1表示相关性越密切,|r|越接近0表示相关性越弱。相关性一般可按三级分类:0.4 0.7
c低度相关(|r| < 0.4)、显著性相关(0.4 ≤ |r| < 0.7)、高度线性相关(|r| ≥ 0.7)from scipy.stats import pearsonrpearsonr(x, y)输入参数x,y都是array格式的数据,
返回值是皮尔逊相关系数和p值。当相关性很高时可以进行的操作:
- 选取其中一个
- 加权求和
- 主成分分析
-
Embedded嵌入式
决策树、正则化、深度学习
-
-
主成分分析(PCA,Principal Component Analysis)**
进行降维、并且尽可能地保留更多的信息。
以右侧图片为例,把二维坐标系下的5个点降维到一维坐标轴下。
若选取x轴为一维坐标轴则会损失2个点。选取蓝色直线作为一维坐标轴则不会损失数据点,并且应当选取合适的直线、使得投影距离总和最小。
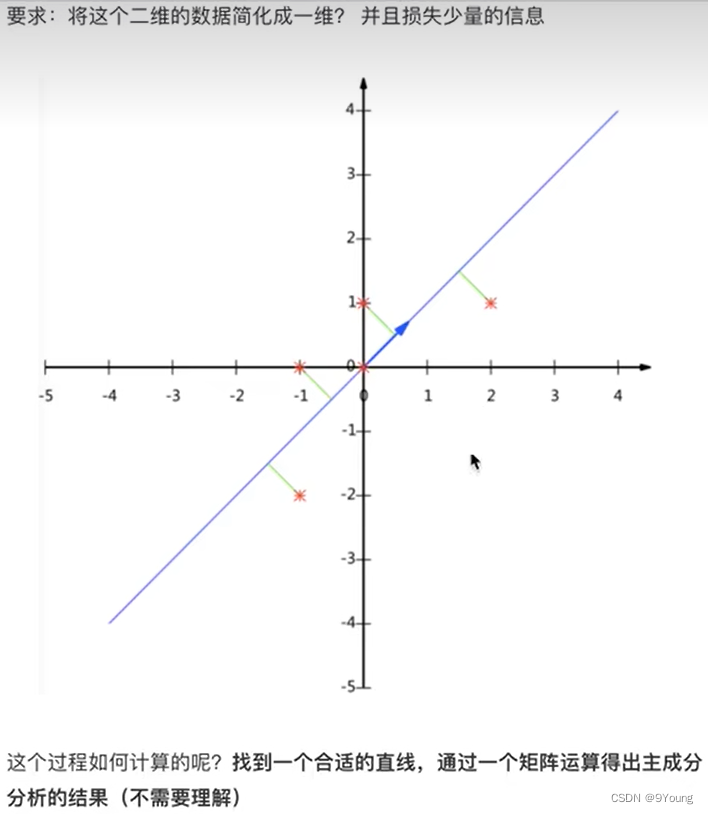
将原有的5个点乘以一个矩阵,得到5个一维的数据点。
sklearn.decomposition.PAC(n_components=None)
传入的参数n_components:
当其是小数时,表示保留百分之多少的信息。n_components=0.95 保留95%的信息
当其是整数时,表示减少到多少特征。 n_components=2 保留两个特征(降到2维)
PCA.fit_transform(X)
X是array格式的数据
返回值是降维后的array格式数据
分类算法
转换器
想一下之前做的特征工程的步骤?
- 1、实例化 (实例化的是一个转换器类*(Transformer)*)
- 2、调用fit_transform(对于文档建立分类词频矩阵,不能同时调用)
fit和transform的区别


我们把特征工程的接口称之为转换器,其中转换器调用有这么几种形式(以标准化为例)
- fit_transform()
- fit() - 计算每一列的平均值μ、标准差σ
- transform() - (x - μ) / σ
进行最终的转换
fit(x,y)传两个参数就是有监督学习的算法,
fit(x)传一个参数就是无监督学习的算法,比如降维、特征提取、标准化。
ss = StandardScaler()
X_test = ss.transform(X_test) transform() - 数据标准化,通过找中心和缩放等实现标准化。
X_train = ss.fit_transform(X_train) fit_transform() - 先拟合数据,再标准化
到了这里,我们似乎知道了两者的一些差别,就像名字上的不同,前者多了一个fit数据的步骤,那为什么在标准化数据的时候不适用fit_transform()函数呢?
原因如下:
为了数据标准化(使特征数据方差为1,均值为0),我们需要计算特征数据的均值 μ μ μ和方差 σ 2 σ^2 σ2,再使用下面的公式进行标准化:
X s c a l = X i − μ σ X_{scal}=\frac {X_ {i} - \mu} {\sigma} Xscal=σXi−μ
我们在训练集上调用fit_transform(),其实找到了均值 μ μ μ和方差 σ 2 σ^2 σ2,即我们已经找到了转换规则,我们把这个规则利用在训练集上,同样,我们可以直接将其运用到测试集上(甚至交叉验证集),所以在测试集上的处理,我们只需要标准化数据而不需要再次拟合数据。
用一幅图展示:

估计器(estimator)**
步骤(与转换器类似):
1.实例化一个estimator
2.调用fit方法计算
estimator.fit(x_train, y_train) —— 调用完毕、模型生成
3.模型评估:
-
直接对比真实值和预测值
estimator.predict()y_predict = estimator.predict(x_test) # 将测试数据使用模型进行预测 y_test == y_predict # 将模型预测值与测试集数据对比,返回一个布尔值 -
计算准确率
estimator.score()accuracy = estimator.score(x_test, y_test) # 查看测试集分数(准确率)
KNN算法
API:
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, algorithm=’auto’)
模型选择与调优
交叉验证 (Cross Validation):为了让被评估的模型更加准确可信
以 五折交叉验证 为例,将拿到的训练集数据均分为5个小数据集,选取1个为验证、其余4个为训练,然后经过5次(组)的测试,每次都更换不同的验证集。即得到5组模型的结果,取平均值作为最终结果。

交叉验证只是在给定的参数下得出更好的模型结果,那么怎么选择/调优参数呢?其中一个方法是 网格搜索 。
超参数搜索 - 网格搜索 (Grid Search)
超参数:模型中需要手动指定的参数,例如KNN算法中的K值
手动遍历所有可能的参数是十分繁琐的,所以需要对模型预设几种超参数组合(网格),每种超参数都采用交叉验证来评估、最后选出最优参数组合建立模型。是一种穷举类型的调优方法。
API:
sklearn.model_selection.GridSearchCV(estimator, param_grid=None, cv=None)
- 作用:对估计器的指定参数进行详尽搜索
- estimator:估计器
- param_grid:估计器参数集(字典格式 - KNN算法K值待选1,3,5.其格式为{”n_neighbors”:[1, 3, 5]}
- cv:指定几折交叉验证
可以查看的属性:
best_params_:最佳参数
best_estimator_:最佳估计器
cv_results_:交叉验证结果
best_score_:交叉验证最佳准确率
朴素贝叶斯算法
API:
sklearn.naive_bayes.MultinomialNB(alpha=1.0)
Multinomial 多项的,多项式
决策树算法
如何高效、自动地对 if-else(决策) 进行排序(权重)
API:
sklearn.tree.DecisionTreeClassifier(criterion=’gini’,max_depth=None,random_state=None)
-
criterion:默认是’gini’系数,也可以选择信息增益的熵’entropy’
-
max_depth:树的深度大小
默认会尽可能细地拟合、但运算量会很大,且泛化能力较差(过于拟合训练数据、在训练集上很好,但测试集上不行)
-
random_state:随机数种子
决策树可视化:
tree.export_graphviz(estimator,out_file='tree.dot’,feature_names=[‘’,’’])
该函数能够导出.dot文件,使用graphviz能够将.dot转换成图像
集成学习方法 (Ensemble Learning)
数据→独立学习→预测→投票
通过建立几个模型的组合来解决单一问题。工作原理是生成多个分类器/模型,各自独立地做出学习和预测。这些预测结合成组合预测,因此优于单分类预测。
集成学习内部不必是同样的模型,决策树和神经网络可以共存于一个系统中。
随机森林算法
API:
sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True, random_state=None, min_samples_split=2)
- n_estimators:integer,optional(default = 10)森林里的树木数量
- criteria:string,可选(default =“gini”)分割特征的测量方法
- max_depth:integer或None,可选(默认=无)树的最大深度
可以取 5,8,15,25,30 - max_features="auto”,每个决策树的最大特征数量
- If “auto”, then max_features=sqrt(n_features).
- If “sqrt”, then max_features=sqrt(n_features) (same as “auto”).
- If “log2”, then max_features=log2(n_features).
- If None, then max_features=n_features.
- bootstrap:boolean,optional(default = True)是否在构建树时使用放回抽样
- min_samples_split:节点划分最少样本数
- min_samples_leaf:叶子节点的最小样本数
超参数:n_estimator, max_depth, min_samples_split,min_samples_leaf
回归与聚类算法
线性回归
利用回归方程(函数),对一个/多个自变量(特征值)和因变量(目标值)之间的关系进行建模。
h ( w ) = w 1 x 1 + w 2 x 2 + w 3 x 3 + … + b = w T x h(w)=w_{1} x_{1}+w_{2} x_{2}+w_{3} x_{3}+ \ldots+\mathrm{b}=w^{T} x h(w)=w1x1+w2x2+w3x3+…+b=wTx
其中, w = ( b w 1 w 2 ) , x = ( 1 x 1 x 2 ) w=\left(\begin{array}{c}b \\w_{1} \\w_{2}\end{array}\right), x=\left(\begin{array}{c}1 \\x_{1} \\x_{2}\end{array}\right) w=⎝ ⎛bw1w2⎠ ⎞,x=⎝ ⎛1x1x2⎠ ⎞,
w w w 叫权重 (weight) /回归系数/模型参数
b b b 叫偏置 (bias)
“线性”模型分两种:
自变量最高次数为1 - h ( w ) = w 1 x 1 + w 2 x 2 + w 3 x 3 + … + b h(w)=w_{1} x_{1}+w_{2} x_{2}+w_{3} x_{3}+ \ldots+\mathrm{b} h(w)=w1x1+w2x2+w3x3+…+b
自变量数目为1 - h ( w ) = w 1 x 1 + w 2 x 1 2 + w 3 x 1 3 + … + b h(w)=w_{1} x_{1}+w_{2} x_{1}^2+w_{3} x_{1}^3+ \ldots+\mathrm{b} h(w)=w1x1+w2x12+w3x13+…+b(即多项式拟合,多项式拟合也是一种线性模型)
目标:求模型参数
损失函数
损失的总和,目的就是把这个函数的值尽可能变小。
J ( w ) = ∑ i = 1 m ( y ( i ) − w T ( x ) ( i ) ) 2 J(w)=\sum_{i=1}^{m}(y^{(i)}-w^{T}(x)^{(i)} )^2 J(w)=i=1∑m(y(i)−wT(x)(i))2
y ( i ) y^{(i)} y(i)为第i个训练样本的真实值
w T ( x ) ( i ) w^{T}(x)^{(i)} wT(x)(i)为第i个训练样本特征值组合预测函数
上面的公式又叫 最小二乘法(ordinary least squares),
“最小 (least) ”指的是损失函数值最小,因为是每一项的损失(偏差)的总和积累起来的,当损失(偏差)总和最小时,整个模型就最精确。
“二乘 (squares) ”指的是平方,利用平方避免正负值抵消,相当于求出偏差的“距离”。
如何去减少这个损失,使我们预测的更加准确些? - 正规方程、梯度下降
正规方程 (Normal Equation)
w = ( X T X ) − 1 X T y w=\left(X^{T} X\right)^{-1} X^{T} y w=(XTX)−1XTy
好处:直接求出精确最优解
坏处:特征多的时候算死你都算不出来
与求二次函数 y = a x 2 + b x + c y=ax^2+bx+c y=ax2+bx+c 求最小值、直接求导找到最低点类似,正规方程也是通过数学方法直接找到 θ \theta θ 的最小值矩阵。
因为这种方法很正规,所以叫正规方程。
但是它没法解决过拟合问题。
正规方程类似求解析解(它一定是对的),而梯度下降类似求数值解(能用就行)。
梯度下降 (Gradient Descent)
API:
正规方程
sklearn.linear_model.LinearRegression(fit_intercept=True)
- fit_intercept:是否计算偏置
可以查看的属性:
LinearRegression.coef_:权重
LinearRegression.intercept_:偏置
随机梯度下降 (stochastic gradient descent,SGD)
sklearn.linear_model.SGDRegressor(loss="squared_loss", fit_intercept=True, learning_rate ='invscaling', eta0=0.01)
SGDRegressor类实现了随机梯度下降学习,它支持不同的loss函数和正则化惩罚项来拟合线性回归模型。
-
loss:损失类型,loss=”squared_loss”: 普通最小二乘法
-
fit_intercept:是否计算偏置,也就是公式里那个常数 b b b
-
learning_rate:学习率参数
- 学习率填充
- ‘constant’: 指定初始学习率为常数 eta = eta0
- ‘optimal’: eta = 1.0 / (alpha * (t + t0)) [default]
- ‘invscaling’: eta = eta0 / pow(t, power_t),power_t=0.25:存在父类当中
随着梯度的不断下降、相邻点间距越来越小。
对于一个常数值的学习率来说,可以使用learning_rate=’constant’ ,并使用eta0来指定学习率。
可以查看的属性:
SGDRegressor.coef_:权重
SGDRegressor.intercept_:偏置
如何评估线性回归模型的性能?
均方误差 (Mean Squared Error)
M S E = 1 m ∑ i = 1 m ( y ( i ) − y p r e d ) 2 MSE=\frac{1}{m}\sum_{i=1}^{m}(y^{(i)}-y_{pred})^2 MSE=m1i=1∑m(y(i)−ypred)2
y ( i ) y^{(i)} y(i)为真实值, y p r e d y_{pred} ypred为预测值
实际上就是损失函数进行了均值处理,有时候也用它来做损失函数。
欠拟合 (Underfitting):
一个假设在训练数据上不能获得更好的拟合,并且在测试数据集上也不能很好地拟合数据,此时认为这个假设出现了欠拟合的现象。(模型过于简单)
原因:从数据中学习到的特征太少。
解决方法:增加数据的特征数量。
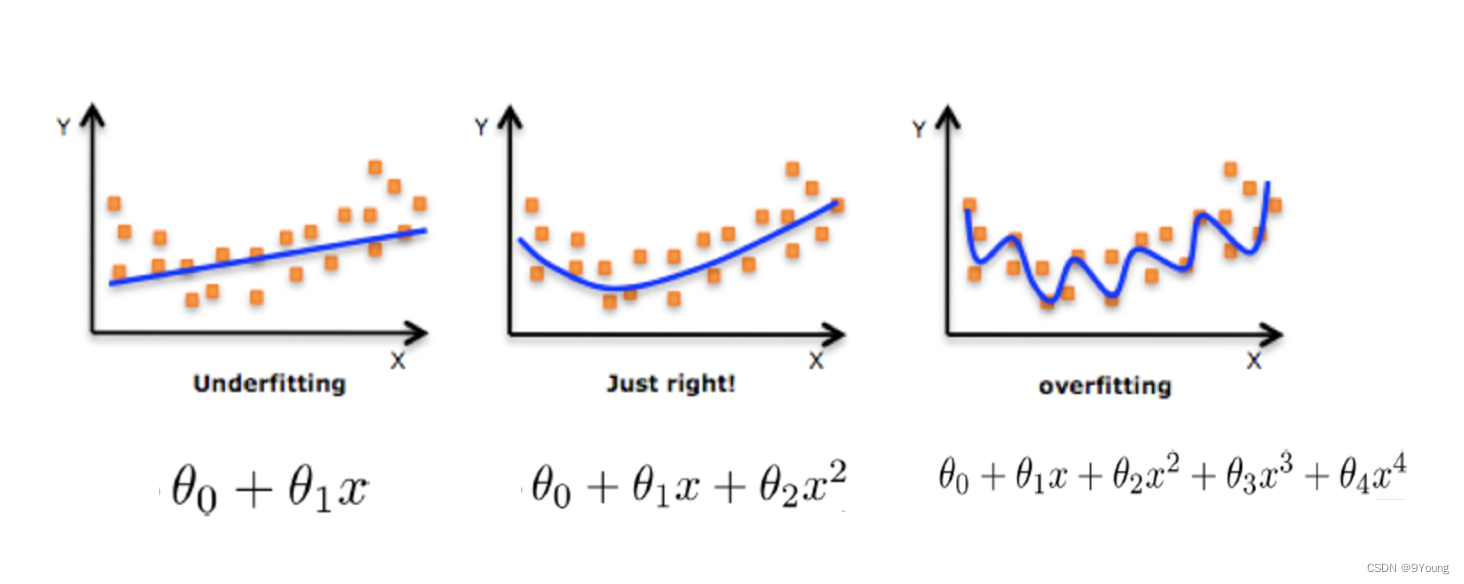
过拟合 (overfitting):
一个假设在训练数据上能够获得比其他假设更好的拟合, 但是在测试数据集上却不能很好地拟合数据,此时认为这个假设出现了过拟合的现象。(模型过于复杂)
为什么会出现过拟合现象?
数据集中会存在很多无用的特征、或者特征与目标值的关系不大。模型过于复杂是因为模型尝试去兼顾各个测试集中的数据点。
在这里针对 回归 我们选择了正则化。但是对于其他机器学习算法如分类算法来说也会出现这样的问题,除了一些算法本身作用之外(决策树、神经网络),我们更多的也是去自己做特征选择,包括之前说的删除、合并一些特征。
解决方法:正则化
L1正则化 (Least absolute shrinkage and selection operator, LASSO)
可以使得其中一些W的值直接为0,删除这个特征的影响
L2正则化 (Ridge Regression, 即岭回归)
可以使得其中一些W的都很小,都接近于0,削弱某个特征的影响。
优点:越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象。
它实质上是一种改良的 最小二乘法 ,通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得 回归系数 更为符合实际、更可靠的回归方法。
岭回归 - 一个带L2正则化的线性回归
数学原理一大堆,看不懂,不写了。
API:
sklearn.linear_model.Ridge(alpha=1.0, fit_intercept=True,solver="auto", normalize=False)
-
alpha:正则化力度,也叫 λ,取值:0~1 1~10
-
solver:会根据数据自动选择优化方法
sag:如果数据集、特征都比较大,选择该随机梯度下降优化
-
normalize:数据是否进行标准化
normalize=False:可以在fit之前调用preprocessing.StandardScaler标准化数据
可以访问的属性:
- Ridge.coef_:权重
- Ridge.intercept_:偏置
逻辑回归 (Logistic Regression)
API:
sklearn.linear_model.LogisticRegression(solver='liblinear', penalty=‘l2’, C = 1.0)
- solver:优化求解方式(默认开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数)
- sag:根据数据集自动选择,随机平均梯度下降
- penalty:正则化的种类
- C:正则化力度
另外:LogisticRegression方法相当于 SGDClassifier(loss="log", penalty=" ")
分类模型评估方法
混淆矩阵 (Confusion Matrix)
在分类任务下,预测结果(Predicted)与真实结果(Actual)之间存在四种不同的组合,构成混淆矩阵。
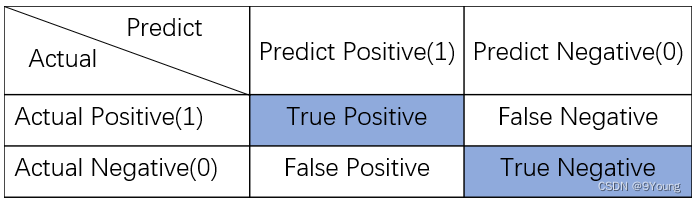
对于分类问题,一般使用混淆矩阵来分析各类别预测的结果,可视化混淆矩阵来分析预测结果从而得到调参思路。
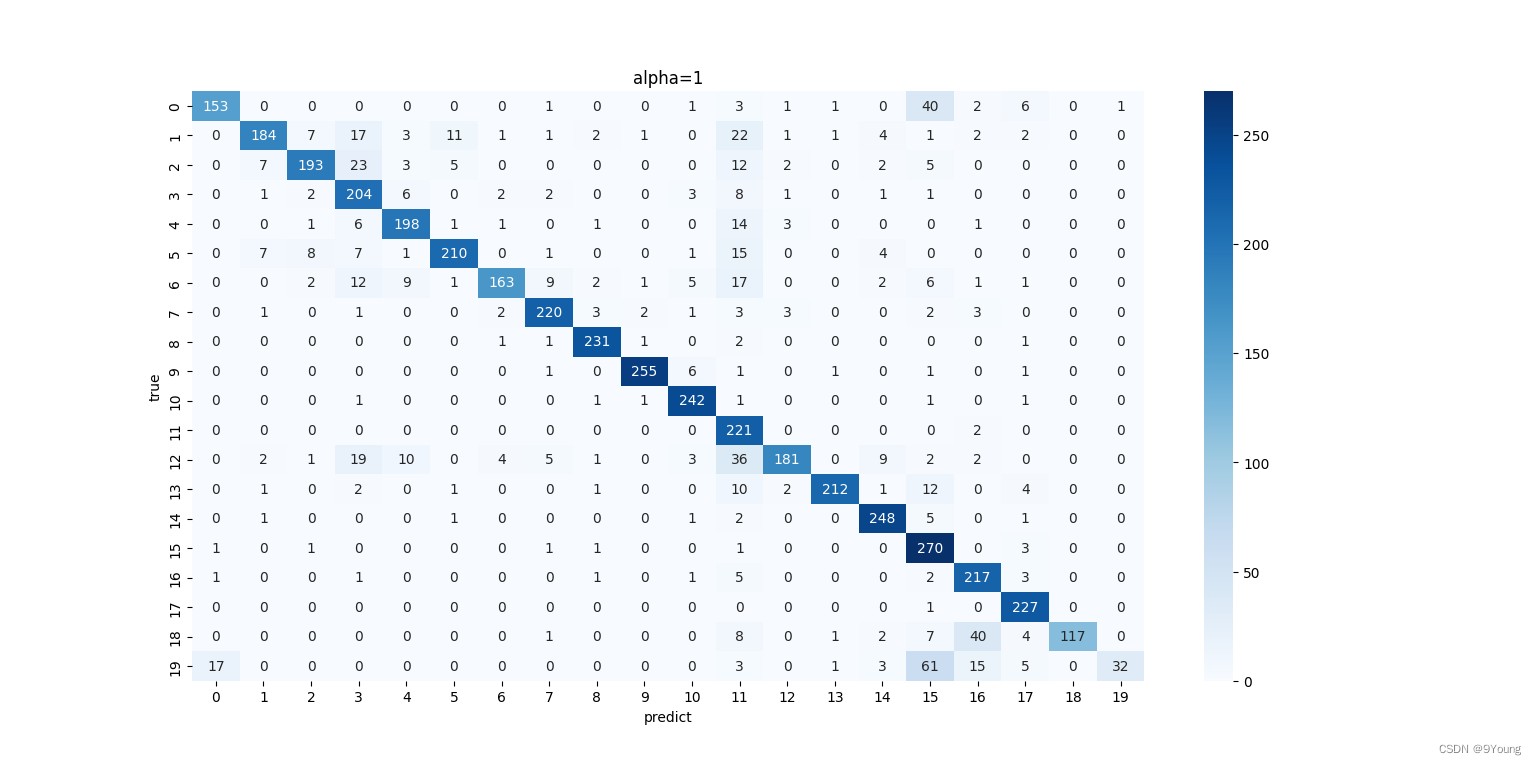
混淆矩阵同样适合多分类情况
API:
sklearn.metrics.confusion_matrix(y_true, y_pred)
可视化
import seaborn
import matplotlib.pyplot as plt
plt.figure(num=1)
ax = seaborn.heatmap(cm, annot=True, cmap="Blues", fmt="d")
ax.set_title("title")
ax.set_xlabel('predict') # x轴
ax.set_ylabel('true') # y轴
二分类评价指标:
精确率 (Precision)
p r e c i s i o n = T r u e P o s i t i v e P r e d i c t P o s i t i v e precision=\frac{True Positive}{Predict Positive} precision=PredictPositiveTruePositive
查准率,有多少阳性样本被准确预测。当精确度为100%时,说明 预测的阳性全部正确 。
召回率 (Recall)
r e c a l l = T r u e P o s i t i v e A c t u a l P o s i t i v e recall=\frac{True Positive}{Actual Positive} recall=ActualPositiveTruePositive
查全率,有多少阳性样本被正确检出。当召回率为100%时,说明 所有阳性样本都被检出 。(宁错杀、不放过)
查准率和查全率反映了分类器分类性能的两个方面。如果综合考虑查准率与查全率,可以得到新的评价指标F1测试值,也称为综合分类率。
查准率和查全率反映了分类器分类性能的两个方面。如果综合考虑查准率与查全率,可以得到新的评价指标F1测试值,也称为综合分类率。
F
1
=
2
×
p
r
e
c
i
s
i
o
n
×
r
e
c
a
l
l
p
r
e
c
i
s
i
o
n
+
r
e
c
a
l
l
F1=\frac{2 \times precision \times recall}{precision + recall}
F1=precision+recall2×precision×recall
API:(分类评估报告)
sklearn.metrics.classification_report(y_true, y_pred, labels=[], target_names=None )
- y_true:真实值
- y_pred:预测值
- labels:指定类别对应的数字,比如labels=[2, 4]
- target_names:目标类别名称,比如target_names=[”良性”, ”恶性”]
- return:每个类别精确率、召回率、F1-score、样本数
ROC曲线 (Receiver Operating Characteristic, ROC curve)
TPRate:所有真实为1的样本中、预测为1的比例(也就是召回率) T P ( T P + F N ) \frac{TP}{(TP+FN)} (TP+FN)TP
FPRate:所有真实为0的样本中、预测为1的比例(假阳性的概率) F P ( F P + T N ) \frac{FP}{(FP+TN)} (FP+TN)FP
纵轴 - TPRate
横轴 - FPRate
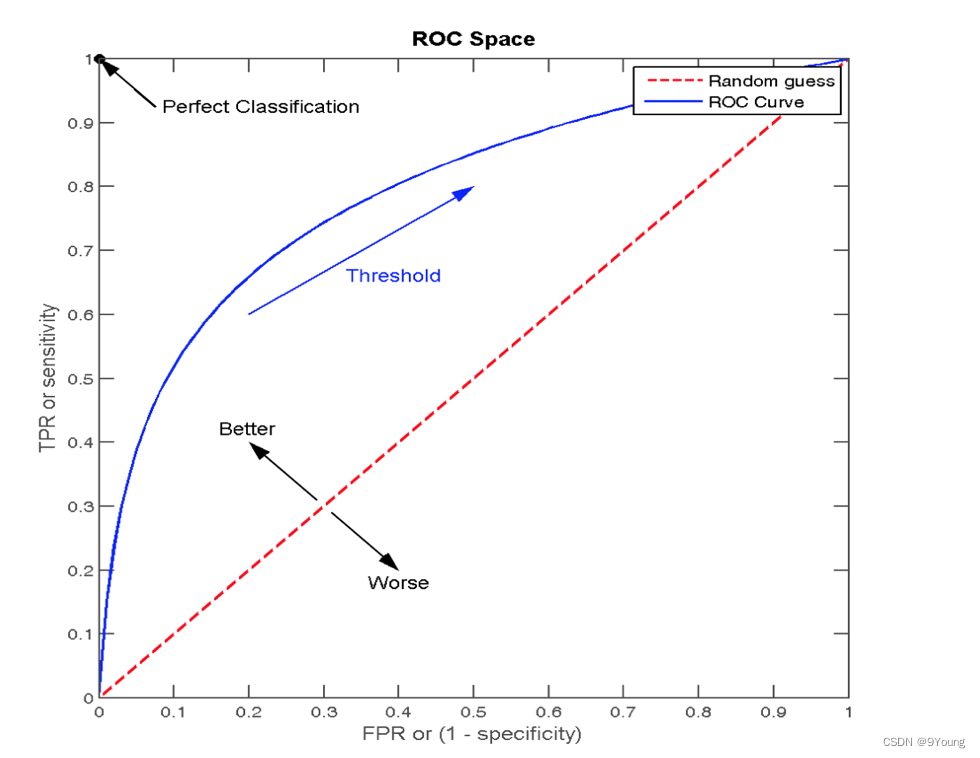
当TPRate=FPRate(图中红色虚线)时,表示不论真实类别是0还是1的样本,分类器预测为1。
也就是说,分类器现在是在瞎蒙。
当FPRate→0,TPRate→1时(蓝色实线)
AUC (Area Under Curve),表示ROC曲线下方的面积。
0.5<AUC<1,AUC=1 完美分类器、不论设定什么阈值都能完美预测。
模型保存与加载
训练完成后对参数进行保存
from sklearn.externals import joblib
joblib已在在sklearn 0.23版本后移除,重新安装joblib库即可
-
保存:
joblib.dump(estimator, 'test.pkl')dump - 序列化,estimator - 预估器,’test.pkl’ - 文件名、后缀是.pkl
-
加载:
estimator = joblib.load('test.pkl')返回值是一个预估器
K-Means算法(无监督学习)
API:
sklearn.cluster.KMeans(n_clusters=8,init=‘k-means++’)
- n_clusters:开始的聚类中心数量,即K值
- init:初始化方法,默认为’k-means ++’
- labels_:默认标记的类型,可以和真实值比较(不是值比较)
案例:k-means对Instacart Market用户聚类
聚类评估指标 - 轮廓系数 (Silhouette Coefficient)
S C i = b i − a i max ( b i , a i ) SC_{i}=\frac{b_{i-} a_{i}}{\max \left(b_{i}, a_{i}\right)} SCi=max(bi,ai)bi−ai
i i i 为数据样本点
b i b_i bi 为 i i i 到其它簇中所有样本距离的最小值
a i a_i ai 为 i i i 到自身簇中所有样本距离的平均值
S
C
i
SC_i
SCi 的范围在 -1 到 1 之间,越接近1表示聚类效果越好
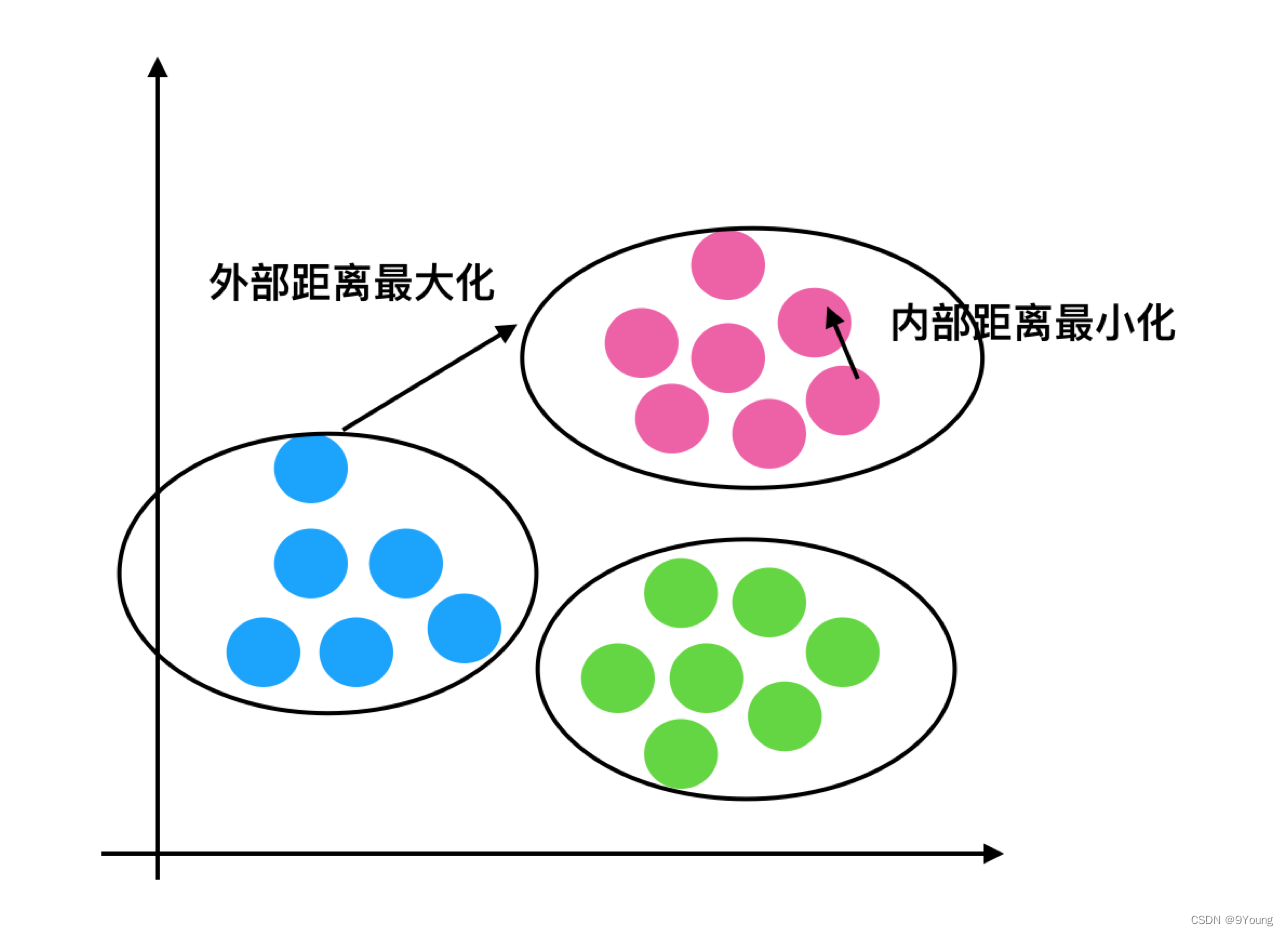
理想:簇内间距紧凑,簇间距离宽松。
S C i = 0 SC_i=0 SCi=0表示有簇重叠。
轮廓系数API:
sklearn.metrics.silhouette_score(X, labels)
- X:特征值
- labels:被聚类标记的目标值
相当于X给了几个堆、labels给了这些堆一些名字(默认是0, 1, 2, …)
目前就这么多…














 468
468











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









