







目录:
- 聚类任务
- 性能度量
- 距离计算
- 原型聚类
- 密度聚类
- 层次聚类方法
聚类任务
聚类:经典的无监督学习方法,无监督学习的目标是通过对无标记训练样本的学习,发掘和揭示数据集本身潜在的结构与规律,即不依赖于训练数据集的类标记信息。聚类则是试图将数据集的样本划分为若干个互不相交的类簇,从而每个簇对应一个潜在的类别。
聚类过程仅能自动形成簇结构,簇说对应的概念语义需要使用者来把我和命名。
聚类既可以作为一个单独过程,用于寻找数据内在的分布结构;也可以作为分类等任务的前驱过程。
聚类直观上来说是将相似的样本聚在一起,从而形成一个类簇(cluster)。那首先的问题是如何来度量相似性(similarity measure)呢?这便是距离度量,在生活中我们说差别小则相似,对应到多维样本,每个样本可以对应于高维空间中的一个数据点,若它们的距离相近,我们便可以称它们相似。那接着如何来评价聚类结果的好坏呢?这便是性能度量,性能度量为评价聚类结果的好坏提供了一系列有效性指标。
性能度量
聚类的性能度量又叫“有效性指标”;
- 簇内相似度:越高越好;
- 簇间相似度:越低越好;
性能度量分类:
- 外部指标:将聚类结果与某个“参考模型”进行比较;如:Jaccard系数、FM指数、Rand指数等


- 内部指标:直接考察聚类结果而不利于任何参考模型;如:DB指数、Dunn指数;


距离计算
距离度量dist(x,y)需要满足的一些基本性质:
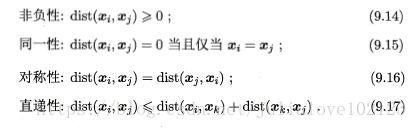
常用距离度量:

常用属性划分:
- 连续属性(数值属性):在定义域上有无穷多个可能的取值;
- 离散属性(列名属性):在定义域上是有限个取值;
距离度量中的属性需要考虑“序”:
- 无序属性:VDM

- 混合属性:闵可夫斯基距离和VDM结合

- 不同属性重要性不同:加权距离
Eg:加权闵可夫斯基距离:
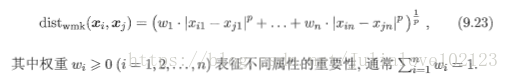
非度量距离:不一定满足距离度量的所有基本性质;
距离计算式:可使用“距离度量学习”来实现;
原型聚类
原型聚类(基于原型的聚类):算法先对原型进行初始化,然后对原型进行迭代更新求值。
k均值算法:贪心算法


学习向量量化:数据样本带有类别标记;

高斯混合聚类:采用概率模型来表达聚类原型;



密度聚类
密度聚类(基于密度的聚类):从样本密度的角度来考察样本之间的可连接性,并基于可连接性不断扩张聚类簇来获得最终的聚类结果。
DBSCAN密度聚类算法:

DBSCAN中的“簇”:由密度可达关系到处的最大的密度相连样本集合。即就是:

DBSCAN算法:

层次聚类方法
层次聚类:试图在不同层次上对数据集进行划分,从而形成树形的聚类结构。
数据集的划分:“自底向上”的聚合策略、“自顶向下”的分拆策略;
AGNES:自底向上聚合策略:先将每个样本看做一个初始聚类簇,然后再每一步中找出距离最近的两个聚类进行合并,知道达到预设的聚类个数。
距离计算:
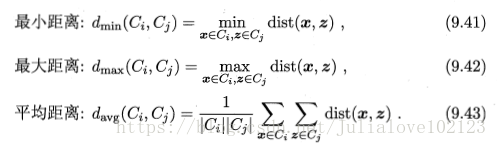
AGNES 算法:

------*-*---------------------------------------------------------------------------------------------------------*-*----
更多详细内容请关注公众号:目标检测和深度学习

-------…^-^……----------------------------------------------------------------------------------------------------------…^-^……--















 175
175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











