







之前的几篇博客的一个共同点就是梯度下降法,梯度下降法是用来求解无约束最优化问题的一个数值方法,简单实用,几乎是大部分算法的基础,下面来利用梯度下降法优化BP神经网络。
[TOC]
梯度公式
下面的BP神经网络结构为最简单的三层网络,各层的神经元数量分别为B1,B2,B3。其中X,H,b2,O,b3均为行向量,W12,W23大小分别为(B1,B2)和(B2,B3)
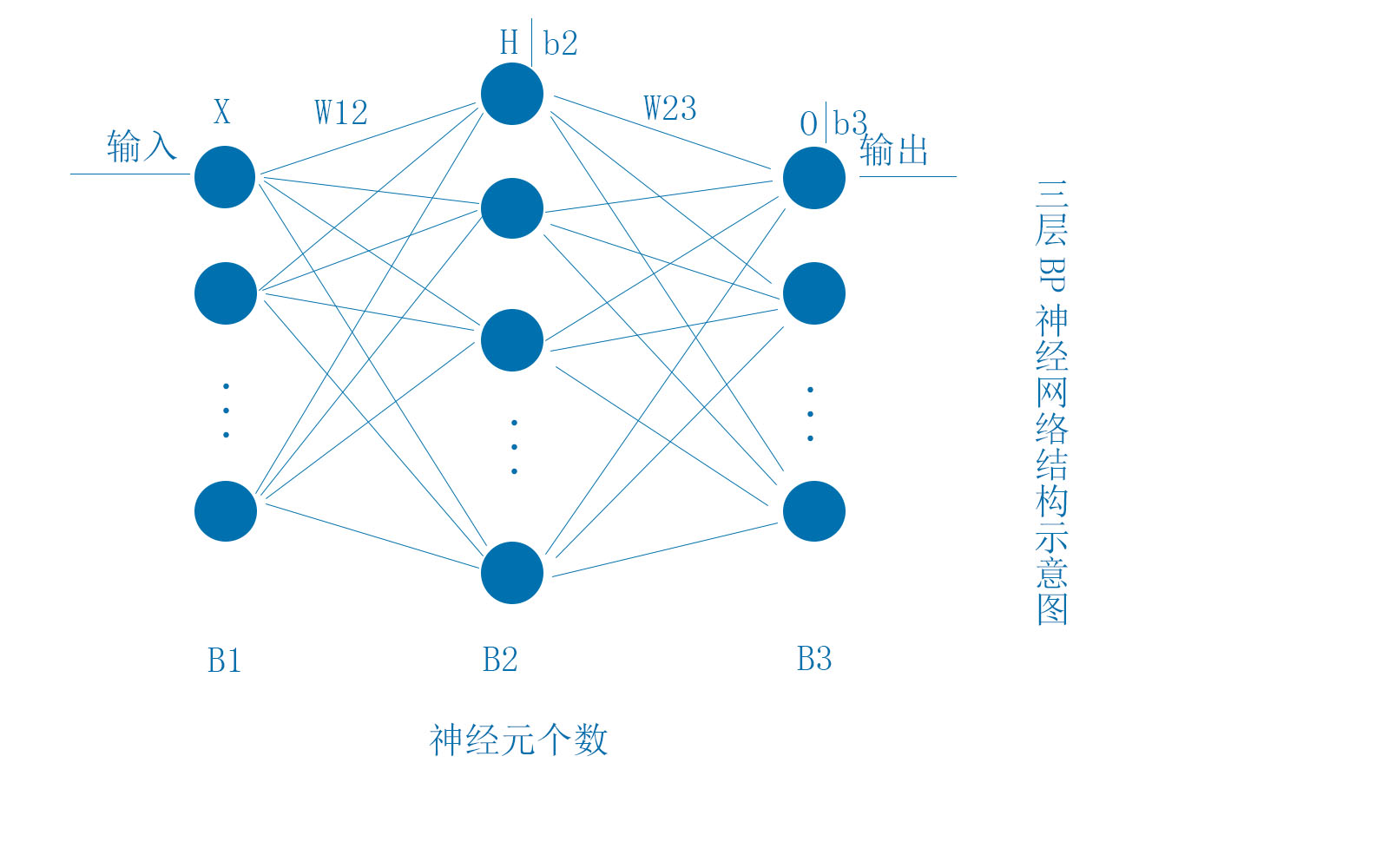
BP神经网络的基本原理,通过输入X,经过非线性映射到输出O(样本大小为m),误差为:
J=∑i=1m12∑k=1B3(Ok−Yik)2
显然,我们想要的是J越小越好。
根据上面的网络结构可得H、O的计算公式:
H=f(XW12+b2)
f函数为: f(x)=1(1+e−x) ,f函数导数为: f1=f(1−f)
O=HW23+b3
下面采用梯度下降法求解J的最小值时对应的网络的权阈值:
∂J∂b3l=∑i=1m∑k=1B3(Ok−Yik)∂Ok∂b3l.........l=1,2,...B3=∑i=1m∑k=1B3(Ok−Yik)∂((HW23)k+b3k)∂b3l=∑i=1m∑k=1B3(Ok−Yik)∂b3k∂b3l=∑i=1m(Ol−Yil).........l=1,2,...B3
如果数据集较小时,采用上述公式还可以,但是,当数据集特别大时,也就是m很大,那么梯度的计算将耗费大量时间,所以我们采用单样本误差来调整网络的权阈值。即,每使用一个样本就调整权阈值,那么J函数的形式更改如下:
J损失函数
J=12∑k=1B3(Ok−Yik)2
权阈值梯度公式
下面就新的J函数来推导梯度公式:
∂J∂b3l=Ol−Yl.........l=1,2,...,B3
即
∇J(b3)=∂J∂b3=O−Y
∂J∂W23pl=∑k=1B3(Ok−Yk)∂Ok∂W23pl.........p=1,2,...,B2;l=1,2,...,B3=∑k=1B3(Ok−Yk)(H∂W23∂W23pl)k=∑k=1B3(Ok−Yk)[0,...Hp,...0]k......Hp为第l列=(Ol−Yl)Hp.........p=1,2,...,B2;l=1,2,...,B3
即:
∇J(W23)=∂J∂W23=[HT,...,HT]点乘[(O−Y)T,...,(O−Y)T]T......H为(1,B2);O−Y为(1,B3);左边矩阵为(B2,B3),右边矩阵为(B2,B3),两矩阵点乘结果为(B2,B3)
∂J∂b2p=∑k=1B3(Ok−Yk)∂Ok∂b2p=∑k=1B3(Ok−Yk)∂(HW23)k∂b2p=∑k=1B3(Ok−Yk)∂HW23(:,k)∂b2p=∑k=1B3(Ok−Yk)∂H∂b2pW23(:,k)=∑k=1B3(Ok−Yk){H点乘(1−H)点乘∂b2∂b2p}W23(:,k)=∑k=1B3(Ok−Yk){H点乘(1−H)点乘[0,...,1,...,0]}W23(:,k)......中间矩阵的1为第p列=∑k=1B3(Ok−Yk)Hp(1−Hp)W23pk
即,
∇J(b2)=∂J∂b2=H点乘(1−H)点乘((O−Y)W23T)
∂J∂W12op=∑k=1B3(Ok−Yk)∂Ok∂W12op.........o=1,2,...,B1;p=1,2,...,B2=∑k=1B3(Ok−Yk){H点乘(1−H)点乘∂XW12∂W12op}W23(:,k)=∑k=1B3(Ok−Yk)[0,...,Hp(1−Hp)Xo,...,0]W23(:,k)=∑k=1B3(Ok−YK)Hp(1−Hp)XoW23pk=XoHp(1−Hp)((O−Y)W23T)p
即,
∇J(W12)=∂J∂W12=[XT,...,XT]点乘[(H点乘(1−H)点乘((O−Y)W23T))T,...,(H点乘(1−H)点乘((O−Y)W23T))T]T......左边矩阵为(B1,B2)点乘右边矩阵(B1,B2),结果为(B1,B2)
代码实现
下面是matlab的具体实现
准备数据
%% 三层神经网络算法的matlab实现
clear,clc,close all
% 构造样例数据
x = linspace(-10,10,2000)';
y = sin(x);
% 训练测试集分割
a = rand(length(x),1);
[m,n] = sort(a);
x_train = x(n(1:floor(0.7*length(a))));
x_test = x(n(floor(0.7*length(a))+1:end));
y_train = y(n(1:floor(0.7*length(a))));
y_test = y(n(floor(0.7*length(a)+1):end));
% 数据归一化
[x_train_regular,x_train_maxmin] = mapminmax(x_train');
x_train_regular = x_train_regular';
x_test_regular = mapminmax('apply',x_test',x_train_maxmin);
x_test_regular = x_test_regular';基于梯度下降法的训练函数
function model = BP_train( net_structure,x,y )
[sample_size,n] = size(x);
B1 = n;
B2 = net_structure.hiden_num;
[~,n] = size(y);
B3 = n;
maxgen = net_structure.maxgen;
% 初始化权重和阈值
W12 = rands(B1,B2);
b2 = rands(1,B2);
W23 = rands(B2,B3);
b3 = rands(1,B3);
E = [];
for i = 1:1:maxgen
e = 0;
for j = 1:1:sample_size
alpha = 0.5*rand;
% alpha = 1/i+0.1;
H = x(j,:)*W12+b2;
H = 1./(1+exp(-H));
O = H*W23+b3;
delta_W12 = mat_seq(x(j,:)',B2,'h').*mat_seq(H.*(1-H),B1,'v').*mat_seq((O-y(j,:))*W23',B1,'v');
delta_b2 = H.*(1-H).*((O-y(j,:))*W23');
delta_W23 = mat_seq(H',B3,'h').*mat_seq(O-y(j,:),B2,'v');
delta_b3 = O-y(j,:);
% 更新权阈值
W12 = W12-alpha*delta_W12;
b2 = b2-alpha*delta_b2;
W23 = W23-alpha*delta_W23;
b3 = b3-alpha*delta_b3;
e = e+sum((O-y(j,:)).^2);
end
E = [E,e];
disp(['迭代次数:',num2str(i)])
end
model = struct('W12',W12,'b2',b2,'W23',W23,'b3',b3,'E',E);
end
% 矩阵复制成序列
function out_mat = mat_seq(mat,num,axis)
mat0 = mat;
if axis == 'h' % 表示横向复制矩阵
for i = 1:1:(num-1)
mat0 = [mat0,mat];
end
else
for i = 1:1:(num-1)
mat0 = [mat0;mat];
end
end
out_mat = mat0;
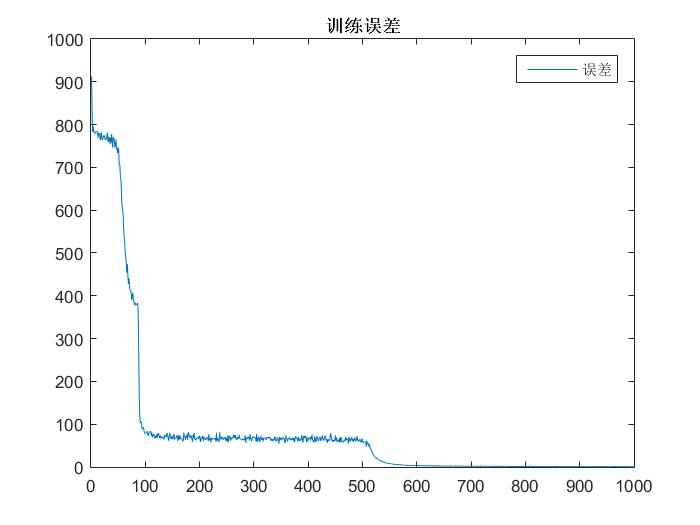
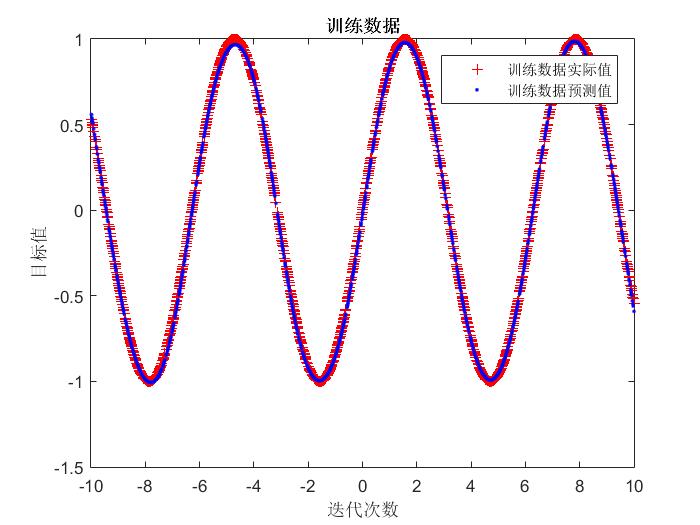
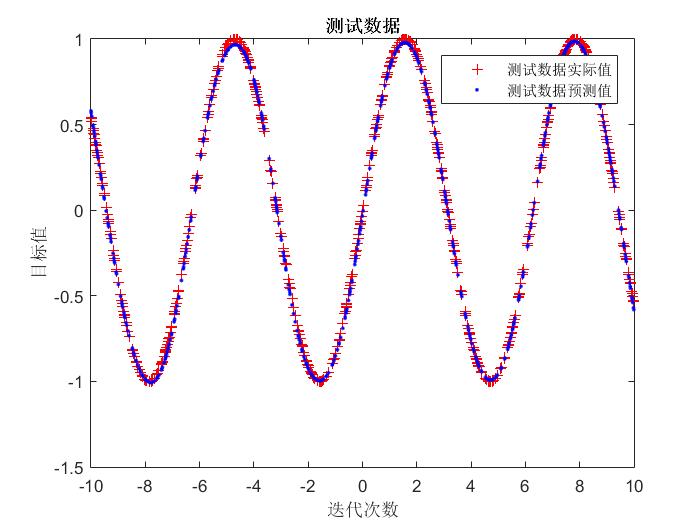
end运行结果















 949
949











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









