 SPM图像匹配原理
SPM图像匹配原理





 本文详细解析了Spatial Pyramid Matching (SPM) 在图像匹配及分类中的应用原理。SPM通过多尺度金字塔结构分解图像,结合视觉词袋模型,有效保留位置信息,提高分类精度。
本文详细解析了Spatial Pyramid Matching (SPM) 在图像匹配及分类中的应用原理。SPM通过多尺度金字塔结构分解图像,结合视觉词袋模型,有效保留位置信息,提高分类精度。
稀疏编码系列:
---------------------------------------------------------------------------
SPM [1]全称是Spatial Pyramid Matching,出现的背景是bag of visual words模型被大量地用在了Image representation中,但是BOVW模型完全缺失了特征点的位置信息。文章被引用了3400多次。文章的贡献,看完以后觉得其实挺简单的,和分块直方图其实是一个道理------将图像分成若干块(sub-regions),分别统计每一子块的特征,最后将所有块的特征拼接起来,形成完整的特征。这就是SPM中的Spatial。在分块的细节上,作者采用了一种多尺度的分块方法,即分块的粒度越大越细(increasingly fine),呈现出一种层次金字塔的结构,这就是SPM中的Pyramid。M就是Matching,没什么可说的。
具体地介绍Pyramid Matching:
-------假设存在两个点集X和Y( 每个点都是D维的,以下将它们所在的空间称作特征空间)。将特征空间划分为不同的尺度,在尺度l下特征空间的每一维划出
个cells,那么d维的特征空间就能划出
个bins;
-------两个点集中的点落入同一个bin就称这两个点Match。在一个bin中match的总数定义为 min(Xi, Yi),其中Xi和Yi分别是两个点集中落入第i个bin的点的数目;
-------统计各个尺度下match的总数(就等于直方图相交)。由于细粒度的bin被大粒度的bin所包含,为了不重复计算,每个尺度的有效Match定义为match的增量
;
-------不同的尺度下的match应赋予不同权重,显然大尺度的权重小,而小尺度的权重大,因此定义权重为;
-------最终,两点集匹配的程度定义为:
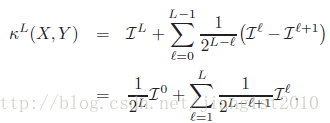
在作者提出的SPM中,作者实际采用了图像的空间坐标来代替第三段假设中提到的特征空间。因此就有作者的SPM:
-------将图像空间用构造金字塔的方法分解为多个scale的bins(通俗地说就是切分成不同尺度的方形);
-------像BOW一样构造一本大小为M的dictionary,这样每个特征都能投影到dictionary中的一个word上。其中字典的训练过程是在特征空间中完成。论文中的特征利用的dense SIFT。
-------统计每个bin中各个words的数目,最终两幅图像的匹配程度定义为:
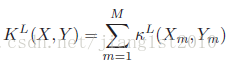
注意,当L=0时,模型就退化成为BOW了。
SPM介绍了两幅图像匹配的方法。如要用于场景分类,注意(2)式就等于M(L+1)个直方图相交运算的和,其实也就等于一个更大的向量直接进行直方图相交运算而已。而这个向量,就等于每个被划分的图像子区域上的visual words直方图连在一起。这个特征,就是用来分类的特征。
作者在实验中表明,不同L下,M从200取到400对分类性能影响不大,也就是降低了码书的大小对分类效果的影响。
在本文最开始也提到了,这个方法可以作为一个模板,每个sub-region中统计的直方图可以多种多样,简单的如颜色直方图,也可以用HOG,这就形成了PHOG。SPM的matlab代码也可以从作者的主页上下载到(here)。只不过这种空间分类信息仍然有局限性-----一幅相同的图像旋转90度,匹配的结果就不会太高了。所以模型隐含的假设就是图像都是正着存储的(人都是站立的,树都是站立的.......)。Spatial BOW [2] 好像可以解决这个问题。另外空间Pyramid的分块方法也没有考虑图像中object的信息(仅仅是利用SIFT特征来描述了Object),这也是作者在文中承认的缺点。
update @2014.5.29
最近有几位网友提问,说SPM解决了图像匹配的时候如何计算相似度。但是很多时候我们要解决分类问题,怎么联系在一起。我就在这一段谈谈我的理解。当然可能有不正确的地方,大家可以留言与我讨论。
匹配的过程中,我们通过(2)式计算相似度,相似度衡量了两组特征之间的匹配程度。而分类问题和匹配是紧密相连的。我们以最经典的SVM分类器为例子,SVM最终的分类决策函数可以写成:
其中xi是所有的训练样本,x是待分类的样本,α只有对应的支持向量才会大于0(非支持向量都等于0)。(3)式的截图是从pluskid博客上偷来的,如果大家已经忘了SVM的推导可以看看他的博客(点这里),一个非常好的介绍SVM的系列。相似的公式也可以在李航的《统计学习方法》P106-107找到。
我们可以再把(3)式稍微改写一下,把训练样本分成正负样本两类:
(4)
好了,(4)式的结果就比较直观了。等式右边第一项其实就是待分类的样本与所有正样本的内积(也就是(2)式所描述的相似度,SVM可以用核函数代替内积,在(2)式中也是用了直方图相交的核函数代替内积,而内积是欧式距离对应的核函数。SPM原文中所提到用在分类问题中,就是用Chi-squre Kernel的SVM,这与直方图相交一样都是L1距离对应的核函数),第二项是与所有负样本的内积。中间是减号,表明与所有负样本的内积大,f(x)就偏负,而与正样本的内极大,f(x)就偏正。因此,SVM无非就是正负训练样本之间的一场拔河,谁力气大(和哪一类最像),x就归谁(属于那一类)。而SVM的学习过程,无非就是学习α和b这些参数的过程。这些参数对各个训练样本进行加权,权重大的训练样本决定性就强。因而,分类问题本质上就是一个测试样本与训练样本一一匹配的问题了。
我觉得说到这,分类和匹配的关系就讲明白了吧。
Reference:
--------------
作者:jiang1st2010


















 2万+
2万+











 到【灌水乐园】发言
到【灌水乐园】发言







