









在之前的笔记中,我们假设样本是线性可分的,即存在一个划分超平面能将样本正确分类,然而在实际任务中,原始的样本空间也许不能线性可分。在上一个笔记中提到对于不能线性可分的样本,我们添加了一个松弛变量就完成了对线性不可分的支持向量机的求解。其原理是什么,我将在这个笔记中详细总结。
1.核函数
对于线性不可分的样本,我们的处理思想是:把这些样本映射到更高的维度中,在高维度中找一个划分超平面。简单的举个例子就是,我们在二维坐标系中,我们可以用一条直线来划分样本,如果不能用一条直线划分,我们将这些点影射到三维坐标系中,在空间坐标系中就可能存在一个平面来划分这些样本。
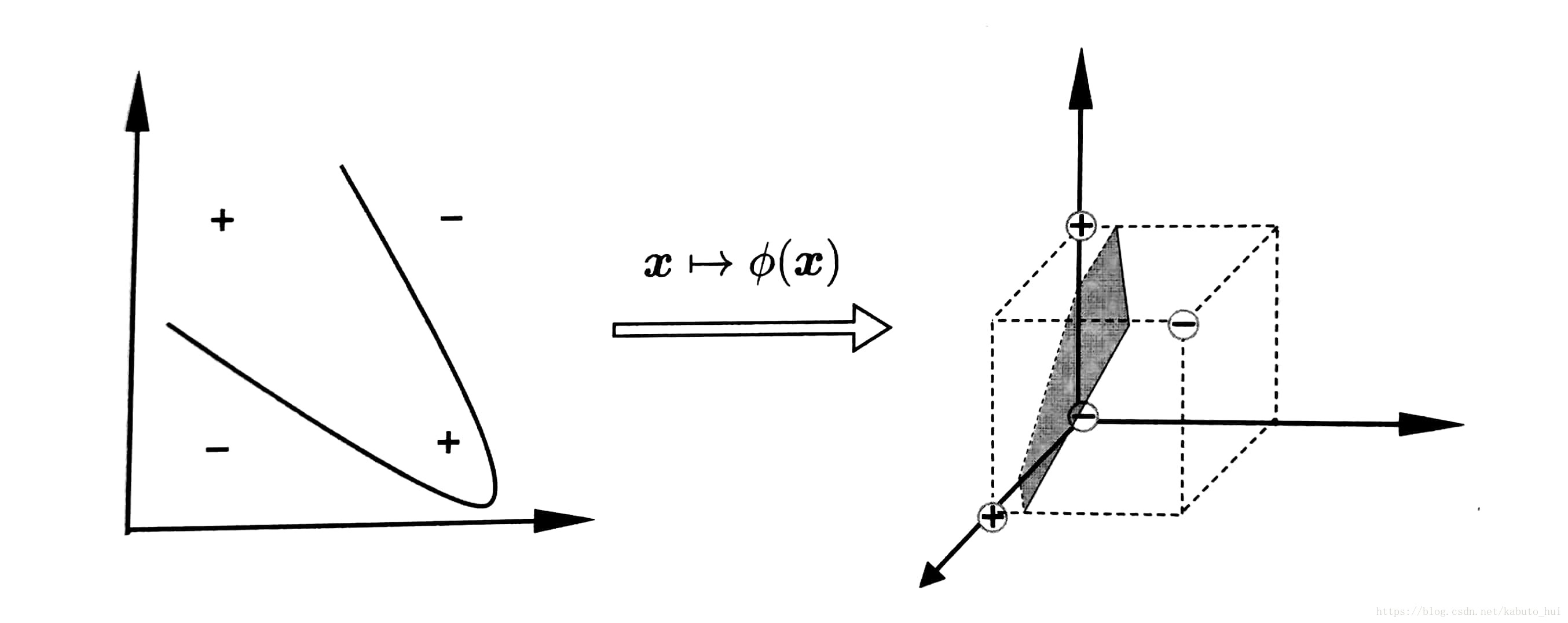
如果用
ϕ(x)
ϕ
(
x
)
来表示x映射后的特征向量,于是划分超平面就可以表示为:
其优化问题变为:
对偶问题变为:
中间涉及到了 ϕ(xi)Tϕ(xi) ϕ ( x i ) T ϕ ( x i ) ,这是样本 xi x i 与 xj x j 映射到特征空间之后的内积, 而由于特征空间的维度可能很高,直接计算内积可能非常的困难。所以为了避开这个障碍,我们设想一个函数来表示内积的结果:
于是我们只需要使用k函数来表示内积,而不用直接去计算,所以我们的优化模型可以重写为:
求解后就可以得到:
这里的 k(xi,xj) k ( x i , x j ) 就是 核函数(Kernel function),而上面的展开式也被称作”支持向量展式”
显然 ,如果我们知道映射 ϕ(⋅) ϕ ( · ) 的具体形式,我们就可以写出核函数,但是我们往往不知道映射形式,所以要怎么设定核函数呢?有以下的定理可以帮助我们来写出核函数:
定理:当 χ χ 为输入空间,k(·,·)是定义在 χ×χ χ × χ 上的对称函数,则k是核函数当且仅当对于任意的数据D = { x1,x2,...,xm x 1 , x 2 , . . . , x m },核矩阵K是半正定的:
K=∣∣∣∣∣∣k(x1,x1)k(x2,x1)...k(xm,x1)k(x1,x2)k(x2,x2)...k(xm,x2)............k(x1,xm)k(x2,xm)...k(xm,xm)∣∣∣∣∣∣ K = | k ( x 1 , x 1 ) k ( x 1 , x 2 ) . . . k ( x 1 , x m ) k ( x 2 , x 1 ) k ( x 2 , x 2 ) . . . k ( x 2 , x m ) . . . . . . . . . . . . k ( x m , x 1 ) k ( x m , x 2 ) . . . k ( x m , x m ) |
可见,只要我们可以找到一个函数k,使其核矩阵K满足半正定,那么这个函数就可以作为核函数。
所以支持向量机走到这里,问题已经集中到如何找到一个合适的核函数,如果核函数不好,样本映射到了一个不合适的特征空间,最后的结果也是不会好的。通常我们常用的几个核函数有:
线性核函数: k(xi,xj)=xTixj k ( x i , x j ) = x i T x j
高斯核函数: k(xi,xj)=exp(−||xi−xj||22σ2) k ( x i , x j ) = e x p ( − | | x i − x j | | 2 2 σ 2 ) , σ>0 σ > 0 为高斯核的带宽
【重要说明】:如何选择一个正确的核函数?
对核函数的选择,现在还缺乏指导原则!各种实验的观察结果的确表明,某些问题用某些核函数效果很好,用另一些就很差。
但是一些基本的经验还是可以借鉴的,如对于文本数据通常采用线性核,情况不明的情况下可以先尝试高斯核。
2.软间隔(soft margin)
在之前我们要求划分超平面可以完全正确划分所有样本,这称为“硬间隔”(hard margin),但是通常我们的样本可能混在一起,一个超平面并不能完全正确划分所有的样本,这个时候我们允许某些样本划分错误,这些样本不满足约束:
并且要求在最大化间隔的同时,要使不满足约束的样本尽可能的少,这个间隔我们称之为“软间隔”(soft margin)。
所以优化目标可以变为:
其中C>0是一个常数, l0/1 l 0 / 1 是0/1损失函数:
C无穷大的时候,迫使 ∑i=1ml0/1(yi(wTxi+b)−1) ∑ i = 1 m l 0 / 1 ( y i ( w T x i + b ) − 1 ) 趋近于0,即所有样本满足约束条件;当C的取值有限的时候,就允许部分样本不满足约束条件。
但是 l0/1 l 0 / 1 非凸、非连续和数学性质不好,不太方便用于迭代计算。所以这里我们有几个函数可以替代它:
hinge损失: lhinge(z)=max(0,1−z) l h i n g e ( z ) = m a x ( 0 , 1 − z )
指数损失: lexp(z)=exp(−z) l e x p ( z ) = e x p ( − z )
对率损失: llog(z)=log(1+exp(−z)) l l o g ( z ) = l o g ( 1 + e x p ( − z ) )
这个时候我们引入松弛变量,于是优化问题就变为(与上一笔记中关于线性不可分支持向量机的内容一致):
此时,拉格朗日函数为:
对w,b,ξ求偏导:
带入L中得到:
对上式关于 α α 求极大,并求其对偶问题:
求得最优解α*,计算w与b:
注意:计算b*时,需要满足0<αj














 1294
1294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









