







1 代价函数
神经网络分类表述:
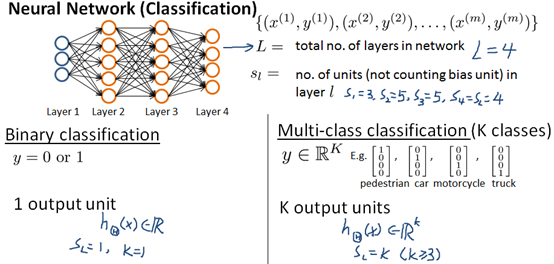
代价函数(cost function)
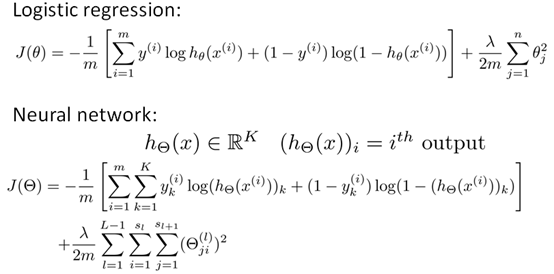
2 反向传播算法
得到了神经网络的代价函数后,接下来要做的就是找到参数Θ使J(Θ)取得最小值:

假设整个训练集只有一个训练样本(x,y),反向传播算法:
Forward propagation:

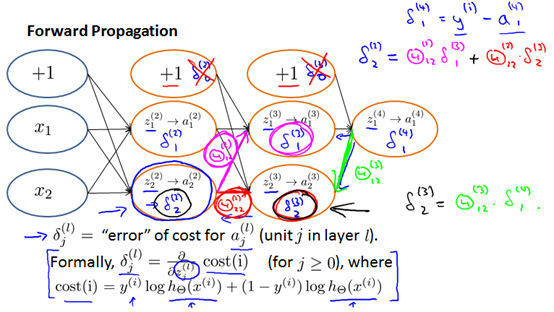
Backpropagation(反向传播):
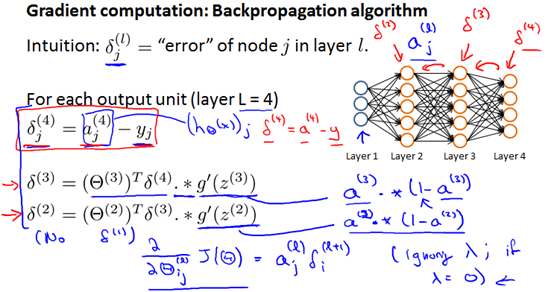
之所以叫反向传播是因为我们是从输出层开始计算的,计算时不存在计算δ(1) 是因为第一层对应输入层,这是我们在训练集观察到的,所以不会存在误差。
假设整个训练集有非常大的训练样本时,反向传播算法:

3 反向传播直观理解
Forward Propagation(从左往右计算)原理:
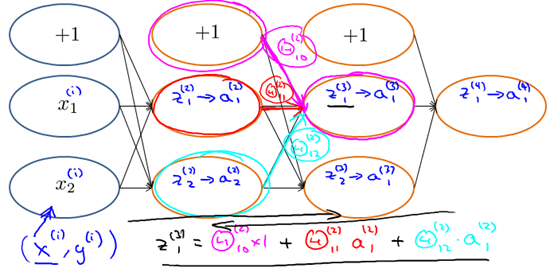
Backpropagation(从右往左计算)原理:

4 Implementation note:Unrolling parameters
上一节介绍了利用反向传播算法计算代价函数的导数,本节介绍一个细节的实现过程,怎样把你的参数从矩阵展开成向量,以便我们在高级最优化步骤中的使用需要。



使用矩阵表达式的好处是:当你的参数以矩阵形式存储时,你在进行正向传播和反向传播时更加方便,充分利用了向量化的实现过程。向量表达式的优点是:当你拥有thetaVec或者Dvec这样的矩阵时,当你使用高级优化算法时,这些算法通常要求所有的参数都要展开成一个长向量的形式。
5 梯度检验
当我们对一个较为复杂的模型(例如神经网络)使用梯度下降算法时,可能会存在一些不容易察觉的错误,为了避免这样的问题,我们采取一种叫做梯度检验的方法
梯度的数值估计,θ是一个实数

θ是一个n维向量


如果梯度的数值估计gradApprox与通过反向传播得到的DVec近似相等,就可以认为我们通过反向传播得到的DVec是正确的,就可以将DVec用在梯度下降或者其他优化算法里。一旦确定了反向传播算法是正确的就应该关闭梯度检验,如果不关闭会导致程序运行速度很慢。

6 Random initialization
对于梯度下降或者其他高级优化算法都需要进行参数Θ初始化,到目前为止我们都是初始所有参数为0,这样的初始方法对于逻辑回归来说是可行的,但是对于神经网络来说是不可行的。
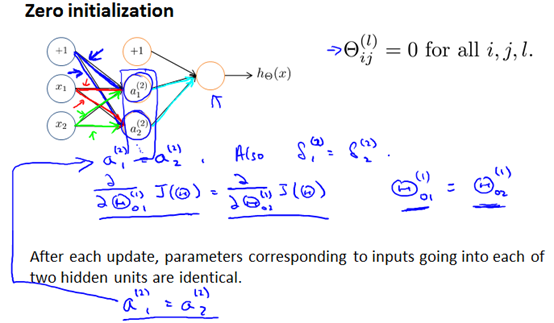
也就是说每一次更新,图中两个隐藏单元都是相等的。这就阻止了神经网络学习一些有趣的事儿。解决方法就是参数要随机初始化,打破对称性。

7 Putting it together
选择神经网络的结构
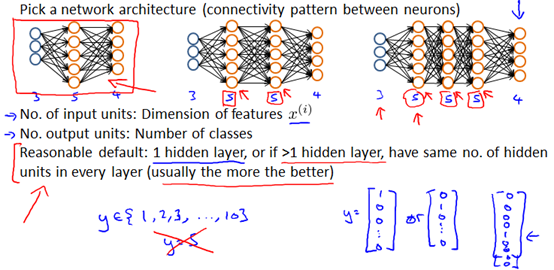
训练神经网络


注意J(Θ)一般是非凸函数,通过梯度下降算法一般都能得到比较不错的局部最小值,尽管不能保证是全局最小值。















 5986
5986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









