




 本文详细介绍了Softmax及其在多分类问题中的应用,包括Softmax回归模型原理、公式推导、损失函数计算等内容,并提供了Caffe中Softmax层的具体实现。
本文详细介绍了Softmax及其在多分类问题中的应用,包括Softmax回归模型原理、公式推导、损失函数计算等内容,并提供了Caffe中Softmax层的具体实现。
如果有什么疑问或者发现什么错误,欢迎在评论区留言,有时间我会一一回复
softmax简介
Softmax回归模型是logistic回归模型在多分类问题上的推广,在多分类问题中,待分类的类别数量大于2,且类别之间互斥。比如我们的网络要完成的功能是识别0-9这10个手写数字,若最后一层的输出为[0,1,0, 0, 0, 0, 0, 0, 0, 0],则表明我们网络的识别结果为数字1。
Softmax的公式为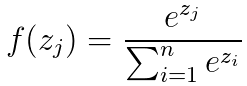
softmax层的推导
softmax层的前向计算
在我们的网络中,最后一层是softmax层。
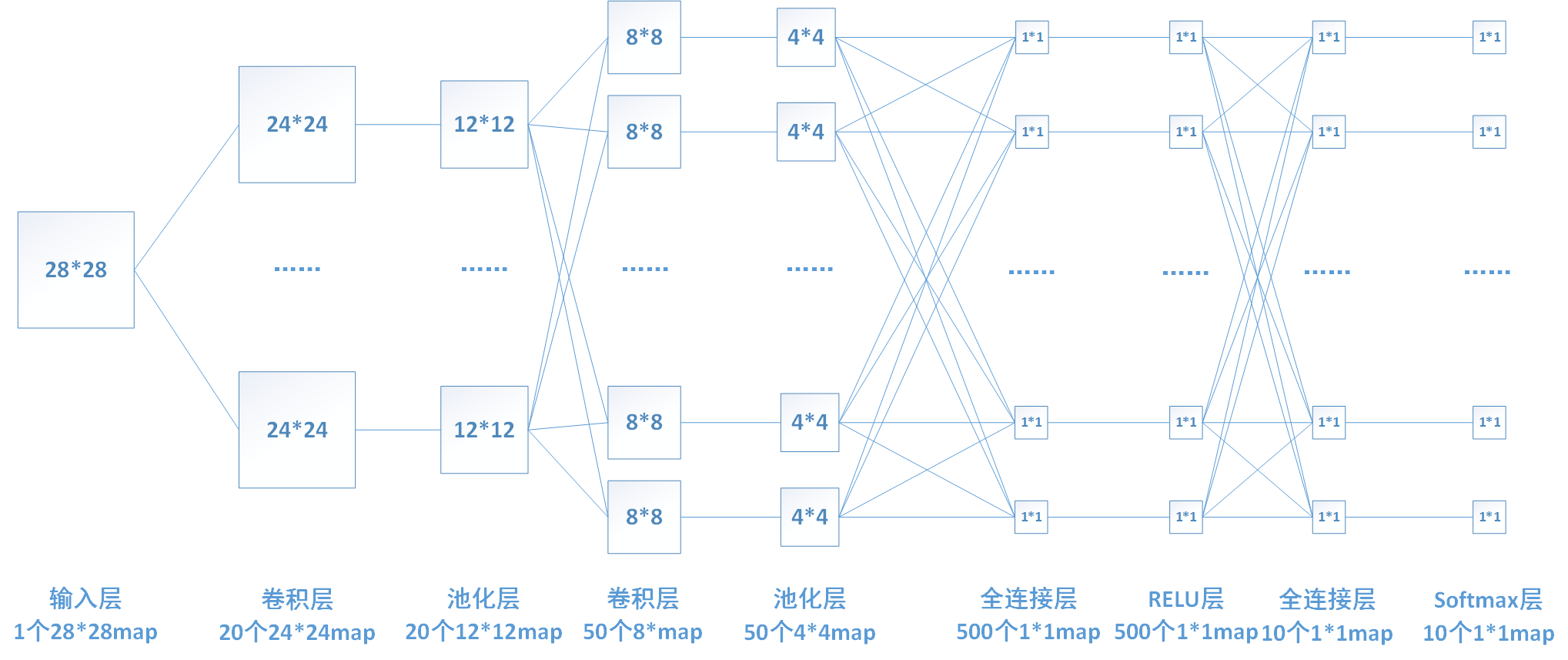
softmax公式为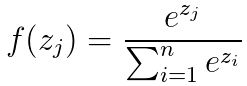
Softmax还有另一种计算方法。假设zk为输入中的最大值,则softmax也可以写成这种形式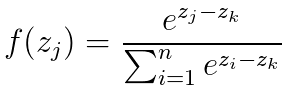
softmax层的反向传播
设softmax的输出为a,输入为z,损失函数为loss。则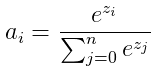 ,
, 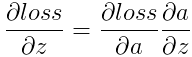 。其中
。其中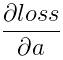 在caffe中是top_diff,a为caffe中的top_data,均为已知量。需要计算的是
在caffe中是top_diff,a为caffe中的top_data,均为已知量。需要计算的是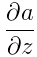 。
。直接求导可得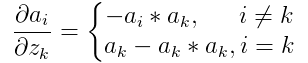
所以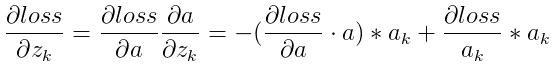
softmax层的损失函数
通常情况下softmax会被用在网络中的最后一层,用来进行最后的分类和归一化。所以其实上边softmax层的反向传播一般不会用到。
Softmax的损失函数使用的是对数损失函数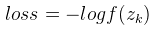 ,其中k为该样本的label(即该样本对应的正确输出,比如我们要识别的图片是数字7,则k=7,选择softmax的第7个输出值来计算loss)。一般我们进行训练时一批图片有多张,比如batch size = 16,则
,其中k为该样本的label(即该样本对应的正确输出,比如我们要识别的图片是数字7,则k=7,选择softmax的第7个输出值来计算loss)。一般我们进行训练时一批图片有多张,比如batch size = 16,则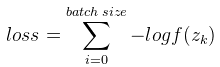 。
。由于我们的输入为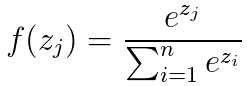
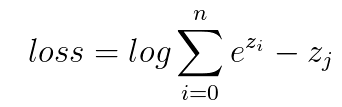
若loss对每个输入z求导,则有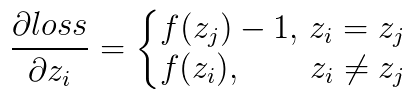
Caffe中softmax层的实现
在caffe中,关于softmax层有2种实现,一种是SoftmaxWithLoss,可以计算出loss;另一种为softmax,只计算出每个类别的概率似然值。这样在实际使用中比较灵活。若只是想得到每个类别的概率似然值,则只需使用softmax层即可,就不需调用SoftmaxWithLoss。
SoftmaxWithLoss的配置信息如下:
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip2"
bottom: "label"
top: "loss"
}
该层的类型为SoftmaxWithLoss,可以计算给出每个样本对应的损失函数值。他有2个输入层,分别为全连接层2和标签值label,输出为求得的多个样本的loss之和除以样本数的值。
Softmax层的配置信息如下:
layers {
name: "prob"
type: “Softmax"
bottom: " ip2"
top: "prob"
}
输出为每个类别的概率值。
Caffe中softmax层相关的GPU文件为\src\caffe\layers\ softmax_layer.cu
Caffe中SoftmaxWithLoss层相关的GPU文件为\src\caffe\layers\ softmax_loss_layer.cu
下面分别介绍
前向计算
1、softmax层前向计算过程代码及注释如下
template <typename Dtype>
void SoftmaxLayer<Dtype>::Forward_gpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_data = bottom[0]->gpu_data();
Dtype* top_data = top[0]->mutable_gpu_data();
Dtype* scale_data = scale_.mutable_gpu_data();
int count = bottom[0]->count();
int channels = top[0]->shape(softmax_axis_);
caffe_copy(count, bottom_data, top_data);
// compute max
//计算最大值max,scale_data为保存最大值的变量
kernel_channel_max<Dtype><<<CAFFE_GET_BLOCKS(outer_num_ * inner_num_),
CAFFE_CUDA_NUM_THREADS>>>(outer_num_, channels, inner_num_, top_data,
scale_data);
// subtract
//每个输入Zi均减去最大值max
kernel_channel_subtract<Dtype><<<CAFFE_GET_BLOCKS(count),
CAFFE_CUDA_NUM_THREADS>>>(count, outer_num_, channels, inner_num_,
scale_data, top_data);
// exponentiate
//求e^(Zi-max)
kernel_exp<Dtype><<<CAFFE_GET_BLOCKS(count), CAFFE_CUDA_NUM_THREADS>>>(
count, top_data, top_data);
// sum after exp
//求和,计算e^(Zi-max),i=[0,n]之和
kernel_channel_sum<Dtype><<<CAFFE_GET_BLOCKS(outer_num_ * inner_num_),
CAFFE_CUDA_NUM_THREADS>>>(outer_num_, channels, inner_num_, top_data,
scale_data);
// divide
//每一个指数e^(Zi-max)除以上一步求得的最大值
kernel_channel_div<Dtype><<<CAFFE_GET_BLOCKS(count),
CAFFE_CUDA_NUM_THREADS>>>(count, outer_num_, channels, inner_num_,
scale_data, top_data);
}
2、SoftmaxWithLoss层前向计算过程代码及注释如下
template <typename Dtype>
void SoftmaxWithLossLayer<Dtype>::Forward_gpu(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
softmax_layer_->Forward(softmax_bottom_vec_, softmax_top_vec_);
const Dtype* prob_data = prob_.gpu_data();
const Dtype* label = bottom[1]->gpu_data();
const int dim = prob_.count() / outer_num_;
const int nthreads = outer_num_ * inner_num_;
Dtype* loss_data = bottom[0]->mutable_gpu_diff();
Dtype* counts = prob_.mutable_gpu_diff();
//计算一个batch中每一个样本的loss
SoftmaxLossForwardGPU<Dtype><<<CAFFE_GET_BLOCKS(nthreads),
CAFFE_CUDA_NUM_THREADS>>>(nthreads, prob_data, label, loss_data,
outer_num_, dim, inner_num_, has_ignore_label_, ignore_label_, counts);
Dtype loss;
//对loss求和
caffe_gpu_asum(nthreads, loss_data, &loss);
Dtype valid_count = -1;
// Only launch another CUDA kernel if we actually need the count of valid
// outputs.
if (normalization_ == LossParameter_NormalizationMode_VALID &&
has_ignore_label_) {
caffe_gpu_asum(nthreads, counts, &valid_count);
}
//除以每一个batch中的样本数量
top[0]->mutable_cpu_data()[0] = loss / get_normalizer(normalization_,
valid_count);
if (top.size() == 2) {
top[1]->ShareData(prob_);
}
}
反向传播
1、softmax层反向传播过程代码及注释如下
template <typename Dtype>
void SoftmaxLayer<Dtype>::Backward_gpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) {
const Dtype* top_diff = top[0]->gpu_diff();
const Dtype* top_data = top[0]->gpu_data();
Dtype* bottom_diff = bottom[0]->mutable_gpu_diff();
Dtype* scale_data = scale_.mutable_gpu_data();
int count = top[0]->count();
int channels = top[0]->shape(softmax_axis_);
caffe_copy(count, top_diff, bottom_diff);
// Compute inner1d(top_diff, top_data) and subtract them from the bottom diff.
// NOLINT_NEXT_LINE(whitespace/operators)
kernel_channel_dot<Dtype><<<CAFFE_GET_BLOCKS(outer_num_ * inner_num_),
CAFFE_CUDA_NUM_THREADS>>>(outer_num_, channels, inner_num_,
top_diff, top_data, scale_data);
// NOLINT_NEXT_LINE(whitespace/operators)
kernel_channel_subtract<Dtype><<<CAFFE_GET_BLOCKS(count),
CAFFE_CUDA_NUM_THREADS>>>(count, outer_num_, channels, inner_num_,
scale_data, bottom_diff);
// elementwise multiplication
caffe_gpu_mul<Dtype>(top[0]->count(), bottom_diff, top_data, bottom_diff);
}
2、SoftmaxWithLoss层反向传播过程代码及注释如下
template <typename Dtype>
void SoftmaxWithLossLayer<Dtype>::Backward_gpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) {
if (propagate_down[1]) {
LOG(FATAL) << this->type()
<< " Layer cannot backpropagate to label inputs.";
}
if (propagate_down[0]) {
Dtype* bottom_diff = bottom[0]->mutable_gpu_diff();
const Dtype* prob_data = prob_.gpu_data();
const Dtype* top_data = top[0]->gpu_data();
//prob_data为softmax预测结果,复制到bottom_diff
caffe_gpu_memcpy(prob_.count() * sizeof(Dtype), prob_data, bottom_diff);
const Dtype* label = bottom[1]->gpu_data();
const int dim = prob_.count() / outer_num_;
const int nthreads = outer_num_ * inner_num_;
// Since this memory is never used for anything else,
// we use to to avoid allocating new GPU memory.
Dtype* counts = prob_.mutable_gpu_diff();
//SoftmaxLossBackwardGPU将bottom_diff中对应正确label的概率值-1,其他不变,在原内存计算
SoftmaxLossBackwardGPU<Dtype><<<CAFFE_GET_BLOCKS(nthreads),
CAFFE_CUDA_NUM_THREADS>>>(nthreads, top_data, label, bottom_diff,
outer_num_, dim, inner_num_, has_ignore_label_, ignore_label_, counts);
Dtype valid_count = -1;
// outputs.
if (normalization_ == LossParameter_NormalizationMode_VALID &&
has_ignore_label_) {
caffe_gpu_asum(nthreads, counts, &valid_count);
}
//除以batch size
const Dtype loss_weight = top[0]->cpu_diff()[0] /
get_normalizer(normalization_, valid_count);
caffe_gpu_scal(prob_.count(), loss_weight , bottom_diff);
}
}

















 3366
3366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









