







 本文深入介绍WFST(有限状态转换器)在语音识别中的应用,特别是Composition算法。通过组合发音词典和语言模型的WFST,形成音素到受语法约束的词的映射。文章详细阐述了Composition的过程,包括非ε和含ε情况,并讨论了如何通过filter减少冗余路径。后续章节将探讨WFST的优化技术。
本文深入介绍WFST(有限状态转换器)在语音识别中的应用,特别是Composition算法。通过组合发音词典和语言模型的WFST,形成音素到受语法约束的词的映射。文章详细阐述了Composition的过程,包括非ε和含ε情况,并讨论了如何通过filter减少冗余路径。后续章节将探讨WFST的优化技术。
这几天生病了,很难受,更新的事情搁置了几天。
言归正传,之前建议大家看Mohri的paper因为那是Kaldi官网WFST那一章的作者推荐的,但是现在发现有一本更好的书推荐给大家,这本书深入浅出,讲的更详细,更适合入门的人,尤其是WFST是怎么用在语音识别中的部分讲的特别棒。还有这本书的作者好像是个日本人,所以文笔很适合我们亚洲人的思维。下面是这本书的封面,强力推荐给想入门语音识别解码部分的童鞋。

上一章节主要介绍了半环(semiring)理论和WFST的一些基础概念,本章节介绍Composition算法。
Composition是WFST中最最重要的算法,它是将两个不同级的WFST进行组合,举个例子,语音识别中发音词典的WFST是音素对词的映射,而语言模型的WFST是词对受语法约束的词的映射,那么两个WFST进行Composition后就变成了音素对受语法约束的词的映射。那么其实语音识别的WFST的最基本的框架也很简单,就是HCLG四个不同级的WFST进行依次Composition最后形成了HMM的状态对受语法约束的词的映射。(当然实际不可能这么简单啦,还有很多优化的操作,这个后面几章会详细得介绍,这里不多说)
我们先来看一下Composition的效果,图(a)和图(b)Composition后生成了图(c),从这么简单的效果图我们大致可以看出来其实这个操作就是找出满足下面这个条件的转移:第一个WFST的某个转移上的输出标签等于第二个WFST的某个转移上的输入标签,然后把这些转移上的label和weight分别进行操作:
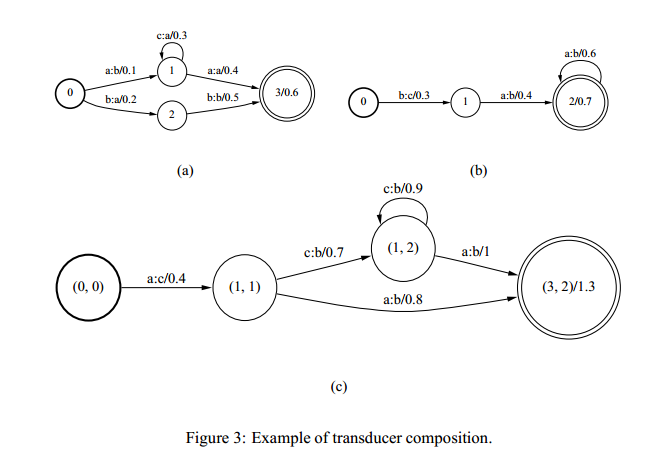
当然上面的大白话肯定是不严谨、不完全正确的,下面我们将结合下伪代码来介绍正确的生成方式。需要注意的是,这里是一个epsilon-free的算法,即第一个WFST的任意转移上的输出label不能为空( ε )并且第二个WFST的任意转移上的输入label也不能为空( ε )。

这个算法使用了一个队列S,它的特点数据结构中都学过——先进先出;
对两个WFST T1和T2:
第1行第2行把两个WFST的初始状态赋给Q和S,
Q用来统计出现过的所有状态对的集合,
S用来记录此时的状态对能达到的所有状态对的集合;
第3行如果S不为空,则执行下面4到16行的代码:
第4行第5行把队列S的头元素赋给状态对(q1,q2),删除该元素,刚开始肯定是初始状态对,所以肯定会执行第6到8行;
第6到11行是为了判断一下是否为初始状态和结束状态;
第12到16行是核心部分:
找出所有离开T1中:状态q1的所有转移和离开T2中的状态q2的所有转移,并且对比T1的这些转移的输出label是否等于T2的这些转移的输入label( o[e1]=i[e
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









