







决策树是怎么来的呢?Morgan and Sonquist ,提出的基于树的方法,叫做:automatic interaction detector AID ,(为了解决资料数据上下文的多变量非加性效应?)算了还是给原句吧,AID for handling multi-variate non-additive effects in the context of survey data。
决策树的几个特点:
1.处理异质数据。
2.对噪声数据鲁棒。
3.对离群点鲁棒。
4.是容易解释的,即使是对非统计专业的用户。
决策树是随机森林、boosting、bagging等的基础。
以下论点或摘自统计学习方法(李航),或自己理解。决策树是一种描述对实例进行分类的树形结构,决策树由结点(node)和有向边(direct edge)组成,结点有两种类型:内部节点(internal node)和叶节点(leaf node)。内部节点表示一个特征或属性,叶节点表示一个类别。
图示的话就摘一下大家通用的吧
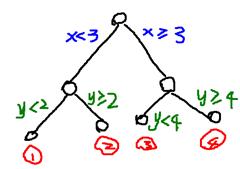
可以看作在超平面的划分如下:
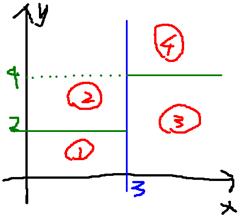
图片是这位仁兄的,谢谢你啦http://database.51cto.com/art/201407/444788.htm
这里还要重点介绍一下熵和信息增益、信息增益率的信息:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1340
1340
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









