









架构
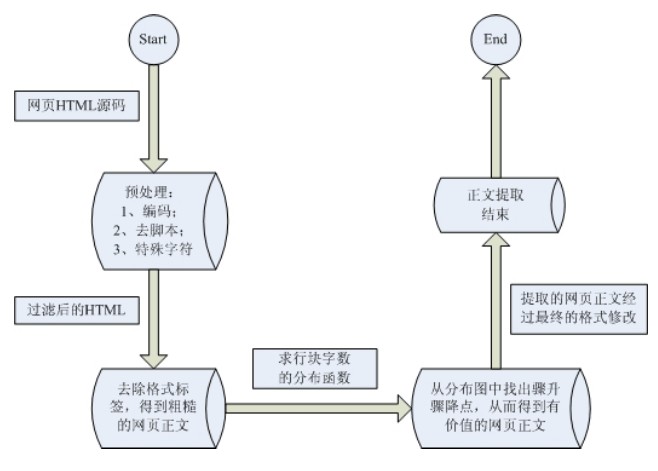
基于行块分布函数的通用网页正文抽取
http://wenku.baidu.com/link?url=TOBoIHWT_k68h5z8k_Pmqr-wJMPfCy2q64yzS8hxsgTg4lMNH84YVfOCWUfvfORTlccMWe5Bd1BNVf9dqIgh75t4VQ728fY2Rte3x3CQhaS网页正文及内容图片提取算法
http://www.jianshu.com/p/d43422081e4b
这一算法的主要原理基于两点:
正文区密度:在去除HTML中所有tag之后,正文区字符密度更高,较少出现多行空白;
行块长度:非正文区域的内容一般单独标签(行块)中较短。
https://github.com/rainyear/cix-extractor-py/blob/master/extractor.py#L9
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
import requests as req
import re
DBUG = 0
reBODY = r'<body.*?>([\s\S]*?)<\/body>'
reCOMM = r'<!--.*?-->'
reTRIM = r'<{0}.*?>([\s\S]*?)<\/{0}>'
reTAG = r'<[\s\S]*?>|[ \t\r\f\v]'
reIMG = re.compile(r'<img[\s\S]*?src=[\'|"]([\s\S]*?)[\'|"][\s\S]*?>')
class Extractor():
def __init__(self, url = "", blockSize=3, timeout=5, image=False):
self.url = url
self.blockSize = blockSize
self.timeout = timeout
self.saveImage = image
self.rawPage = ""
self.ctexts = []
self.cblocks = []
def getRawPage(self):
try:
resp = req.get(self.url, timeout=self.timeout)
except Exception as e:
raise e
if DBUG: print(resp.encoding)
resp.encoding = "UTF-8"
return resp.status_code, resp.text
#去除所有tag,包括样式、Js脚本内容等,但保留原有的换行符\n:
def processTags(self):
self.body = re.sub(reCOMM, "", self.body)
self.body = re.sub(reTRIM.format("script"), "" ,re.sub(reTRIM.format("style"), "", self.body))
# self.body = re.sub(r"[\n]+","\n", re.sub(reTAG, "", self.body))
self.body = re.sub(reTAG, "", self.body)
#将网页内容按行分割,定义行块 blocki 为第 [i,i+blockSize] 行文本之和并给出行块长度基于行号的分布函数:
def processBlocks(self):
self.ctexts = self.body.split("\n")
self.textLens = [len(text) for text in self.ctexts]
self.cblocks = [0]*(len(self.ctexts) - self.blockSize - 1)
lines = len(self.ctexts)
for i in range(self.blockSize):
self.cblocks = list(map(lambda x,y: x+y, self.textLens[i : lines-1-self.blockSize+i], self.cblocks))
maxTextLen = max(self.cblocks)
if DBUG: print(maxTextLen)
self.start = self.end = self.cblocks.index(maxTextLen)
while self.start > 0 and self.cblocks[self.start] > min(self.textLens):
self.start -= 1
while self.end < lines - self.blockSize and self.cblocks[self.end] > min(self.textLens):
self.end += 1
return "".join(self.ctexts[self.start:self.end])
#如果需要提取正文区域出现的图片,只需要在第一步去除tag时保留<img>标签的内容:
def processImages(self):
self.body = reIMG.sub(r'{{\1}}', self.body)
#正文出现在最长的行块,截取两边至行块长度为 0 的范围:
def getContext(self):
code, self.rawPage = self.getRawPage()
self.body = re.findall(reBODY, self.rawPage)[0]
if DBUG: print(code, self.rawPage)
if self.saveImage:
self.processImages()
self.processTags()
return self.processBlocks()
# print(len(self.body.strip("\n")))
if __name__ == '__main__':
ext = Extractor(url="http://blog.rainy.im/2015/09/02/web-content-and-main-image-extractor/",blockSize=5, image=False)
print(ext.getContext())总结
以上算法基本可以应对大部分(中文)网页正文的提取,针对有些网站正文图片多于文字的情况,可以采用保留<img> 标签中图片链接的方法,增加正文密度。目前少量测试发现的问题有:1)文章分页或动态加载的网页;2)评论长度过长喧宾夺主的网页。
web正文提取接口使用说明
http://www.weixinxi.wang/open/extract.html
Newspaper/python-readability库也可以实现
#!/usr/bin/python
# -*- coding:UTF-8 -*-
from newspaper import Article
url = 'http://www.cankaoxiaoxi.com/roll10/20160619/1197379.shtml'
article = Article(url, language='zh')
article.download()
article.parse()
print(article.text)















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









