









1)先进先出调度器(FIFO)
2)公平调度器(FairScheduler)
3)容量调度器(CapacityScheduler)
FIFO调度器
1)FIFO调度器是hadoop中默认的调度器,它先遵循高优先级优先,然互按照作业到来的顺序进行调度
2)这种默认的调度器的一个缺点是:高优先级以及需要长时间运行的作业一直在被处理,而低优先级以及短作业将长时间得不到调度
FairScheduler(FaceBook开发)
1)FairScheduler的目标是让每个用户公平的共享集群
2)作业被放在池中,在默认情况下,每个用户都有自己的池
3)支持抢占,如果一个池在特定的时间内未得到公平的资源分配,调度器就会终止运行池中得到过多的资源的任务,以便把任务槽让给资源不足的池。
CapacityScheduler(雅虎开发)
1)支持多个队列,每个队列可以配置一定的资源量,每个队列采用FIFO调度策略
2)为了防止同一个用户提交的作业独占队列中的资源,对同一个用户提交作业所占的资源进行限定
3)具有的特性:层次化的队列、资源容量保证、安全性、弹性、可操作性、基于资源的调度
任务选择策略分析
任务选择发生在调度器选定一个作业之后,目的是从该作业中选择一个最合适的任务。在Hadoop中,选择Map Task时需考虑的最重要的因素是数据本地性,也就是尽量将任务调度到数据所在节点。除了数据本地性之外,还需考虑失败任务、备份任务的调度顺序等。然而,由于Reduce Task没有数据本地性可言,因此选择Reduce Task时通常只需考虑未运行任务和备份任务的调度顺序。
(1)数据本地性
在分布式环境中,为了减少任务执行过程中的网络传输开销,通常将任务调度到输入数据所在的计算节点,也就是让数据在本地进行计算,而Hadoop正是以“尽力而为”的策略保证数据本地性的。
为了实现数据本地性,Hadoop需要管理员提供集群的网络拓扑结构。如图所示
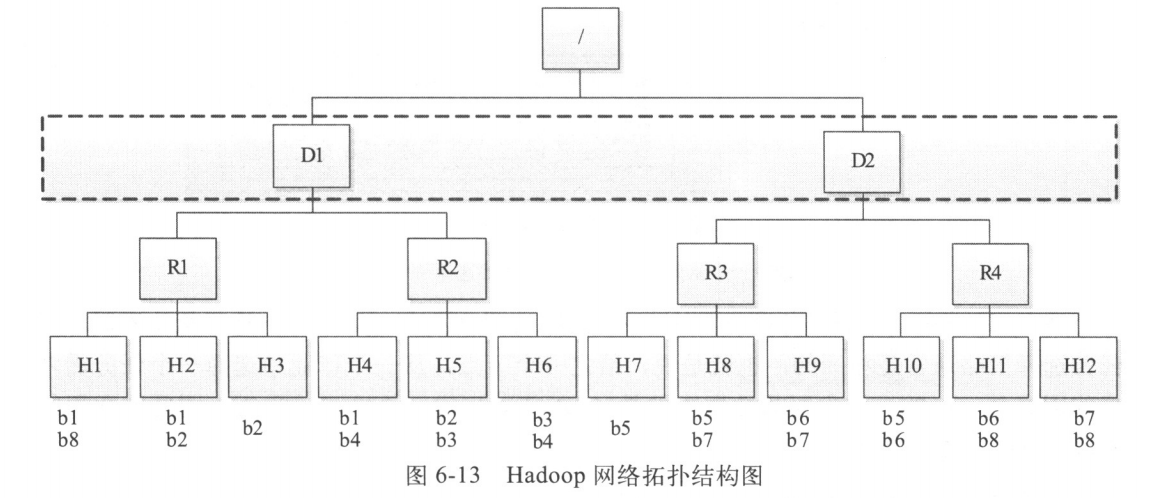
Hadoop集群采用了三层网络拓扑结构,其中,根节点表示整个集群,第一层代表数据中心,第二层代表机架或者交换机,第三层代表实际用于计算和存储的物理节点。
Hadoop根据输入数据与实际分配的计算资源之间的距离将任务分成三类:node-local(输入数据与计算资源同节点),rack-local(同机架)和off-switch(跨机架)。当输入数据与计算资源位于不同节点上时,Hadoop需将输入数据远程复制到计算资源所在节点进行处理。两者距离越远,需要的网络开销越大,因此调度器进行任务分配时尽量选择离输入数据近的节点资源。
当Hadoop进行任务选择时,采用了自下而上查找的策略。由于当前采用了两层网络拓扑结构(即数据中心一层暂时未被考虑),因此这种选择机制决定了任务优先级从高到低依次为:node-local、rack-local和off-switch。下面结合上图介绍三种类型的任务被选中的场景。
假设某一时刻,TaskTracker X出现空闲的计算资源,向JobTracker汇报心跳请求新的任务,调度器根据一定的调度策略为之选择了任务Y
1)如果X是H1,任务Y输入数据块为b1,则该任务为node-local
2)如果X是H1,任务Y输入数据块为b2,则该任务为rack-local
3)如果X是H1,任务Y输入数据块为b4,则该任务为off-switch
(2)Map Task选择策略
用户追踪作业运行状态的org.apache.hadoop.mapred.JobInProgress.java对象为Map Task维护了五个数据结构:
// NetworkTopology Node to the set of TIPs
Map<Node, List<TaskInProgress>> nonRunningMapCache;//Node与未运行的TIP集合映射关系,通过作业的InputFormat可直接获取的
// Map of NetworkTopology Node to set of running TIPs
Map<Node, Set<TaskInProgress>> runningMapCache;//Node与运行的TIP集合映射关系,一个任务获得调度机会,其TIP便会添加进来
// A list of non-local, non-running maps
final List<TaskInProgress> nonLocalMaps;//non-local且未运行的TIP集合,non-local是指任务没有输入数据(InputSplit为空),//这可能是一些计算密集型任务,比如Hadoop example中的PI作业
// Set of failed, non-running maps sorted by #failures
final SortedSet<TaskInProgress> failedMaps;//按照Task Attempt失败次数排序的TIP集合
// A set of non-local running maps
Set<TaskInProgress> nonLocalRunningMaps;//non-local且正在运行的TIP集合当TaskTracker通过心跳机制向jobTracker询问是否有任务时,会调用org.apache.hadoop.mapred.JobTracker.java的heartbeat方法,在heartbeat方法中会调用org.apache.hadoop.mapred.TaskScheduler.java中的assignTasks方法,以默认调度器org.apache.hadoop.mapred.JobQueueTaskScheduler.java为例,它的assignTasks方法如下:
@Override
public synchronized List<Task> assignTasks(TaskTracker taskTracker)
throws IOException {
// Check for JT safe-mode
if (taskTrackerManager.isInSafeMode()) {
LOG.info("JobTracker is in safe-mode, not scheduling any tasks.");
return null;
}
TaskTrackerStatus taskTrackerStatus = taskTracker.getStatus();
ClusterStatus clusterStatus = taskTrackerManager.getClusterStatus();
final int numTaskTrackers = clusterStatus.getTaskTrackers();
final int clusterMapCapacity = clusterStatus.getMaxMapTasks();
final int clusterReduceCapacity = clusterStatus.getMaxReduceTasks();
Collection<JobInProgress> jobQueue =
jobQueueJobInProgressListener.getJobQueue();
//
// Get map + reduce counts for the current tracker.
//
final int trackerMapCapacity = taskTrackerStatus.getMaxMapSlots();
final int trackerReduceCapacity = taskTrackerStatus.getMaxReduceSlots();
final int trackerRunningMaps = taskTrackerStatus.countMapTasks();
final int trackerRunningReduces = taskTrackerStatus.countReduceTasks();
// Assigned tasks
List<Task> assignedTasks = new ArrayList<Task>();
//
// Compute (running + pending) map and reduce task numbers across pool
//
int remainingReduceLoad = 0;
int remainingMapLoad = 0;
synchronized (jobQueue) {
for (JobInProgress job : jobQueue) {
if (job.getStatus().getRunState() == JobStatus.RUNNING) {
remainingMapLoad += (job.desiredMaps() - job.finishedMaps());
if (job.scheduleReduces()) {
remainingReduceLoad +=
(job.desiredReduces() - job.finishedReduces());
}
}
}
}
// Compute the 'load factor' for maps and reduces
double mapLoadFactor = 0.0;
if (clusterMapCapacity > 0) {
mapLoadFactor = (double)remainingMapLoad / clusterMapCapacity;
}
double reduceLoadFactor = 0.0;
if (clusterReduceCapacity > 0) {
reduceLoadFactor = (double)remainingReduceLoad / clusterReduceCapacity;
}
//
// In the below steps, we allocate first map tasks (if appropriate),
// and then reduce tasks if appropriate. We go through all jobs
// in order of job arrival; jobs only get serviced if their
// predecessors are serviced, too.
//
//
// We assign tasks to the current taskTracker if the given machine
// has a workload that's less than the maximum load of that kind of
// task.
// However, if the cluster is close to getting loaded i.e. we don't
// have enough _padding_ for speculative executions etc., we only
// schedule the "highest priority" task i.e. the task from the job
// with the highest priority.
//
final int trackerCurrentMapCapacity =
Math.min((int)Math.ceil(mapLoadFactor * trackerMapCapacity),
trackerMapCapacity);
int availableMapSlots = trackerCurrentMapCapacity - trackerRunningMaps;
boolean exceededMapPadding = false;
if (availableMapSlots > 0) {
exceededMapPadding =
exceededPadding(true, clusterStatus, trackerMapCapacity);
}
int numLocalMaps = 0;
int numNonLocalMaps = 0;
scheduleMaps:
for (int i=0; i < availableMapSlots; ++i) {
synchronized (jobQueue) {
for (JobInProgress job : jobQueue) {
if (job.getStatus().getRunState() != JobStatus.RUNNING) {
continue;
}
Task t = null;
// Try to schedule a Map task with locality between node-local
// and rack-local
t =
job.obtainNewNodeOrRackLocalMapTask(taskTrackerStatus,
numTaskTrackers, taskTrackerManager.getNumberOfUniqueHosts());
if (t != null) {
assignedTasks.add(t);
++numLocalMaps;
// Don't assign map tasks to the hilt!
// Leave some free slots in the cluster for future task-failures,
// speculative tasks etc. beyond the highest priority job
if (exceededMapPadding) {
break scheduleMaps;
}
// Try all jobs again for the next Map task
break;
}
// Try to schedule a node-local or rack-local Map task
t =
job.obtainNewNonLocalMapTask(taskTrackerStatus, numTaskTrackers,
taskTrackerManager.getNumberOfUniqueHosts());
if (t != null) {
assignedTasks.add(t);
++numNonLocalMaps;
// We assign at most 1 off-switch or speculative task
// This is to prevent TaskTrackers from stealing local-tasks
// from other TaskTrackers.
break scheduleMaps;
}
}
}
}
int assignedMaps = assignedTasks.size();
//
// Same thing, but for reduce tasks
// However we _never_ assign more than 1 reduce task per heartbeat
//
final int trackerCurrentReduceCapacity =
Math.min((int)Math.ceil(reduceLoadFactor * trackerReduceCapacity),
trackerReduceCapacity);
final int availableReduceSlots =
Math.min((trackerCurrentReduceCapacity - trackerRunningReduces), 1);
boolean exceededReducePadding = false;
if (availableReduceSlots > 0) {
exceededReducePadding = exceededPadding(false, clusterStatus,
trackerReduceCapacity);
synchronized (jobQueue) {
for (JobInProgress job : jobQueue) {
if (job.getStatus().getRunState() != JobStatus.RUNNING ||
job.numReduceTasks == 0) {
continue;
}
Task t =
job.obtainNewReduceTask(taskTrackerStatus, numTaskTrackers,
taskTrackerManager.getNumberOfUniqueHosts()
);
if (t != null) {
assignedTasks.add(t);
break;
}
// Don't assign reduce tasks to the hilt!
// Leave some free slots in the cluster for future task-failures,
// speculative tasks etc. beyond the highest priority job
if (exceededReducePadding) {
break;
}
}
}
}
if (LOG.isDebugEnabled()) {
LOG.debug("Task assignments for " + taskTrackerStatus.getTrackerName() + " --> " +
"[" + mapLoadFactor + ", " + trackerMapCapacity + ", " +
trackerCurrentMapCapacity + ", " + trackerRunningMaps + "] -> [" +
(trackerCurrentMapCapacity - trackerRunningMaps) + ", " +
assignedMaps + " (" + numLocalMaps + ", " + numNonLocalMaps +
")] [" + reduceLoadFactor + ", " + trackerReduceCapacity + ", " +
trackerCurrentReduceCapacity + "," + trackerRunningReduces +
"] -> [" + (trackerCurrentReduceCapacity - trackerRunningReduces) +
", " + (assignedTasks.size()-assignedMaps) + "]");
}
return assignedTasks;
}Hadoop以队列为单位管理作业和资源,每个队列分配有一定量的资源,同时管理员可指定每个队列中资源的使用者以防止资源滥用。添加“队列”这一概念后,现有的Hadoop调度器本质上均采用了三级调度模型。如图所示
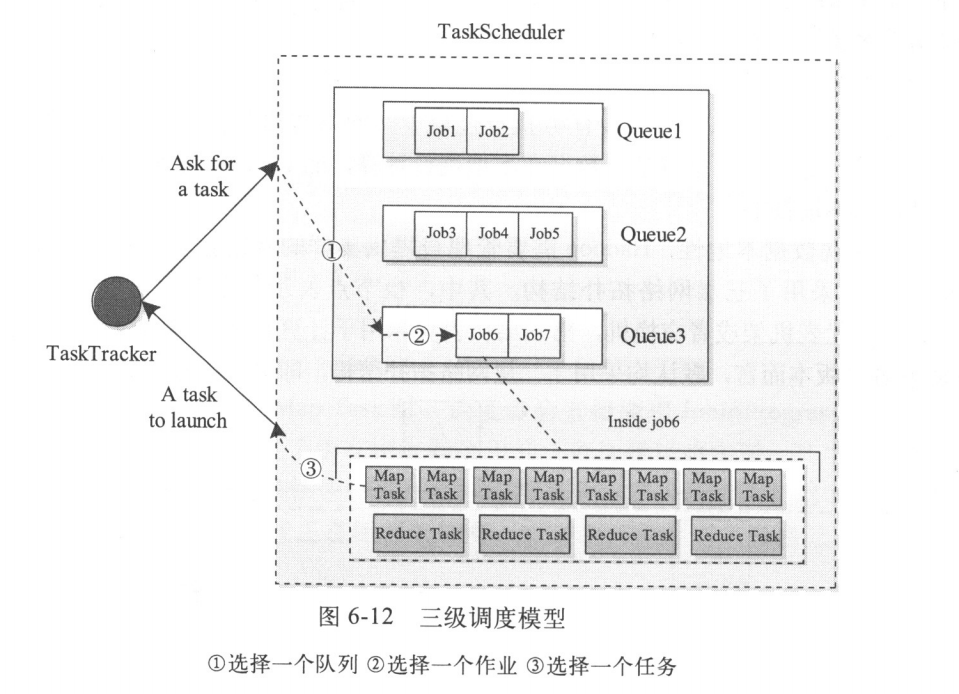
当一个TaskTracker出现空闲资源时,调度器会依次选择一个队列、(选中队列中的)作业和(选中作业中的)任务,并最终将这个任务分配给TaskTracker。
在Hadoop中,不同任务调度器的主要区别在于队列选择策略和作业选择策略不同,而任务选择策略通常是相同的,也就是说,给定一个节点,从一个作业中选择一个任务需要考虑的因素是一样的,均主要为数据本地性(data-locality)。总之,一个任务调度器通用的assignTasks函数伪代码实现如下:
//为TaskTracker分配任务,并返回任务列表
List<Task> assignTasks(TaskTracker taskTracker):
List<Task> taskList ;
while taskTracker.askForTasks() : //不断分配新的任务
Queue queue = selectAQueueFromCluster(); //从系统中选择一个队列
JobInProgress job = selectAJobFromQueue(queue) ; //从队列中选择一个作业
Task tak = job.obtainNewTask(job) ; //从作业中选择一个任务
taskList.add(task) ;
taskTracker.addNewTask(task) ;
return taskList ;由于不同调度器采用的任务选择策略是一样的,因此Hadoop将之封装成一个通用的模块供各个调度器使用,具体存放在JobInProgress类中的obtainNewMapTask和obtainNewReduceTask方法中。
在org.apache.hadoop.mapred.JobInProgress.java中的obtainNewMapTask方法如下:
/////////////////////////////////////////////////////
// Create/manage tasks
/////////////////////////////////////////////////////
/**
* Return a MapTask, if appropriate, to run on the given tasktracker
*/
public synchronized Task obtainNewMapTask(TaskTrackerStatus tts,
int clusterSize,
int numUniqueHosts
) throws IOException {
return obtainNewMapTaskCommon(tts, clusterSize, numUniqueHosts,
anyCacheLevel);
}调用 org.apache.hadoop.mapred.JobInProgress.java中的obtainNewMapTaskCommon
/**
* Return a MapTask with locality level that smaller or equal than a given
* locality level to tasktracker.
*
* @param tts The task tracker that is asking for a task
* @param clusterSize The number of task trackers in the cluster
* @param numUniqueHosts The number of hosts that run task trackers
* @param avgProgress The average progress of this kind of task in this job
* @param maxCacheLevel The maximum topology level until which to schedule
* maps.
* @return the index in tasks of the selected task (or -1 for no task)
* @throws IOException
*/
public synchronized Task obtainNewMapTaskCommon(
TaskTrackerStatus tts, int clusterSize, int numUniqueHosts,
int maxCacheLevel) throws IOException {
if (!tasksInited) {
LOG.info("Cannot create task split for " + profile.getJobID());
try { throw new IOException("state = " + status.getRunState()); }
catch (IOException ioe) {ioe.printStackTrace();}
return null;
}
int target = findNewMapTask(tts, clusterSize, numUniqueHosts, maxCacheLevel,
status.mapProgress());
if (target == -1) {
return null;
}
Task result = maps[target].getTaskToRun(tts.getTrackerName());
if (result != null) {
addRunningTaskToTIP(maps[target], result.getTaskID(), tts, true);
// DO NOT reset for off-switch!
if (maxCacheLevel != NON_LOCAL_CACHE_LEVEL) {
resetSchedulingOpportunities();
}
}
return result;
}调用org.apache.hadoop.mapred.JobInProgress.java中的findNewMapTask方法
/**
* Find new map task
* @param tts The task tracker that is asking for a task
* @param clusterSize The number of task trackers in the cluster
* @param numUniqueHosts The number of hosts that run task trackers
* @param avgProgress The average progress of this kind of task in this job
* @param maxCacheLevel The maximum topology level until which to schedule
* maps.
* A value of {@link #anyCacheLevel} implies any
* available task (node-local, rack-local, off-switch and
* speculative tasks).
* A value of {@link #NON_LOCAL_CACHE_LEVEL} implies only
* off-switch/speculative tasks should be scheduled.
* @return the index in tasks of the selected task (or -1 for no task)
*/
private synchronized int findNewMapTask(final TaskTrackerStatus tts,
final int clusterSize,
final int numUniqueHosts,
final int maxCacheLevel,
final double avgProgress) {
if (numMapTasks == 0) {
if(LOG.isDebugEnabled()) {
LOG.debug("No maps to schedule for " + profile.getJobID());
}
return -1;
}
String taskTracker = tts.getTrackerName();
TaskInProgress tip = null;
//
// Update the last-known clusterSize
//
this.clusterSize = clusterSize;
if (!shouldRunOnTaskTracker(taskTracker)) {
return -1;
}
// Check to ensure this TaskTracker has enough resources to
// run tasks from this job
long outSize = resourceEstimator.getEstimatedMapOutputSize();
long availSpace = tts.getResourceStatus().getAvailableSpace();
if(availSpace < outSize) {
LOG.warn("No room for map task. Node " + tts.getHost() +
" has " + availSpace +
" bytes free; but we expect map to take " + outSize);
return -1; //see if a different TIP might work better.
}
// When scheduling a map task:
// 0) Schedule a failed task without considering locality
// 1) Schedule non-running tasks
// 2) Schedule speculative tasks
// 3) Schedule tasks with no location information
// First a look up is done on the non-running cache and on a miss, a look
// up is done on the running cache. The order for lookup within the cache:
// 1. from local node to root [bottom up]
// 2. breadth wise for all the parent nodes at max level
// We fall to linear scan of the list ((3) above) if we have misses in the
// above caches
// 0) Schedule the task with the most failures, unless failure was on this
// machine
tip = findTaskFromList(failedMaps, tts, numUniqueHosts, false);
if (tip != null) {
// Add to the running list
scheduleMap(tip);
LOG.info("Choosing a failed task " + tip.getTIPId());
return tip.getIdWithinJob();
}
Node node = jobtracker.getNode(tts.getHost());
//
// 1) Non-running TIP :
//
// 1. check from local node to the root [bottom up cache lookup]
// i.e if the cache is available and the host has been resolved
// (node!=null)
if (node != null) {
Node key = node;
int level = 0;
// maxCacheLevel might be greater than this.maxLevel if findNewMapTask is
// called to schedule any task (local, rack-local, off-switch or
// speculative) tasks or it might be NON_LOCAL_CACHE_LEVEL (i.e. -1) if
// findNewMapTask is (i.e. -1) if findNewMapTask is to only schedule
// off-switch/speculative tasks
int maxLevelToSchedule = Math.min(maxCacheLevel, maxLevel);
for (level = 0;level < maxLevelToSchedule; ++level) {
List <TaskInProgress> cacheForLevel = nonRunningMapCache.get(key);
if (cacheForLevel != null) {
tip = findTaskFromList(cacheForLevel, tts,
numUniqueHosts,level == 0);
if (tip != null) {
// Add to running cache
scheduleMap(tip);
// remove the cache if its empty
if (cacheForLevel.size() == 0) {
nonRunningMapCache.remove(key);
}
return tip.getIdWithinJob();
}
}
key = key.getParent();
}
// Check if we need to only schedule a local task (node-local/rack-local)
if (level == maxCacheLevel) {
return -1;
}
}
//2. Search breadth-wise across parents at max level for non-running
// TIP if
// - cache exists and there is a cache miss
// - node information for the tracker is missing (tracker's topology
// info not obtained yet)
// collection of node at max level in the cache structure
Collection<Node> nodesAtMaxLevel = jobtracker.getNodesAtMaxLevel();
// get the node parent at max level
Node nodeParentAtMaxLevel =
(node == null) ? null : JobTracker.getParentNode(node, maxLevel - 1);
for (Node parent : nodesAtMaxLevel) {
// skip the parent that has already been scanned
if (parent == nodeParentAtMaxLevel) {
continue;
}
List<TaskInProgress> cache = nonRunningMapCache.get(parent);
if (cache != null) {
tip = findTaskFromList(cache, tts, numUniqueHosts, false);
if (tip != null) {
// Add to the running cache
scheduleMap(tip);
// remove the cache if empty
if (cache.size() == 0) {
nonRunningMapCache.remove(parent);
}
LOG.info("Choosing a non-local task " + tip.getTIPId());
return tip.getIdWithinJob();
}
}
}
// 3. Search non-local tips for a new task
tip = findTaskFromList(nonLocalMaps, tts, numUniqueHosts, false);
if (tip != null) {
// Add to the running list
scheduleMap(tip);
LOG.info("Choosing a non-local task " + tip.getTIPId());
return tip.getIdWithinJob();
}
//
// 2) Running TIP :
//
if (hasSpeculativeMaps) {
long currentTime = jobtracker.getClock().getTime();
// 1. Check bottom up for speculative tasks from the running cache
if (node != null) {
Node key = node;
for (int level = 0; level < maxLevel; ++level) {
Set<TaskInProgress> cacheForLevel = runningMapCache.get(key);
if (cacheForLevel != null) {
tip = findSpeculativeTask(cacheForLevel, tts,
avgProgress, currentTime, level == 0);
if (tip != null) {
if (cacheForLevel.size() == 0) {
runningMapCache.remove(key);
}
return tip.getIdWithinJob();
}
}
key = key.getParent();
}
}
// 2. Check breadth-wise for speculative tasks
for (Node parent : nodesAtMaxLevel) {
// ignore the parent which is already scanned
if (parent == nodeParentAtMaxLevel) {
continue;
}
Set<TaskInProgress> cache = runningMapCache.get(parent);
if (cache != null) {
tip = findSpeculativeTask(cache, tts, avgProgress,
currentTime, false);
if (tip != null) {
// remove empty cache entries
if (cache.size() == 0) {
runningMapCache.remove(parent);
}
LOG.info("Choosing a non-local task " + tip.getTIPId()
+ " for speculation");
return tip.getIdWithinJob();
}
}
}
// 3. Check non-local tips for speculation
tip = findSpeculativeTask(nonLocalRunningMaps, tts, avgProgress,
currentTime, false);
if (tip != null) {
LOG.info("Choosing a non-local task " + tip.getTIPId()
+ " for speculation");
return tip.getIdWithinJob();
}
}
return -1;
}
在findNewMapTask方法中。其主要思想是优先选择运行失败的任务,以让其快速获取重新运行的机会,其次是按照数据本地性策略选择尚未运行的任务,最后是查找正在运行的任务,尝试为“拖后腿”任务启动备份任务。
具体步骤如下:
1)合法性检查。如果一个作业在某个节点上失败任务数目超过一定阈值或者该节点剩余磁盘容量不足,则不再将该作业的任何任务分配给该节点
// Check to ensure this TaskTracker has enough resources to
// run tasks from this job
long outSize = resourceEstimator.getEstimatedMapOutputSize();
long availSpace = tts.getResourceStatus().getAvailableSpace();
if(availSpace < outSize) {
LOG.warn("No room for map task. Node " + tts.getHost() +
" has " + availSpace +
" bytes free; but we expect map to take " + outSize);
return -1; //see if a different TIP might work better.
}
2)从failedMaps列表中选择任务。failedMaps保存了按照Task Attempt失败次数排序的TIP集合。失败次数越多的任务,被调度的机会越大。需要注意的是,为了让失败的任务快速得到重新运行的机会,在进行任务选择时不再考虑数据本地性。
// When scheduling a map task:
// 0) Schedule a failed task without considering locality
// 1) Schedule non-running tasks
// 2) Schedule speculative tasks
// 3) Schedule tasks with no location information
// First a look up is done on the non-running cache and on a miss, a look
// up is done on the running cache. The order for lookup within the cache:
// 1. from local node to root [bottom up]
// 2. breadth wise for all the parent nodes at max level
// We fall to linear scan of the list ((3) above) if we have misses in the
// above caches
// 0) Schedule the task with the most failures, unless failure was on this
// machine
tip = findTaskFromList(failedMaps, tts, numUniqueHosts, false);
if (tip != null) {
// Add to the running list
scheduleMap(tip);
LOG.info("Choosing a failed task " + tip.getTIPId());
return tip.getIdWithinJob();
}3)从nonRunningMapCache列表中选择任务。采用的任务选择方法完全遵循数据本地性策略,即任务选择优先级从高到低依次为node-local,rack-local和off-switch类型的任务
Node node = jobtracker.getNode(tts.getHost());
//
// 1) Non-running TIP :
//
// 1. check from local node to the root [bottom up cache lookup]
// i.e if the cache is available and the host has been resolved
// (node!=null)
if (node != null) {
Node key = node;
int level = 0;
// maxCacheLevel might be greater than this.maxLevel if findNewMapTask is
// called to schedule any task (local, rack-local, off-switch or
// speculative) tasks or it might be NON_LOCAL_CACHE_LEVEL (i.e. -1) if
// findNewMapTask is (i.e. -1) if findNewMapTask is to only schedule
// off-switch/speculative tasks
int maxLevelToSchedule = Math.min(maxCacheLevel, maxLevel);
for (level = 0;level < maxLevelToSchedule; ++level) {
List <TaskInProgress> cacheForLevel = nonRunningMapCache.get(key);
if (cacheForLevel != null) {
tip = findTaskFromList(cacheForLevel, tts,
numUniqueHosts,level == 0);
if (tip != null) {
// Add to running cache
scheduleMap(tip);
// remove the cache if its empty
if (cacheForLevel.size() == 0) {
nonRunningMapCache.remove(key);
}
return tip.getIdWithinJob();
}
}
key = key.getParent();
}
// Check if we need to only schedule a local task (node-local/rack-local)
if (level == maxCacheLevel) {
return -1;
}
}
//2. Search breadth-wise across parents at max level for non-running
// TIP if
// - cache exists and there is a cache miss
// - node information for the tracker is missing (tracker's topology
// info not obtained yet)
// collection of node at max level in the cache structure
Collection<Node> nodesAtMaxLevel = jobtracker.getNodesAtMaxLevel();
// get the node parent at max level
Node nodeParentAtMaxLevel =
(node == null) ? null : JobTracker.getParentNode(node, maxLevel - 1);
for (Node parent : nodesAtMaxLevel) {
// skip the parent that has already been scanned
if (parent == nodeParentAtMaxLevel) {
continue;
}
List<TaskInProgress> cache = nonRunningMapCache.get(parent);
if (cache != null) {
tip = findTaskFromList(cache, tts, numUniqueHosts, false);
if (tip != null) {
// Add to the running cache
scheduleMap(tip);
// remove the cache if empty
if (cache.size() == 0) {
nonRunningMapCache.remove(parent);
}
LOG.info("Choosing a non-local task " + tip.getTIPId());
return tip.getIdWithinJob();
}
}
}4)从nonLocalMaps列表中选择任务。由于nonLocalMaps中的任务没有输入数据,因此无需考虑数据本地性。
// 3. Search non-local tips for a new task
tip = findTaskFromList(nonLocalMaps, tts, numUniqueHosts, false);
if (tip != null) {
// Add to the running list
scheduleMap(tip);
LOG.info("Choosing a non-local task " + tip.getTIPId());
return tip.getIdWithinJob();
}5)从runningMapCache列表中选择任务。遍历runningMapCache列表,查找是否存在正运行且“拖后腿”的任务,如果有,则为其启动一个备份任务。
//
// 2) Running TIP :
//
if (hasSpeculativeMaps) {
long currentTime = jobtracker.getClock().getTime();
// 1. Check bottom up for speculative tasks from the running cache
if (node != null) {
Node key = node;
for (int level = 0; level < maxLevel; ++level) {
Set<TaskInProgress> cacheForLevel = runningMapCache.get(key);
if (cacheForLevel != null) {
tip = findSpeculativeTask(cacheForLevel, tts,
avgProgress, currentTime, level == 0);
if (tip != null) {
if (cacheForLevel.size() == 0) {
runningMapCache.remove(key);
}
return tip.getIdWithinJob();
}
}
key = key.getParent();
}
}
// 2. Check breadth-wise for speculative tasks
for (Node parent : nodesAtMaxLevel) {
// ignore the parent which is already scanned
if (parent == nodeParentAtMaxLevel) {
continue;
}
Set<TaskInProgress> cache = runningMapCache.get(parent);
if (cache != null) {
tip = findSpeculativeTask(cache, tts, avgProgress,
currentTime, false);
if (tip != null) {
// remove empty cache entries
if (cache.size() == 0) {
runningMapCache.remove(parent);
}
LOG.info("Choosing a non-local task " + tip.getTIPId()
+ " for speculation");
return tip.getIdWithinJob();
}
}
}6)从nonLocalRunningMaps列表中选择任务。遍历nonLocalRunningMaps列表,查找“拖后腿”任务,并为其启动备份任务。
步骤2~6中任何一个步骤中查找到一个合适的任务后则直接返回,不再进行下面的步骤。
(3)Reduce Task选择策略
由于Reduce Task不存在数据本地性,因此,与Map Task相比,它的调度策略显得非常简单。JobInProgress对象为其保存了两个数据结构:nonRunningReduces和runningReduces,分别表示尚未运行的TIP列表和正在运行的TIP列表。
在org.apache.hadoop.mapred.JobInProgress.java中的obtainNewReduceTask方法如下:
/**
* Return a ReduceTask, if appropriate, to run on the given tasktracker.
* We don't have cache-sensitivity for reduce tasks, as they
* work on temporary MapRed files.
*/
public synchronized Task obtainNewReduceTask(TaskTrackerStatus tts,
int clusterSize,
int numUniqueHosts
) throws IOException {
if (status.getRunState() != JobStatus.RUNNING) {
LOG.info("Cannot create task split for " + profile.getJobID());
return null;
}
/** check to see if we have any misbehaving reducers. If the expected output
* for reducers is huge then we just fail the job and error out. The estimated
* size is divided by 2 since the resource estimator returns the amount of disk
* space the that the reduce will use (which is 2 times the input, space for merge + reduce
* input). **/
long estimatedReduceInputSize = resourceEstimator.getEstimatedReduceInputSize()/2;
if (((estimatedReduceInputSize) >
reduce_input_limit) && (reduce_input_limit > 0L)) {
// make sure jobtracker lock is held
LOG.info("Exceeded limit for reduce input size: Estimated:" +
estimatedReduceInputSize + " Limit: " +
reduce_input_limit + " Failing Job " + jobId);
status.setFailureInfo("Job exceeded Reduce Input limit "
+ " Limit: " + reduce_input_limit +
" Estimated: " + estimatedReduceInputSize);
jobtracker.failJob(this);
return null;
}
// Ensure we have sufficient map outputs ready to shuffle before
// scheduling reduces
if (!scheduleReduces()) {
return null;
}
int target = findNewReduceTask(tts, clusterSize, numUniqueHosts,
status.reduceProgress());
if (target == -1) {
return null;
}
Task result = reduces[target].getTaskToRun(tts.getTrackerName());
if (result != null) {
addRunningTaskToTIP(reduces[target], result.getTaskID(), tts, true);
}
return result;
}调用org.apache.hadoop.mapred.JobInProgress.java中的findNewReduceTask方法
/**
* Find new reduce task
* @param tts The task tracker that is asking for a task
* @param clusterSize The number of task trackers in the cluster
* @param numUniqueHosts The number of hosts that run task trackers
* @param avgProgress The average progress of this kind of task in this job
* @return the index in tasks of the selected task (or -1 for no task)
*/
private synchronized int findNewReduceTask(TaskTrackerStatus tts,
int clusterSize,
int numUniqueHosts,
double avgProgress) {
if (numReduceTasks == 0) {
if(LOG.isDebugEnabled()) {
LOG.debug("No reduces to schedule for " + profile.getJobID());
}
return -1;
}
String taskTracker = tts.getTrackerName();
TaskInProgress tip = null;
// Update the last-known clusterSize
this.clusterSize = clusterSize;
if (!shouldRunOnTaskTracker(taskTracker)) {
return -1;
}
// 1. check for a never-executed reduce tip
// reducers don't have a cache and so pass -1 to explicitly call that out
tip = findTaskFromList(nonRunningReduces, tts, numUniqueHosts, false);
if (tip != null) {
scheduleReduce(tip);
return tip.getIdWithinJob();
}
// 2. check for a reduce tip to be speculated
if (hasSpeculativeReduces) {
tip = findSpeculativeTask(runningReduces, tts, avgProgress,
jobtracker.getClock().getTime(), false);
if (tip != null) {
scheduleReduce(tip);
return tip.getIdWithinJob();
}
}
return -1;
}任务选择步骤如下:
1)合法性检查。同Map Task一样,对节点可靠性和磁盘空间进行检查。
if (!shouldRunOnTaskTracker(taskTracker)) {
return -1;
}2)从nonRunningReduces列表中选择任务。无需考虑数据本地性,只需依次遍历该列表中的任务,选出第一个满足条件(未曾在对应节点上失败过)的任务。
// 1. check for a never-executed reduce tip
// reducers don't have a cache and so pass -1 to explicitly call that out
tip = findTaskFromList(nonRunningReduces, tts, numUniqueHosts, false);
if (tip != null) {
scheduleReduce(tip);
return tip.getIdWithinJob();
}3)从runningReduces列表中选择任务,为“拖后腿”的任务启动备份任务
// 2. check for a reduce tip to be speculated
if (hasSpeculativeReduces) {
tip = findSpeculativeTask(runningReduces, tts, avgProgress,
jobtracker.getClock().getTime(), false);
if (tip != null) {
scheduleReduce(tip);
return tip.getIdWithinJob();
}
}














 176
176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









