







决策树方法在分类、预测、规则提取等领域有着广泛的应用。在20世纪70年代后期和80年代初期,机器学习研究者J.Ross Quinilan提出了ID3算法以后,决策树在机器学习、数据挖掘领域得到极大的发展。Quinilan后来又提出了C4.5,成为新的监督学习算法。1984年几位统计学家提出了CART分类算法。ID3和ART算法大约同时被提出,但都是采用类似的方法从训练样本中学习决策树的。
决策树是一树状结构,它的每一个叶子节点对应着一个分类,非叶子节点对应着在某个属性上的划分,根据样本在该属性上的不同取值将其划分成若干个子集。构造决策树的核心问题是在每一步如何选择适当的属性对样本进行拆分。对一个分类问题,从已知类标记的训练样本中学习并构造出决策树是一个自上而下分而治之的过程。
常用的决策树算法如图所示。

本文将详细介绍ID3算法,其也是最经典的决策树分类算法。
1、ID3算法简介及基本原理
ID3算法基于信息熵来选择最佳的测试属性,它选择当前样本集中具有最大信息增益值的属性作为测试属性;样本集的划分则依据测试属性的取值进行,测试属性有多少个不同的取值就将样本集划分为多少个子样本集,同时决策树上相应于该样本集的节点长出新的叶子节点。ID3算法根据信息论的理论,采用划分后样本集的不确定性作为衡量划分好坏的标准,用信息增益值度量不确定性:信息增益值越大,不确定性越小。因此,ID3算法在每个非叶节点选择信息增益最大的属性作为测试属性,这样可以得到当前情况下最纯的划分,从而得到较小的决策树。
设S是s个数据样本的集合。假定类别属性具有m个不同的值: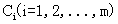
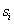
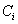
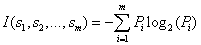
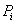
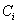
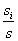
设一个属性A具有k个不同的值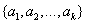
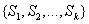
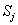
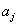
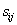
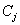
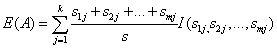
其中,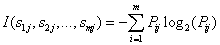
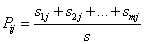
最后,用属性A划分样本集S后所得的信息增益(Gain)为
显然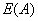
2、ID3算法的具体流程
ID3算法的具体流程如下:
1)对当前样本集合,计算所有属性的信息增益;
2)选择信息增益最大的属性作为测试属性,把测试属性取值相同的样本划为同一个子样本集;
3)若子样本集的类别属性只含有单个属性,则分支为叶子节点,判断其属性值并标上相应的符号,然后返回调用处;否则对子样本集递归调用本算法。
数据如图所示
序号 天气 是否周末 是否有促销 销量
1 坏 是 是 高
2 坏 是 是 高
3 坏 是 是 高
4 坏 否 是 高
5 坏 是 是 高
6 坏 否 是 高
7 坏 是 否 高
8 好 是 是 高
9 好 是 否 高
10 好 是 是 高
11 好 是 是 高
12 好 是 是 高
13 好 是 是 高
14 坏 是 是 低
15 好 否 是 高
16 好 否 是 高
17 好 否 是 高
18 好 否 是 高
19 好 否 否 高
20 坏 否 否 低
21 坏 否 是 低
22 坏 否 是 低
23 坏 否 是 低
24 坏 否 否 低
25 坏 是 否 低
26 好 否 是 低
27 好 否 是 低
28 坏 否 否 低
29 坏 否 否 低
30 好 否 否 低
31 坏 是 否 低
32 好 否 是 低
33 好 否 否 低
34 好 否 否 低
采用ID3算法构建决策树模型的具体步骤如下:
1)根据公式
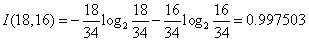
2)根据公式
对于天气属性,其属性值有“好”和“坏”两种。其中天气为“好”的条件下,销售数量为“高”的记录为11,销售数量为“低”的记录为6,可表示为(11,6);天气为“坏”的条件下,销售数量为“高”的记录为7,销售数量为“低”的记录为10,可表示为(7,10)。则天气属性的信息熵计算过程如下:
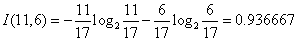
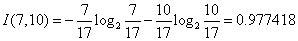
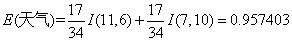
对于是否周末属性,其属性值有“是”和“否”两种。其中是否周末属性为“是”的条件下,销售数量为“高”的记录为11,销售数量为“低”的记录为3,可表示为(11,3);是否周末属性为“否”的条件下,销售数量为“高”的记录为7,销售数量为“低”的记录为13,可表示为(7,13)。则节假日属性的信息熵计算过程如下:
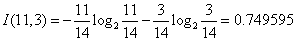
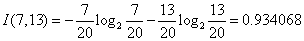
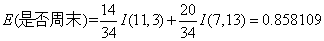
对于是否有促销属性,其属性值有“是”和“否”两种。其中是否有促销属性为“是”的条件下,销售数量为“高”的记录为15,销售数量为“低”的记录为7,可表示为(15,7);其中是否有促销属性为“否”的条件下,销售数量为“高”的记录为3,销售数量为“低”的记录为9,可表示为(3,9)。则是否有促销属性的信息熵计算过程如下:
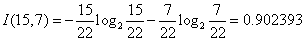
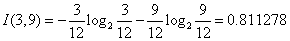
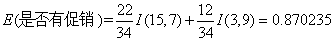
根据公式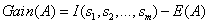
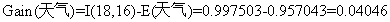


3)由计算结果可以知道是否周末属性的信息增益值最大,它的两个属性值“是”和“否”作为该根节点的两个分支。然后按照上面的步骤继续对该根节点的两个分支进行节点的划分,针对每一个分支节点继续进行信息增益的计算,如此循环反复,直到没有新的节点分支,最终构成一棵决策树。生成的决策树模型如图所示
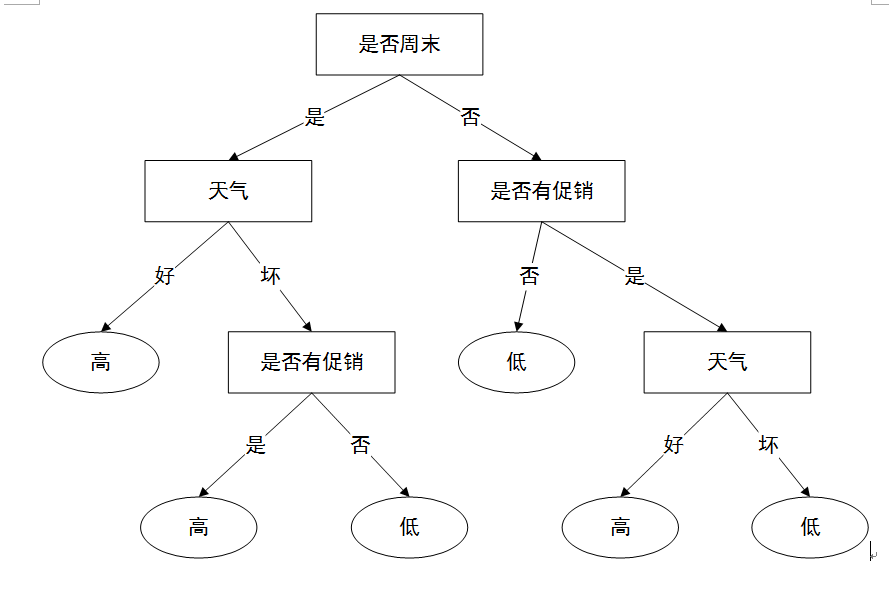
若周末属性为“是”,天气为“好”,则销售数量为“高”;
若周末属性为“是”,天气为“坏”,促销属性为“是”,则销售数量为“高”;
若周末属性为“是”,天气为“坏”,促销属性为“否”,则销售数量为“低”;
若周末属性为“否”,促销属性为“否”,则销售数量为“低”;
若周末属性为“否”,促销属性为“是”,天气为“好”,则销售数量为“高”;
若周末属性为“否”,促销属性为“是”,天气为“坏”,则销售数量为“低”;
由于ID3决策树算法采用了信息增益作为选择测试属性的标准,会偏向于选择取值较多的即所谓的高度分支属性,而这类属性并不一定是最优的属性。同时ID3决策树算法只能处理离散属性,对于连续型的属性,在分类前需要对其进行离散化。为了解决倾向于选择高度分支属性的问题,人们采用信息增益率作为选择测试属性的标准,这样便得到C4.5决策树的算法。此外常用的决策树算法还有CART算法、SLIQ算法、SPRINT算法和PUBLIC算法等等。
使用ID3算法建立决策树的MATLAB代码如下所示
ID3_decision_tree.m
%% 使用ID3决策树算法预测销量高低
clear ;
%% 数据预处理
disp( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1880
1880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









