







操作系统以线程为最小执行单位,在Linux中进程与线程不作区分。
本节我们先讨论进程的一些静态特性,然后描述进程的创建和撤销。最后研究内核如何切换进程。
进程、轻量级进程和线程
进程的概念一直比较模糊,在Linux系统中的进程具有好下的要素:有一段程序供其执行,有专用的系统堆栈空间,有用作描述其主要特性的task_struct结构体,有专用的用户空间。
当具备前两条而没有第四条时,称其为线程。如果完全没有用户空间,就称其为内核线程。如果共享用户空间就称为用户线程。
在Linux中具有父进程、进程组等概念。当一个进程创建时,它几乎与父进程相同。它接受父进程的地址空间的一个逻辑拷贝,并从进程创建系统调用的下一条指令开始执行与父进程相同的代码。
Linux内核早期并没有对多线程应用的支持。从内核来看,多线程应用程序仅仅是一个普通进程。多线程应用程序多个执行流的创建、处理、调度整个都在用户态进行。
现在Linux使用轻量级进程LWP对多线程应用程序提供更好的支持。两个轻量级进程基本上可以共享一些资源,如地址空间、打开的文件等。只要一个修改共享资源,另一个就能立即查看这种修改。当然,两个线程访问共享资源时必须同步。
实现多线程的一个简单方式是把轻量级进程与每个线程关联起来。
POSIX兼容的多线程应用程序由支持“线程组”的内容来处理最好不过。在Linux中,一个线程组基本上就是实现了多线程应用的一组轻量级进程。
进程描述符
内核用进程描述符来描述进程,它们都是task_struct结构体。
================ include/linux/sched.h 1181 1514 ==============
1181 struct task_struct {
1182 volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
1183 void *stack;
1184 atomic_t usage;
1185 unsigned int flags; /* per process flags, defined below */
1186 unsigned int ptrace;
1187
1188 int lock_depth; /* BKL lock depth */
1189
1190 #ifdef CONFIG_SMP
1191 #ifdef __ARCH_WANT_UNLOCKED_CTXSW
1192 int oncpu;
1193 #endif
1194 #endif
1195
1196 int prio, static_prio, normal_prio;
1197 unsigned int rt_priority;
1198 const struct sched_class *sched_class;
1199 struct sched_entity se;
1200 struct sched_rt_entity rt;
1201
1202 #ifdef CONFIG_PREEMPT_NOTIFIERS
1203 /* list of struct preempt_notifier: */
1204 struct hlist_head preempt_notifiers;
1205 #endif
1206
1215 unsigned char fpu_counter;
1216 #ifdef CONFIG_BLK_DEV_IO_TRACE
1217 unsigned int btrace_seq;
1218 #endif
1219
1220 unsigned int policy;
1221 cpumask_t cpus_allowed;
1222
1223 #ifdef CONFIG_PREEMPT_RCU
1224 int rcu_read_lock_nesting;
1225 char rcu_read_unlock_special;
1226 struct list_head rcu_node_entry;
1227 #endif /* #ifdef CONFIG_PREEMPT_RCU */
1228 #ifdef CONFIG_TREE_PREEMPT_RCU
1229 struct rcu_node *rcu_blocked_node;
1230 #endif /* #ifdef CONFIG_TREE_PREEMPT_RCU */
1231
1232 #if defined(CONFIG_SCHEDSTATS) || defined(CONFIG_TASK_DELAY_ACCT)
1233 struct sched_info sched_info;
1234 #endif
1235
1236 struct list_head tasks;
1237 struct plist_node pushable_tasks;
1238
1239 struct mm_struct *mm, *active_mm;
1240 #if defined(SPLIT_RSS_COUNTING)
1241 struct task_rss_stat rss_stat;
1242 #endif
1243 /* task state */
1244 int exit_state;
1245 int exit_code, exit_signal;
1246 int pdeath_signal; /* The signal sent when the parent dies */
1247 /* ??? */
1248 unsigned int personality;
1249 unsigned did_exec:1;
1250 unsigned in_execve:1; /* Tell the LSMs that the process is doing an
1251 * execve */
1252 unsigned in_iowait:1;
1253
1254
1255 /* Revert to default priority/policy when forking */
1256 unsigned sched_reset_on_fork:1;
1257
1258 pid_t pid;
1259 pid_t tgid;
1260
1261 #ifdef CONFIG_CC_STACKPROTECTOR
1262 /* Canary value for the -fstack-protector gcc feature */
1263 unsigned long stack_canary;
1264 #endif
1265
1266 /*
1267 * pointers to (original) parent process, youngest child, younger sibling,
1268 * older sibling, respectively. (p->father can be replaced with
1269 * p->real_parent->pid)
1270 */
1271 struct task_struct *real_parent; /* real parent process */
1272 struct task_struct *parent; /* recipient of SIGCHLD, wait4() reports */
1273 /*
1274 * children/sibling forms the list of my natural children
1275 */
1276 struct list_head children; /* list of my children */
1277 struct list_head sibling; /* linkage in my parent's children list */
1278 struct task_struct *group_leader; /* threadgroup leader */
1279
1285 struct list_head ptraced;
1286 struct list_head ptrace_entry;
1287
1288 /* PID/PID hash table linkage. */
1289 struct pid_link pids[PIDTYPE_MAX];
1290 struct list_head thread_group;
1291
1292 struct completion *vfork_done; /* for vfork() */
1293 int __user *set_child_tid; /* CLONE_CHILD_SETTID */
1294 int __user *clear_child_tid; /* CLONE_CHILD_CLEARTID */
1295
1296 cputime_t utime, stime, utimescaled, stimescaled;
1297 cputime_t gtime;
1298 #ifndef CONFIG_VIRT_CPU_ACCOUNTING
1299 cputime_t prev_utime, prev_stime;
1300 #endif
1301 unsigned long nvcsw, nivcsw; /* context switch counts */
1302 struct timespec start_time; /* monotonic time */
1303 struct timespec real_start_time; /* boot based time */
1304 /* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */
1305 unsigned long min_flt, maj_flt;
1306
1307 struct task_cputime cputime_expires;
1308 struct list_head cpu_timers[3];
1309
1310 /* process credentials */
1311 const struct cred __rcu *real_cred; /* objective and real subjective task
1312 * credentials (COW) */
1313 const struct cred __rcu *cred; /* effective (overridable) subjective task
1314 * credentials (COW) */
1315 struct cred *replacement_session_keyring; /* for KEYCTL_SESSION_TO_PARENT */
1316
1317 char comm[TASK_COMM_LEN]; /* executable name excluding path
1318 - access with [gs]et_task_comm (which lock
1319 it with task_lock())
1320 - initialized normally by setup_new_exec */
1321 /* file system info */
1322 int link_count, total_link_count;
1323 #ifdef CONFIG_SYSVIPC
1324 /* ipc stuff */
1325 struct sysv_sem sysvsem;
1326 #endif
1327 #ifdef CONFIG_DETECT_HUNG_TASK
1328 /* hung task detection */
1329 unsigned long last_switch_count;
1330 #endif
1331 /* CPU-specific state of this task */
1332 struct thread_struct thread;
1333 /* filesystem information */
1334 struct fs_struct *fs;
1335 /* open file information */
1336 struct files_struct *files;
1337 /* namespaces */
1338 struct nsproxy *nsproxy;
1339 /* signal handlers */
1340 struct signal_struct *signal;
1341 struct sighand_struct *sighand;
1342
1343 sigset_t blocked, real_blocked;
1344 sigset_t saved_sigmask; /* restored if set_restore_sigmask() was used */
1345 struct sigpending pending;
1346
1347 unsigned long sas_ss_sp;
1348 size_t sas_ss_size;
1349 int (*notifier)(void *priv);
1350 void *notifier_data;
1351 sigset_t *notifier_mask;
1352 struct audit_context *audit_context;
1353 #ifdef CONFIG_AUDITSYSCALL
1354 uid_t loginuid;
1355 unsigned int sessionid;
1356 #endif
1357 seccomp_t seccomp;
1358
1359 /* Thread group tracking */
1360 u32 parent_exec_id;
1361 u32 self_exec_id;
1362 /* Protection of (de-)allocation: mm, files, fs, tty, keyrings, mems_allowed,
1363 * mempolicy */
1364 spinlock_t alloc_lock;
1365
1366 #ifdef CONFIG_GENERIC_HARDIRQS
1367 /* IRQ handler threads */
1368 struct irqaction *irqaction;
1369 #endif
1370
1371 /* Protection of the PI data structures: */
1372 raw_spinlock_t pi_lock;
1373
1374 #ifdef CONFIG_RT_MUTEXES
1375 /* PI waiters blocked on a rt_mutex held by this task */
1376 struct plist_head pi_waiters;
1377 /* Deadlock detection and priority inheritance handling */
1378 struct rt_mutex_waiter *pi_blocked_on;
1379 #endif
1380
1381 #ifdef CONFIG_DEBUG_MUTEXES
1382 /* mutex deadlock detection */
1383 struct mutex_waiter *blocked_on;
1384 #endif
1385 #ifdef CONFIG_TRACE_IRQFLAGS
1386 unsigned int irq_events;
1387 unsigned long hardirq_enable_ip;
1388 unsigned long hardirq_disable_ip;
1389 unsigned int hardirq_enable_event;
1390 unsigned int hardirq_disable_event;
1391 int hardirqs_enabled;
1392 int hardirq_context;
1393 unsigned long softirq_disable_ip;
1394 unsigned long softirq_enable_ip;
1395 unsigned int softirq_disable_event;
1396 unsigned int softirq_enable_event;
1397 int softirqs_enabled;
1398 int softirq_context;
1399 #endif
1400 #ifdef CONFIG_LOCKDEP
1401 # define MAX_LOCK_DEPTH 48UL
1402 u64 curr_chain_key;
1403 int lockdep_depth;
1404 unsigned int lockdep_recursion;
1405 struct held_lock held_locks[MAX_LOCK_DEPTH];
1406 gfp_t lockdep_reclaim_gfp;
1407 #endif
1408
1409 /* journalling filesystem info */
1410 void *journal_info;
1411
1412 /* stacked block device info */
1413 struct bio_list *bio_list;
1414
1415 /* VM state */
1416 struct reclaim_state *reclaim_state;
1417
1418 struct backing_dev_info *backing_dev_info;
1419
1420 struct io_context *io_context;
1421
1422 unsigned long ptrace_message;
1423 siginfo_t *last_siginfo; /* For ptrace use. */
1424 struct task_io_accounting ioac;
1425 #if defined(CONFIG_TASK_XACCT)
1426 u64 acct_rss_mem1; /* accumulated rss usage */
1427 u64 acct_vm_mem1; /* accumulated virtual memory usage */
1428 cputime_t acct_timexpd; /* stime + utime since last update */
1429 #endif
1430 #ifdef CONFIG_CPUSETS
1431 nodemask_t mems_allowed; /* Protected by alloc_lock */
1432 int mems_allowed_change_disable;
1433 int cpuset_mem_spread_rotor;
1434 int cpuset_slab_spread_rotor;
1435 #endif
1436 #ifdef CONFIG_CGROUPS
1437 /* Control Group info protected by css_set_lock */
1438 struct css_set __rcu *cgroups;
1439 /* cg_list protected by css_set_lock and tsk->alloc_lock */
1440 struct list_head cg_list;
1441 #endif
1442 #ifdef CONFIG_FUTEX
1443 struct robust_list_head __user *robust_list;
1444 #ifdef CONFIG_COMPAT
1445 struct compat_robust_list_head __user *compat_robust_list;
1446 #endif
1447 struct list_head pi_state_list;
1448 struct futex_pi_state *pi_state_cache;
1449 #endif
1450 #ifdef CONFIG_PERF_EVENTS
1451 struct perf_event_context *perf_event_ctxp[perf_nr_task_contexts];
1452 struct mutex perf_event_mutex;
1453 struct list_head perf_event_list;
1454 #endif
1455 #ifdef CONFIG_NUMA
1456 struct mempolicy *mempolicy; /* Protected by alloc_lock */
1457 short il_next;
1458 #endif
1459 atomic_t fs_excl; /* holding fs exclusive resources */
1460 struct rcu_head rcu;
1461
1465 struct pipe_inode_info *splice_pipe;
1466 #ifdef CONFIG_TASK_DELAY_ACCT
1467 struct task_delay_info *delays;
1468 #endif
1469 #ifdef CONFIG_FAULT_INJECTION
1470 int make_it_fail;
1471 #endif
1472 struct prop_local_single dirties;
1473 #ifdef CONFIG_LATENCYTOP
1474 int latency_record_count;
1475 struct latency_record latency_record[LT_SAVECOUNT];
1476 #endif
1477 /*
1478 * time slack values; these are used to round up poll() and
1479 * select() etc timeout values. These are in nanoseconds.
1480 */
1481 unsigned long timer_slack_ns;
1482 unsigned long default_timer_slack_ns;
1483
1484 struct list_head *scm_work_list;
1485 #ifdef CONFIG_FUNCTION_GRAPH_TRACER
1486 /* Index of current stored address in ret_stack */
1487 int curr_ret_stack;
1488 /* Stack of return addresses for return function tracing */
1489 struct ftrace_ret_stack *ret_stack;
1490 /* time stamp for last schedule */
1491 unsigned long long ftrace_timestamp;
1492 /*
1493 * Number of functions that haven't been traced
1494 * because of depth overrun.
1495 */
1496 atomic_t trace_overrun;
1497 /* Pause for the tracing */
1498 atomic_t tracing_graph_pause;
1499 #endif
1500 #ifdef CONFIG_TRACING
1501 /* state flags for use by tracers */
1502 unsigned long trace;
1503 /* bitmask of trace recursion */
1504 unsigned long trace_recursion;
1505 #endif /* CONFIG_TRACING */
1506 #ifdef CONFIG_CGROUP_MEM_RES_CTLR /* memcg uses this to do batch job */
1507 struct memcg_batch_info {
1508 int do_batch; /* incremented when batch uncharge started */
1509 struct mem_cgroup *memcg; /* target memcg of uncharge */
1510 unsigned long bytes; /* uncharged usage */
1511 unsigned long memsw_bytes; /* uncharged mem+swap usage */
1512 } memcg_batch;
1513 #endif
1514 };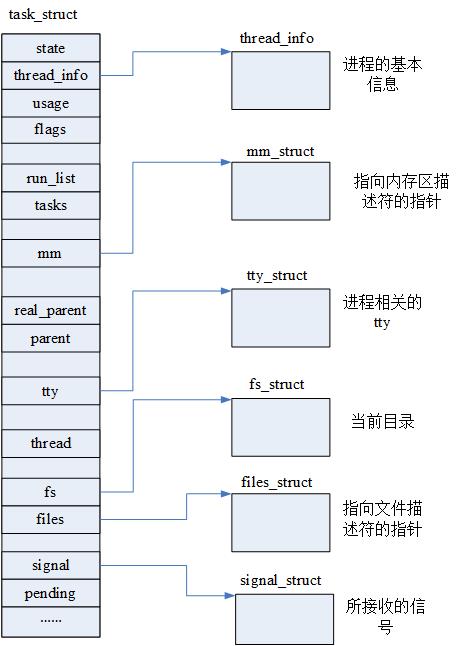
可以看到最常访问的元素在结构体的开始。这符合第一讲中提到的加速原则。
先来讨论进程的状态和父子关系。
进程状态
state字段描述进程状态,它由一组标志组成,每个标志描述一种可能的状态。在当前版本中,这些标志是互斥的。
=============== include/linux/sched.h 181 193 ===============
/*
* Task state bitmask. NOTE! These bits are also
* encoded in fs/proc/array.c: get_task_state().
*
* We have two separate sets of flags: task->state
* is about runnability, while task->exit_state are
* about the task exiting. Confusing, but this way
* modifying one set can't modify the other one by
* mistake.
*/
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
#define __TASK_STOPPED 4
#define __TASK_TRACED 8
/* in tsk->exit_state */
#define EXIT_ZOMBIE 16
#define EXIT_DEAD 32
/* in tsk->state again */
#define TASK_DEAD 64
#define TASK_WAKEKILL 128
#define TASK_WAKING 256
#define TASK_STATE_MAX 512这些状态是:
可运行状态TASK_RUNNING:要么在CPU上执行,要么准备执行。
可中断的等待状态TASK_INTERRUPTIBLE:进程被挂起,直到某个条件变为真。产生一个硬件中断,释放进程正等待的系统资源,或传递一个信号都是可以唤醒进程的条件(把进程的状态放回到TASK_RUNNING)。
不可中断的等待状态TASK_UNINTERRUPTIBLE:与可中断的等待状态类似,但有一个例外,把信号传递到睡眠状态不能改变它的状态。这种状态很少用到,但在一些特定的情况下(进程必须等待,直到一个不能被中断的事件发生),这种状态是很有用的。例如,当进程打开一个设备文件,其相应的设备驱动程序开始探测相应的硬件设备时会用到这种状态。探测完成以前,设备驱动程序不能被中断,否则,硬件设备会处于不可预知的状态。
暂停状态__TASK_STOPPED:进程的执行被暂停,当进程接收到SIGSTOP、SIGTSTP、SIGTTIN或SIGTTOU信号后,进入暂停状态。
跟踪状态__TASK_TRACED:进程的执行已经由debugger程序暂停。当一个进程被另一个进程监控时(例如debugger执行ptrace()系统调用监控一个测试程序),任何信号都可以把这个进程置于__TASK_TRACED。
还有两种状态既可以存在state中,又可以存放在exit_state字段中。从这两个字段的名称可以看出,只有当进程的执行被终止时,进程的状态才会变为这两种状态中的一种:
僵死状态EXIT_ZOMBIE:进程的执行被终止,但父进程还没有发布wait4()或waitpid()系统调用来返回有关死亡进程的信息。发布wait()类系统调用前,内核不能丢弃包含在死进程描述符中的数据。因为父进程可能还需要它。
僵死撤消状态EXIT_DEAD:最终状态,当父进程发出wait()类系统调用后,进程由系统删除。为了防止其他执行线程在同一个进程上也执行wait()类系统调用从而发生竞争,把进程的状态从僵死变为僵死撤消状态。具体在下一讲中详述。
下图是进程的状态转换图。
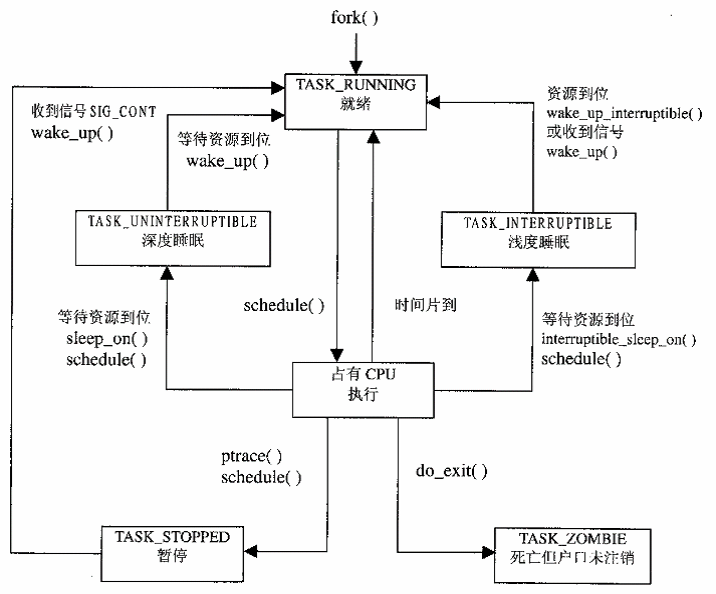
设置一个进程的状态需要调用如下宏,分别设置指定进程状态以及当前进程状态。set_mb宏保证指令顺序不被编译器打乱。下一讲详述。
============== include/linux/sched.h 223 226 ================
#define __set_task_state(tsk, state_value) \
do { (tsk)->state = (state_value); } while (0)
#define set_task_state(tsk, state_value) \
set_mb((tsk)->state, (state_value))
==================== include/linux/sched.h 239 242 ====================
#define __set_current_state(state_value) \
do { current->state = (state_value); } while (0)
#define set_current_state(state_value) \
set_mb(current->state, (state_value))flags也反映进程的状态信息,这些标志位定义为:
==================== include/linux/sched.h 1698 1731 ====================
/*
* Per process flags
*/
#define PF_KSOFTIRQD 0x00000001 /* I am ksoftirqd */
#define PF_STARTING 0x00000002 /* being created */
#define PF_EXITING 0x00000004 /* getting shut down */
#define PF_EXITPIDONE 0x00000008 /* pi exit done on shut down */
#define PF_VCPU 0x00000010 /* I'm a virtual CPU */
#define PF_WQ_WORKER 0x00000020 /* I'm a workqueue worker */
#define PF_FORKNOEXEC 0x00000040 /* forked but didn't exec */
#define PF_MCE_PROCESS 0x00000080 /* process policy on mce errors */
#define PF_SUPERPRIV 0x00000100 /* used super-user privileges */
#define PF_DUMPCORE 0x00000200 /* dumped core */
#define PF_SIGNALED 0x00000400 /* killed by a signal */
#define PF_MEMALLOC 0x00000800 /* Allocating memory */
#define PF_USED_MATH 0x00002000 /* if unset the fpu must be initialized before use */
#define PF_FREEZING 0x00004000 /* freeze in progress. do not account to load */
#define PF_NOFREEZE 0x00008000 /* this thread should not be frozen */
#define PF_FROZEN 0x00010000 /* frozen for system suspend */
#define PF_FSTRANS 0x00020000 /* inside a filesystem transaction */
#define PF_KSWAPD 0x00040000 /* I am kswapd */
#define PF_OOM_ORIGIN 0x00080000 /* Allocating much memory to others */
#define PF_LESS_THROTTLE 0x00100000 /* Throttle me less: I clean memory */
#define PF_KTHREAD 0x00200000 /* I am a kernel thread */
#define PF_RANDOMIZE 0x00400000 /* randomize virtual address space */
#define PF_SWAPWRITE 0x00800000 /* Allowed to write to swap */
#define PF_SPREAD_PAGE 0x01000000 /* Spread page cache over cpuset */
#define PF_SPREAD_SLAB 0x02000000 /* Spread some slab caches over cpuset */
#define PF_THREAD_BOUND 0x04000000 /* Thread bound to specific cpu */
#define PF_MCE_EARLY 0x08000000 /* Early kill for mce process policy */
#define PF_MEMPOLICY 0x10000000 /* Non-default NUMA mempolicy */
#define PF_MUTEX_TESTER 0x20000000 /* Thread belongs to the rt mutex tester */
#define PF_FREEZER_SKIP 0x40000000 /* Freezer should not count it as freezeable */
#define PF_FREEZER_NOSIG 0x80000000 /* Freezer won't send signals to it */这些宏定义都有详细的注释,不再详述。只提一点PF_RANDOMIZE标志,它表示内核要为栈和内存映射的起点随机选择位置,这样做可以防范攻击者的恶意攻击,增强安全性。
标识一个进程
一般来说,每个进程和自己的task_struct结构一一对应。因此可以用描述符地址来标识进程。另外还可以用PID来标识一个进程。PID在进程描述符的pid字段中,PID被顺序编号,新创建的进程PID通常为前一个进程的PID加1。但当PID达到上限后就循环使用闲置的小PID。缺省状态下PID最大值是32767(PID_MAX_DEFAULT-1),系统管理员可以往/proc/sys/kernel/pid_max文件中写入一个更小的值来减小PID上限。在64位系统中,上限可以扩大到4194303(0x3fffff)。
内核使用一个pidmap结构体来标识系统中PID的使用情况。由于32767个位需要4KB空间,因此在32位系统中这个位图正好占据一页。在64位体系结构中,当内核分配了更多PID时,需要为它增加更多页。这些页一直不会被释放。
=============== include/linux/pid_namespace.h 10 13 ==============
struct pidmap {
atomic_t nr_free;
void *page;
};Unix希望同一组中的线程有共同的PID,为此Linux引入线程组的表示。一个线程组的所有线程使用和该线程组的领头线程相同的PID,它被存入进程描述符的tgid字段。getpid()系统调用返回当前进程的tgid值,因此一个多线程应用的所有线程共享相同的PID。绝大多数进程都属于一个线程组,包含单一的成员;线程组的领头线程其tgid值与pid相同,因而getpid()系统调用对这类进程所起的作用和一般进程是一样的。
经常会需要从PID获取进程描述符,例如kill()这样的系统调用参数就是PID。下面我们来看如何高效地从PID导出描述符指针。
进程描述符处理
内核态的进程使用内核态栈。因为内核控制路径使用很少的栈,因此只需要几千字节就够用。历史上Linux内核将线程描述符和进程的内核态堆栈放在一起,一起占用8KB空间,为了效率起见,把这8KB空间占用两个连续的页框并让第一个页框的起始地址是2^13的倍数。后来随着申请两个连续的页框越来越困难,在2.6内核中它只占用一个页。在第二讲的伙伴系统介绍中描述过内核对这种空间申请的处理。
============== include/linux/sched.h 1965 1968 =============
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
============== arch/x86/include/asm/thread_info.h 26 44 =============
struct thread_info {
struct task_struct *task; /* main task structure */
struct exec_domain *exec_domain; /* execution domain */
__u32 flags; /* low level flags */
__u32 status; /* thread synchronous flags */
__u32 cpu; /* current CPU */
int preempt_count; /* 0 => preemptable,
<0 => BUG */
mm_segment_t addr_limit;
struct restart_block restart_block;
void __user *sysenter_return;
#ifdef CONFIG_X86_32
unsigned long previous_esp; /* ESP of the previous stack in
case of nested (IRQ) stacks
*/
__u8 supervisor_stack[0];
#endif
int uaccess_err;
};将thread_info与内核态堆栈之间紧密结合主要出于效率考虑,因为内核可以很容易地通过esp寄存器值屏蔽掉低12位得到thread_info的基地址。然后再通过task元素得到进程描述符指针,最后找到PID值。
创建进程
一般操作系统都有类似于create_task()之类的API来凭空创造出进程。Linux(及Unix)采用了不同的方法。
在Linux系统中,第一个进程是系统固有的,在内核代码中设计好的,此外其他进程和内核线程都是由该进程复制而来,都是原始进程的后代。这种做法分为两步。第一步类似于细胞分裂,从父进程中复制出一个子进程,与父进程有同样的代码、打开文件指针和数据等,但拥有自己的task_struct结构和系统空间堆栈,这一步有fork()和clone()两个系统调用。两者区别在于fork()是全部复制,而clone()则可以有选择地复制,未复制的数据结构通过指针复制让子进程共享。
后来又增加了一个vfork(),用于将task_struct和系统空间堆栈外的数据全部通过指针复制来共享,因此vfork()复制出来的是线程而非进程。vfork()主要是为了效率起见而设计的。
第二步是执行目标程序。为此Linux提供了execve()让一个进程执行以文件形式存在的可执行程序的镜像(如ELF文件)。
fork()、clone()和vfork()最终都是通过do_fork()函数处理。使用如下的参数:
clone_flags
stack_start
regs
stack_size
parent_tidptr,child_tidptr
do_fork()函数通过copy_process()来创建进程描述符及子进程执行所需要的其他所有内核数据结构。
撤销进程
进程的许多资源由内核维护,因此进程结束时,必须通知内核以便内核释放进程所拥有的内存、打开文件及其他资源如信号量等。
进程终止的一般方式是调用exit()函数,该函数释放C函数库所分配的资源,执行编程者所注册的每个函数,并结束从系统回收进程的那个系统调用。exit()函数可以由编程者显式插入,另外C编译程序总是把exit()函数插入到main()函数的最后一条语句之后。
有两种典型情况下,内核可以有选择地强迫整个线程组死掉:一种是当进程接收到一个不能处理或忽视的信号时,另一种是当内核正在代表进程运行时在内核态产生一个不可恢复的CPU异常时。
进程终止
有两个系统调用可以终止用户态应用:exit_group()和exit()。前者由内核函数do_group_exit()实现,终止整个线程组,是C库函数exit()应该调用的系统调用。后者由do_exit()实现,终止一个线程,而不管线程所属线程组中的所有其他进程,是pthread_exit()函数调用。
do_group_exit()
该函数杀死属于current线程组的所有进程。它的参数是进程终止代号,该代号可能是正常结束时的值,也可能是异常结束时内核提供的值。该函数执行以下操作:
1.检查退出进程的SIGNAL_GROUP_EXIT标志是否不为0,如果不为0,说明内核已经开始为线程组执行退出的过程。在这种情况下,把存放在current->signal->group_exit_code中的值当为退出码,然后跳转到第4步。
2.否则设置进程的SIGNAL_GROUP_EXIT标志并把终止代号存放到current->signal->group_exit_code字段。
3.调用zap_other_threads()函数杀死current线程组中的其他进程。为此,函数扫描与current->tgid对应的PIDTYPE_TGID类型的散列表中的每个PID表,向表中所有不同于current的进程发送SIGKILL信号,结果,所有这样的进程都将执行do_exit()函数,从而被杀死。
4.调用do_exit()函数,把进程的终止代号传递给它。正如下面将提到,do_exit()杀死进程而且不再返回。
do_exit()函数
所有进程的终止都是由do_exit()函数来处理的,这个函数从内核结构中删除对终止进程的大部分引用。do_exit()函数参数是进程的终止代号,执行如下操作:
1.把进程描述符的flag字段设置为PF_EXITING标志,以表示进程正被删除。
2.如果需要,通过函数del_timer_sync()从动态定时器队列中删除进程描述符。该函数在时间管理一讲中介绍。
3.分别调用exit_mm()、exit_sem()、__exit_files()、__exit_fs()、exit_namespace()和exit_thread()函数从进程描述符中分离出与分页、信号量、文件系统、打开文件描述符、命名空间以及I/O权限位图有关的数据结构。如果没有其他进程共享这些数据结构,那么这些函数还删除所有这些数据结构中。
4.如果实现了被杀死进程的执行域和可执行格式的内核函数包含在内核模块中,则函数递减它们的使用计数器。
5.把进程描述符的exit_code字段设置为进程的终止代号,这个值要么是_exit()或exit_group()系统调用参数,要么是由内核提供的一个错误代号。
6.调用exit_notify()函数执行下面的操作:
7.调用schedule()函数选择一个新的进程运行。调度程序忽略处于EXIT_ZOMBIE状态的进程,所以这种进程正好在schedule()中的宏switch_to被调用之后停止运行。如下所见,调用程序将检查被替换的僵死进程描述符的PF_DEAD标志并递减使用计数器,从而说明进程不再存活的事实。
进程删除
Unix允许进程查询内核以获得其父进程的PID,或者任何子进程的执行状态。例如进程可以创建一个子进程来执行特定任务,然后调用wait()这样的一些库函数检查子进程是否终止。如已终止,那么它的终止代号将告诉父进程这个任务是否已成功地完成。
进程切换
x86上的任务切换
在x86的系统设计时考虑到了任务(进程)的管理和调度,在硬件上提供了一种新的段,叫做任务状态段TSS,这在第一讲中提到过。一个TSS实际上是一个104字节的数据结构,用于记录一个任务的关键状态信息,包括:
任务切换前夕该任务各通用寄存器的内容。
任务切换前夕该任务各段寄存器(ES、CS、SS、DS、FS、GS)的内容。
任务切换前夕该任务EFLAGS寄存器的内容。
任务切换前夕该任务指令地址寄存器EIP的内容。
指向前一个任务的TSS结构的段选择码。当前任务执行IRET指令时,就返回到由这个段选择码所指的任务。
该任务的LDT段选择码,它指向任务的LDT。
控制寄存器CR3,它指向任务的页面目录。
三个堆栈指针,分别为当任务运行于0~2级时的堆栈指针,包括堆栈段寄存器SS0、SS1、SS2,以及ESP0、ESP1和ESP2的内容。在CPU中只有一个SS和一个ESP寄存器,但是CPU在进入亲的运行级别时会自动从当前任务的TSS中装入相应SS和ESP的内容,实现堆栈的切换。
一个用于程序跟踪的标志位T。当T标志为1时,CPU就会在切入该进程时产生一次debug异常,这样就可以在debug异常的服务程序中安排所需的操作,如加以记录、显示等。
在一个TSS段中,除了104字节外,还可以有一些附加的信息。其中包括表示I/O权限的位图。x86允许I/O指令在比0级低的状态下执行,也就是说可以将外设驱动实现于一个既非内核也非用户的空间中,这个位图就是用于这个目的。还包括中断重定向位图,用于vm86模式。
像其他的段一样,TSS也要在段描述表中有个表项。不过TSS的段描述符只能在GDT中,而不能放在任何一个LDT或IDT中。TSS描述符的结构与其他的段描述符基本一致,只多了一个B标志位,表示相应的TSS所代表的任务是否正在运行或者正被中断。见第一讲。
另外CPU还增设了一个任务寄存器TR,指向当前任务的TSS。当将一个段选择符装入TR中时,CPU就自动找到所选择的TSS描述符并装入非编程寄存器以加速今后的访问。
在下一讲中断中,会讲到“门”的概念,x86定义了一种任务门,当CPU因中断而穿过一个任务门时,就会把任务门中包含的段选择符自动装入TR,完成任务切换。CPU还可以通过JMP和CALL指令实现切换,当跳转目标指向GDT表中的一个TSS描述符时,就会引入一次任务切换。
Linux的进程切换
Intel这种设计看起来对于编程人员相当简洁周到,但事实上费时费力,因为一条CALL指令可能需要长达300多个CPU时钟,其中做了许多本可简化的步骤。为了提高效率和灵活性,在这里Linux又一次选择了无视Intel的意图,在内核中不使用任务门,也不允许用JMP或CALL来实施切换。但为了满足x86的要求,Linux在初始化阶段每个CPU设置一个TSS,设置TR指向这个TSS,以后也永远都只使用这一个TSS。
这样一来,TSS的绝大多数内容都失去了原来的意义。只有SS0和ESP0两项会被硬件自动使用,为此Linux在切换任务过程中只改变SS0和ESP0,这比彻底更改TR从而装入一个全新的TSS开销小得多。
内核对每个CPU定义了一个tss_struct的结构体,并做了初始化。注意这里的高速缓存的缓冲行对齐。
========== arch/x86/kernel/init_task.c 41 41 ===========
DEFINE_PER_CPU_SHARED_ALIGNED(struct tss_struct, init_tss) = INIT_TSS;
=========== arch/x86/include/asm/processor.h 253 272 ================
struct tss_struct {
/*
* The hardware state:
*/
struct x86_hw_tss x86_tss;
/*
* The extra 1 is there because the CPU will access an
* additional byte beyond the end of the IO permission
* bitmap. The extra byte must be all 1 bits, and must
* be within the limit.
*/
unsigned long io_bitmap[IO_BITMAP_LONGS + 1];
/*
* .. and then another 0x100 bytes for the emergency kernel stack:
*/
unsigned long stack[64];
} ____cacheline_aligned;
========== arch/x86/include/asm/processor.h 883 891 ===========
#define INIT_TSS { \
.x86_tss = { \
.sp0 = sizeof(init_stack) + (long)&init_stack, \
.ss0 = __KERNEL_DS, \
.ss1 = __KERNEL_CS, \
.io_bitmap_base = INVALID_IO_BITMAP_OFFSET, \
}, \
.io_bitmap = { [0 ... IO_BITMAP_LONGS] = ~0 }, \
}这里把第一个进程的SS0设置成__KERNEL_DS,把ESP0设置为指向init_stack的顶端。
参考资料
本文资料来源以下几本书或网站。
《Linux内核源代码情景分析》第3章
《深入理解Linux内核》第3、4章















 357
357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









