







序
回忆前两讲,内核获取动态内存有三种方法:用__get_free_pages()从分区页框分配器获得页框;用kmem_cache_alloc()或kmalloc()使用slab分配器为专用或通用对象分配块;用vmalloc()或vmalloc_32()获得一块非连续的内存区。
不论是否阻塞,如果所请求内存区得到满足,当函数成功返回时候,它们函数返回分配空间的起始线性地址或一个页描述符的线性地址。对应的物理内存已经分配完毕。这些操作的过程相对简单易懂。
但是当用户进程请求分配内存时,内核会采用不同的方法。原因有二:
进程的请求被认为是不急迫的,例如进程调用malloc()获得内存时候,并不意味着进程很快访问所获得的内存。因此,内核总是尽量推迟给用户态进程分配动态内存。
由于用户进程不可信任,因此内核必须能随时准备捕获用户态进程引起的所有寻址错误。
因此,内核使用一种新的资源成功实现了对进程的动态内存的推迟分配。当用户态进程请求动态内存时,并没有获得请求的页框,而仅仅获得对一个新的线性地址区的使用权,这个线性地址区就成为进程地址空间的一部分。这个区间叫做“线性区”。线性区是由起始地址、长度和一些访问权限来定义,起始地址和长度都是4096的倍数。
本讲讲以线性区为基础讲述与进程地址空间相关的内容。首先介绍进程地址空间的概念,然后介绍用于描述进程地址空间的内存描述符,以及其中最重要的线性区的概念。内核对进程线性区与物理地址的映射处理在缺页异常处理程序中完成,因此之后插入对的详细解读。最后是进程地址空间的创建和删除过程,以及特殊线性区——堆的管理。
进程的地址空间
进程的地址空间由允许进程使用的全部线性地址组成。每个进程所看到的线性地址集合不同,一个进程的地址和另一个进程的地址间没有什么关系。内核可以动态修改进程的地址空间。
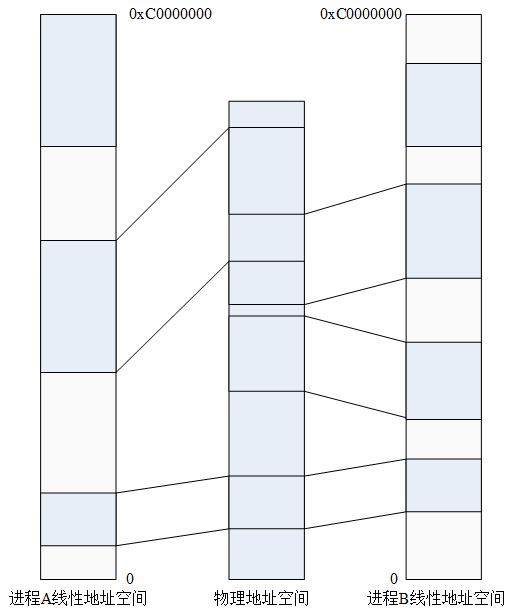
如下几种情况下进程可以获得新的线性区:
1.当用户新建一个进程时候。
2.正在运行的进程装入一个完全不同的程序的时候(exec函数)。
3.正在运行的进程对一个或部分文件执行内存映射时候。
4.进程项用户态堆栈增加数据直至堆栈用完的时候。
5.进程创建一个IPC共享线性区与其他合作进程共享数据的时候。
6.进程通过malloc()这样的函数扩展堆。
在第一讲中提到过Linux进程运行后的虚拟空间分配。从逻辑上,Unix程序的线性地址空间传统上划分为几个称为段的区间。
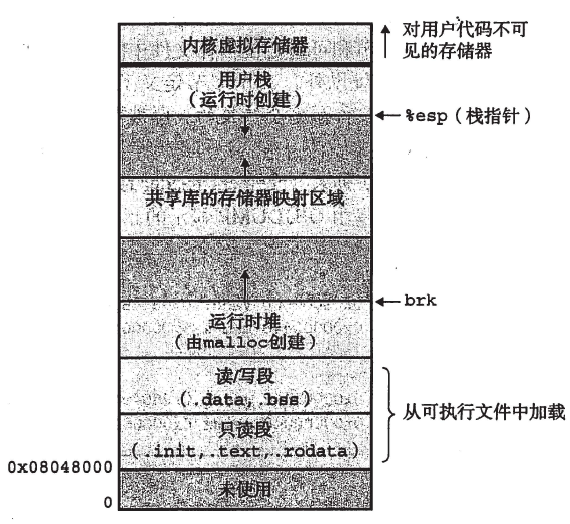
正文段:包含程序的可执行代码。
已初始化数据段:包含已初始化的数据,也就是初值存放在可执行文件中的静态变量和全局变量。
未初始化数据段:包含未初始化数据,历史上这个段被称为bss段。
堆栈段:包含程序的堆栈,堆栈中有返回地址、参数和被执行函数的局部变量。
从2.6.9开始,Linux内核引入了灵活线性区布局的功能,与经典布局相比,两者只在文件内存映射与匿名映射时线性区的位置上有区别,如下图所示。在典型布局下,这些区域从整个用户态地址空间的1/3(即0x40000000)开始,新的区域向上增长。在灵活布局中,这些区域紧接用户态堆栈尾,新区域向下增长。
灵活布局的好处是使得堆空间和其他线性区可以灵活扩展。

在/proc目录的某指定进程的maps文件中,可以看到进程执行时的线性区情况。
内存描述符
在缺页异常处理程序一节将看到,确定一个进程当前所拥有的地址空间是内核的基本任务。因此需要用一种方式描述进程的地址空间。内核使用内存描述符来描述。
内存描述符结构类型为mm_struct,下一讲讲到进程时将会看到,进程描述符的mm字段就指向这个结构。
==================== include/linux/mm_types.h 222 315 ====================
struct mm_struct {
struct vm_area_struct * mmap; /* list of VMAs */
struct rb_root mm_rb;
struct vm_area_struct * mmap_cache; /* last find_vma result */
#ifdef CONFIG_MMU
unsigned long (*get_unmapped_area) (struct file *filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags);
void (*unmap_area) (struct mm_struct *mm, unsigned long addr);
#endif
unsigned long mmap_base; /* base of mmap area */
unsigned long task_size; /* size of task vm space */
unsigned long cached_hole_size; /* if non-zero, the largest hole below free_area_cache */
unsigned long free_area_cache; /* first hole of size cached_hole_size or larger */
pgd_t * pgd;
atomic_t mm_users; /* How many users with user space? */
atomic_t mm_count; /* How many references to "struct mm_struct" (users count as 1) */
int map_count; /* number of VMAs */
struct rw_semaphore mmap_sem;
spinlock_t page_table_lock; /* Protects page tables and some counters */
struct list_head mmlist; /* List of maybe swapped mm's. These are globally strung
* together off init_mm.mmlist, and are protected
* by mmlist_lock
*/
unsigned long hiwater_rss; /* High-watermark of RSS usage */
unsigned long hiwater_vm; /* High-water virtual memory usage */
unsigned long total_vm, locked_vm, shared_vm, exec_vm;
unsigned long stack_vm, reserved_vm, def_flags, nr_ptes;
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
unsigned long saved_auxv[AT_VECTOR_SIZE]; /* for /proc/PID/auxv */
/*
* Special counters, in some configurations protected by the
* page_table_lock, in other configurations by being atomic.
*/
struct mm_rss_stat rss_stat;
struct linux_binfmt *binfmt;
cpumask_t cpu_vm_mask;
/* Architecture-specific MM context */
mm_context_t context;
/* Swap token stuff */
/*
* Last value of global fault stamp as seen by this process.
* In other words, this value gives an indication of how long
* it has been since this task got the token.
* Look at mm/thrash.c
*/
unsigned int faultstamp;
unsigned int token_priority;
unsigned int last_interval;
unsigned long flags; /* Must use atomic bitops to access the bits */
struct core_state *core_state; /* coredumping support */
#ifdef CONFIG_AIO
spinlock_t ioctx_lock;
struct hlist_head ioctx_list;
#endif
#ifdef CONFIG_MM_OWNER
/*
* "owner" points to a task that is regarded as the canonical
* user/owner of this mm. All of the following must be true in
* order for it to be changed:
*
* current == mm->owner
* current->mm != mm
* new_owner->mm == mm
* new_owner->alloc_lock is held
*/
struct task_struct __rcu *owner;
#endif
#ifdef CONFIG_PROC_FS
/* store ref to file /proc/<pid>/exe symlink points to */
struct file *exe_file;
unsigned long num_exe_file_vmas;
#endif
#ifdef CONFIG_MMU_NOTIFIER
struct mmu_notifier_mm *mmu_notifier_mm;
#endif
/* How many tasks sharing this mm are OOM_DISABLE */
atomic_t oom_disable_count;
};所有的内存描述符存放在一个双向链表中,每个描述符在mmlist字段存放链表相邻元素的地址。链表的第一个元素是进程0使用的内存描述符init_mm的mm_list字段,mmlist_lock自旋锁保护多处理器系统对链表的同时访问。
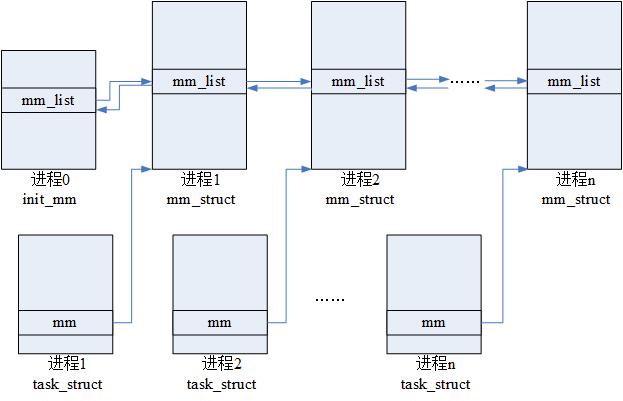
mm_users和mm_count字段不同。
start_code、end_code表示程序的源代码所在线性区的起始和终止线性地址。
start_data、end_data表示程序的初始化数据在线性区的起始和终止线性地址,这两个字段指定的线性区大体上与数据段对应。
start_brk、brk存放堆的起始和终止地址。
start_stack是正好在main()的返回地址之上的地址。
arg_start、arg_end是命令行参数所在的堆栈部分的起始地址和终止地址。
env_start、env_end环境变量所在的堆栈部分的起始地址和终止地址。
get_unmapped_area函数指针在初始化时可能被指定两个可能值。在线性区的处理一节中讨论。
mmap、mm_rb、mmlist、mmap_cache字段在下一小节讨论。
内核线程的内存描述符
内核线程永远不会访问低于TASK_SIZE(在x86上等于0xC0000000)的地址,他们不使用线性区,因此内存描述符的很多字段对于内核线程没有意义。
在第一讲中讲过,所有用户进程和内核线程的最高1GB线性地址空间的页表项都是相同的,为了避免无用的TLB和高速缓存刷新,内核线程使用了一组最近运行的普通进程的页表。因此在每个进程描述符中包含了两个内存描述符指针:mm和active_mm。
mm字段指向进程所拥有的内存描述符,而active_mm字段指向进程运行时所使用的内存描述符。对于普通进程而言,这两个字段存放相同的指针。但是内核线程不拥有任何内存描述符,因此mm总是为NULL,当内核线程运行时,它的active_mm字段被初始化为前一个运行进程的active_mm值。在下一讲进程中的schedule函数中讨论。
另一方面,一旦内核态的一个进程修改高端线性地址的页表项,那么就系统中所有进程页表集合中相应表项都需要更新。这将遍历所有进程的页表集合,是一个非常费力的操作,因此,Linux采用一种延迟方式:当一个高端地址必须重新映射时,内核就更新根目录在swapper_pg_dir主内核页全局目录中的常规页表集合。这个页全局目录由init_mm变量的pgd字段所指向。
在随后的“处理非连续内存区访问”一节,我们将描述缺页处理程序如何在非必要时维护存放在常规页表中的扩展信息。
线性区
Linux通过vm_area_struct结构体实现线性区。
==================== include/linux/mm_types.h 130 186 ====================
130 struct vm_area_struct {
131 struct mm_struct * vm_mm; /* The address space we belong to. */
132 unsigned long vm_start; /* Our start address within vm_mm. */
133 unsigned long vm_end; /* The first byte after our end address
134 within vm_mm. */
135
136 /* linked list of VM areas per task, sorted by address */
137 struct vm_area_struct *vm_next, *vm_prev;
138
139 pgprot_t vm_page_prot; /* Access permissions of this VMA. */
140 unsigned long vm_flags; /* Flags, see mm.h. */
141
142 struct rb_node vm_rb;
143
144 /*
145 * For areas with an address space and backing store,
146 * linkage into the address_space->i_mmap prio tree, or
147 * linkage to the list of like vmas hanging off its node, or
148 * linkage of vma in the address_space->i_mmap_nonlinear list.
149 */
150 union {
151 struct {
152 struct list_head list;
153 void *parent; /* aligns with prio_tree_node parent */
154 struct vm_area_struct *head;
155 } vm_set;
156
157 struct raw_prio_tree_node prio_tree_node;
158 } shared;
159
160 /*
161 * A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
162 * list, after a COW of one of the file pages. A MAP_SHARED vma
163 * can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
164 * or brk vma (with NULL file) can only be in an anon_vma list.
165 */
166 struct list_head anon_vma_chain; /* Serialized by mmap_sem &
167 * page_table_lock */
168 struct anon_vma *anon_vma; /* Serialized by page_table_lock */
169
170 /* Function pointers to deal with this struct. */
171 const struct vm_operations_struct *vm_ops;
172
173 /* Information about our backing store: */
174 unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
175 units, *not* PAGE_CACHE_SIZE */
176 struct file * vm_file; /* File we map to (can be NULL). */
177 void * vm_private_data; /* was vm_pte (shared mem) */
178 unsigned long vm_truncate_count;/* truncate_count or restart_addr */
179
180 #ifndef CONFIG_MMU
181 struct vm_region *vm_region; /* NOMMU mapping region */
182 #endif
183 #ifdef CONFIG_NUMA
184 struct mempolicy *vm_policy; /* NUMA policy for the VMA */
185 #endif
186 };每个线性区描述符表示一个线性地址区间。其中vm_start字段包含区间的第一个线性地址,vm_end字段是结束地址+1。两者相减就是线性区的长度。vm_mm字段指向进程的mm_struct内存描述符。
vm_ops是一些对线性区操作的方法。可能的操作方法如下所示。
==================== include/linux/mm.h 188 232 ====================
188 /*
189 * These are the virtual MM functions - opening of an area, closing and
190 * unmapping it (needed to keep files on disk up-to-date etc), pointer
191 * to the functions called when a no-page or a wp-page exception occurs.
192 */
193 struct vm_operations_struct {
194 void (*open)(struct vm_area_struct * area);
195 void (*close)(struct vm_area_struct * area);
196 int (*fault)(struct vm_area_struct *vma, struct vm_fault *vmf);
197
198 /* notification that a previously read-only page is about to become
199 * writable, if an error is returned it will cause a SIGBUS */
200 int (*page_mkwrite)(struct vm_area_struct *vma, struct vm_fault *vmf);
201
202 /* called by access_process_vm when get_user_pages() fails, typically
203 * for use by special VMAs that can switch between memory and hardware
204 */
205 int (*access)(struct vm_area_struct *vma, unsigned long addr,
206 void *buf, int len, int write);
207 #ifdef CONFIG_NUMA
215 int (*set_policy)(struct vm_area_struct *vma, struct mempolicy *new);
216
227 struct mempolicy *(*get_policy)(struct vm_area_struct *vma,
228 unsigned long addr);
229 int (*migrate)(struct vm_area_struct *vma, const nodemask_t *from,
230 const nodemask_t *to, unsigned long flags);
231 #endif
232 };进程的线性区间从来不重叠,并且在权限匹配时,内核会将新分配的线性区与紧邻的现有线性区进行合并。
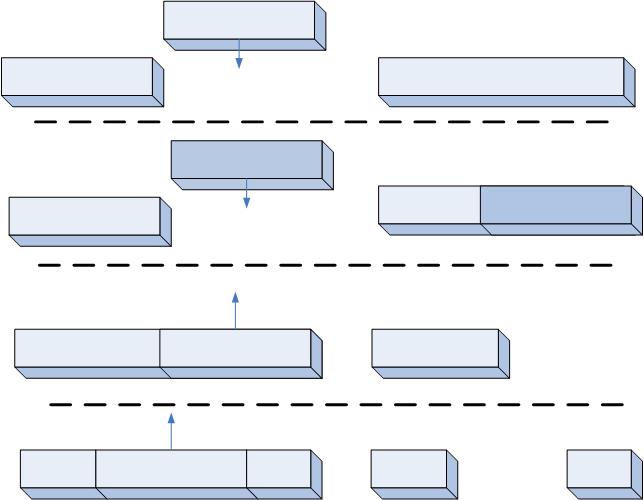
图示了四种增加或删除一个线性区时内核的操作。
当新增的线性区与原有线性区地址连续且权限相同时候,两个线性区被合并为同一个。
当新增的线性区与原有线性区地址连续但权限不同时候,两个线性区仍为两个。
当删除的线性区位于原有线性区一端时,现有线性区区域被缩小。
当删除的线性区位于原有线性区中间时,将创建两个较小的线性区。
这些操作的具体实现在后面线性区的处理小节中介绍。这里也可以看出,删除一个线性区有可能失败,因为有可能需要额外的线性区描述符。
线性区数据结构
进程所拥有的线性区是通过一个简单的顺序链表链接在一起,按照升序排列。每个vm_area_struct元素的vm_next字段指向链表的下一个元素,内核通过内存描述符的mmap字段索引到第一个线性区描述符。
内存描述符的map_count字段是进程拥有的线性区数目,默认最多为65536个,但可以通过写/proc/sys/vm/max_map_count文件来修改这个限定值。
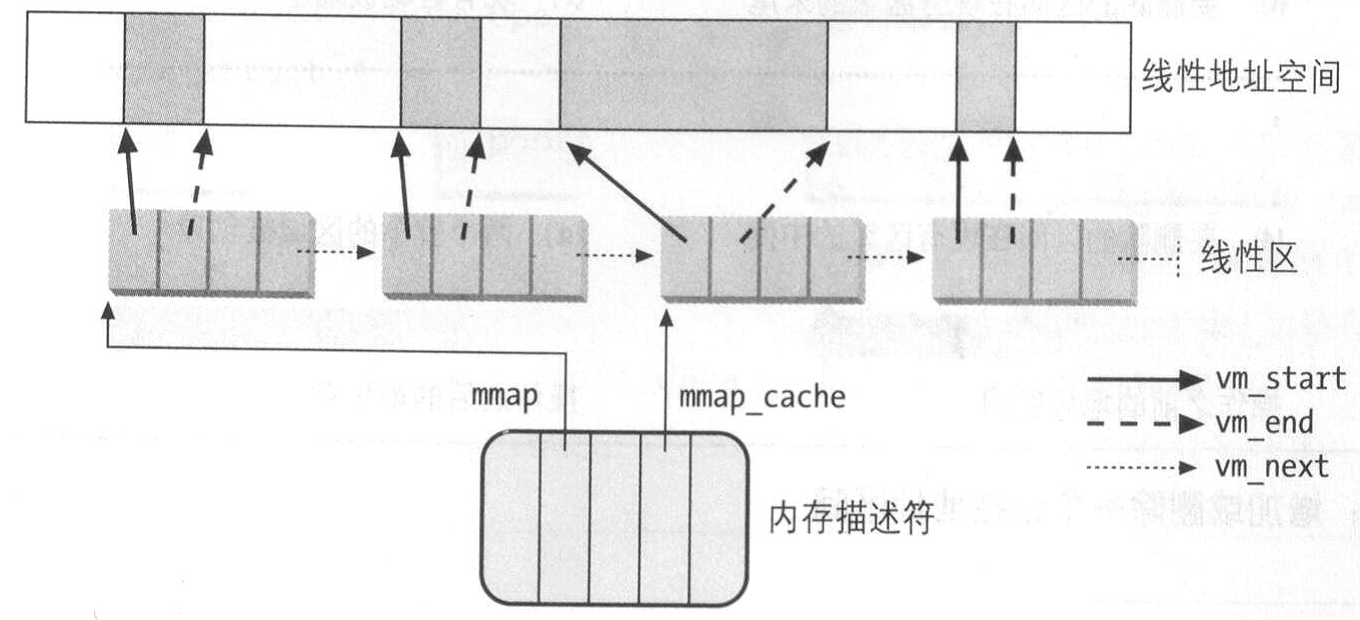
内核经常需要查找包含指定线性地址的线性区,例如对一个线性地址的访问,内核需要判断是否合法,这时候需要查找该地址是否包含在某个线性区内,且访问权限如何。由于链表是顺序的,查找复杂度是O(n)。但是当进程内的线性区很多时,这种查找、插入、删除将花费很长时间。例如面向对象的数据库应用,其线性区有成百上千个,这时候与内存相关的系统调用将变得异常低效。
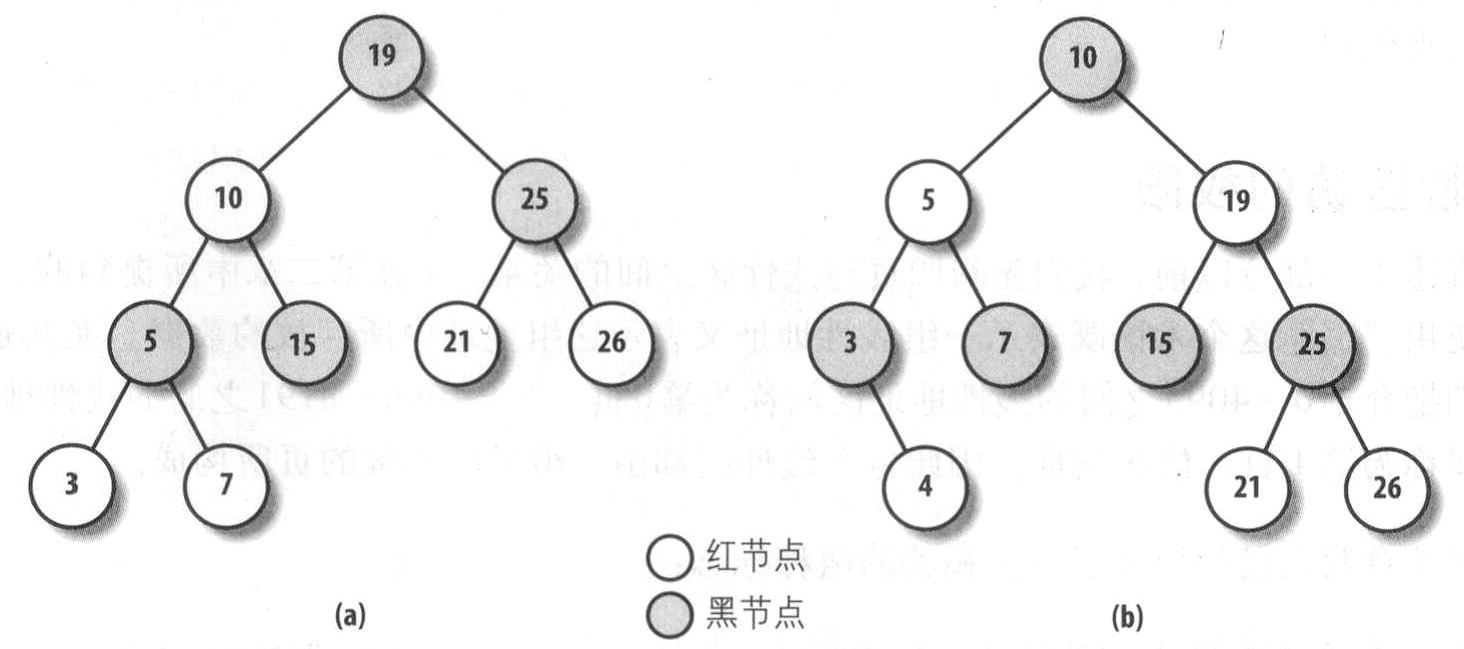
为此,Linux2.6把内存描述符放在一个红黑树的数据结构中。红黑树的首部由内存描述符的mm_rb指向。在红黑树中,每个节点通常有两个孩子:左孩子与右孩子。树中元素被排序。对于每个节点N,N的左树上所有元素都在N之前,N的右树上所有元素都在N之后。此外红黑树还必须满足下列4条规则:
1.每个节点必须或红或黑。
2.树根必须为黑。
3.红节点的孩子必须为黑。
4.从一个节点到后代叶子节点的每个路径都包含相同数量的黑节点。当统计黑节点时,空指针也算黑节点。
满足这样特性的红黑树高度与节点数为对数关系:2*log(n+1)。这样的数据结构使得查找、插入、删除都异常高效,复杂度变为O(logn)。
这样Linux使用链表和红黑树两种数据结构来保存进程的线性区。当插入或删除一个线性区描述符时,内核通过红黑树搜索前后元素,并用搜索结果快速更新链表而不用扫描链表。
一般来说,红黑树用来确定含有指定地址的线性区,而链表通常在扫描整个线性区集合时来使用。
线性区访问权限
在第一讲内存寻址时讲过,Linux主要采用页式内存管理,每个页表项中有Read/Write、Present或User/Supervisor等标志,每个页描述符的flags字段也有不同的标志。第一种标志被80x86使用,第二种标志被Linux使用。现在又增加了第三种标志,即线性区的相关标志,在vm_area_struct的vm_flags字段中。
==================== include/linux/mm.h 66 136 ====================
66 /*
67 * vm_flags in vm_area_struct, see mm_types.h.
68 */
69 #define VM_READ 0x00000001 /* currently active flags */
70 #define VM_WRITE 0x00000002 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1763
1763











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









