







原论文:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
作者:Sergey Ioffe,Christian Szegedy
时间:Feb 2015
本文的大部分观点来自于这篇论文,并且加入了一些自己的理解。该博客纯属读书笔记,欢迎吐槽。
mini-batch
使用mini-batch作为训练单位,取代原来的以单个样本作为训练单位的训练方式。文章指出这样做有两个好处。第一,以单个样本作为训练单位,那么损失函数计算得到的误差是不具有代表性的,个体不能代表整体嘛,所以用它计算得到的梯度the gradient of the loss function也是不具有代表性的,很可能通过两个样本计算得到的梯度是差别很大的,这样就会导致参数调整不稳定。而以mini-batch作为训练单位,损失函数计算公式和梯度计算公式分别如下所示。
图1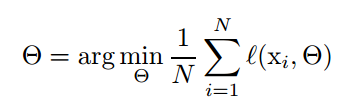
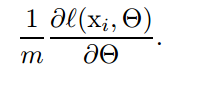
可以看到只是简单的求了一下mini-batch中包含的N个样本的损失函数的均值,但是这样得到的数据就很具有代表性了,并且随着包含样本数量的增加,这种效果更加明显 quality improves as the batch size increases。第二点也很重要,computation over a batch can be much more efficient than m computations for individual examples,计算效率提高了啊,随着DNN结构变得越来越复杂,这个优点更加明显。
Internal covariate Shift
文章提到一个词Internal covariate Shift,它是由covariate Shift(变量偏移?)扩展来,我们知道,在机器学习中,合适的样本数据是很重要的,样本分布distributions of samples是否全面直接影响到训练出来的模型的泛化能力,为了解决这个问题,我们通常的做法是尽量保证训练样本与测试样本的分布保持一致。而文章提到Internal covariate Shift,意思是现在DNN里面存在很多的sub-network,因为DNN中高层神经元的输入是底层神经元的输出,这样就存在一个问题了:我们可以保证训练样本输入与测试样本的分布一致,但是训练样本输入通过神经元的传递成为它下一层神经元的输入。。。以此类推,这样的话我们就不能保证高层神经元的输入的分布了啊。也许有人会问我们为什么要保证sub-network的输入分布?第一,调整过的参数更加稳定,也可以使训练时间有效减少,因为参数不需要去重新适应新的输入分布;第二,避免非线性过饱和,比如我们使用sigmod函数作为激活函数,那么我们会发现越到后面,数据很可能会越往sigmod函数的两边靠,进入the saturated regime of the nonlinearity,导致梯度变化很慢,参数很难收敛,所以我们可以发现,在DNN中,靠近输出的网络层的神经元参数调整得很好,但是越往后因为梯度变化越小导致参数基本没有变化。当然我们可以使用ReLu函数代替,但是效果不明显。
这里作者讲了两种行不通的方法为后面提出的新方法做了铺垫。第一种方法如图3所示。

但是发现最后对b的更新不能使损失函数的值下降,因为每一次参数更新完后随着而来的是输入的再次更新。
第二种方法是将输入向量看出一个整体去进行白化,但是这样需要计算协方差矩阵,如果样本很大,计算规模会爆炸。
所以最后为了解决这个Internal covariate Shift,文章提出了一种新算法Batch Normalization,下面就简单讲讲它的原理。
Batch Normalization
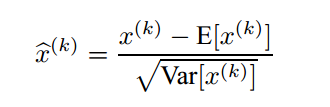 图4
图4
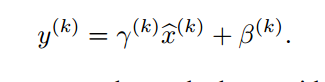 图5
图5
加了两个参数,gamma和beta,让输入数据可以缩放和偏移。作者没有固定这两个参数,而是让它们在训练中自动学习,这在很大程度上增加了神经网络的表现能力。
但是normalization的对象也就是公式中的x应该是什么呢?我们看一看常用的sigmod函数z = g(Wu + b),其中u代表上一个神经元的输出,我们可以直接对u进行normalization操作,但是作者说这样不好,因为在训练过程中u的分布是不稳定;所以我们选择对Wu + b进行normalization操作,因为它在训练过程中可以保持对称,非稀疏的分布。但是这样的话就会出现Internal covariate Shift提到的第一种方法中出现的问题,就是在训练过程中我们更新了b的大小,但是经过下一次的normalization操作,b并不能对新的x参数影响,这导致了b的值会不断增大但是损失函数的值却不变。作者采用的解决办法是把b归到beta里,这时候就变成了z = g(BN(Wu))了。
在训练DNN的时候我们以mini-batch为单位,去计算样本的均值和方差然后以它们为基础将输入变量进行转换,这是没问题的。但是,当把训练好的DNN用于分类或者其它任务的时候,问题就来了:应该以哪一个mini-batch的均值和方差对输入的变量进行转换呢?随便选一个肯定不不可能了,取当前需要分类的多个样本去计算新的均值和方差更加不靠谱,所以作者提出,在训练的时候根据每一个mini-batch的均值和方差,来求取所以用于训练的样本的均值和方差(其中方差使用的是无偏估计),这样我们计算得到均值和方差就很有代表性了。
在对卷积神经网络进行Batch Normalization时,mini-batch不再只是单纯的由m个一维变量构成了。为了使特征图片中不同位置的元素经过Batch Normalization后仍然能够保持差异,这时候mini-batch的大小变为m*p*q,其中p*q是特征图片的大小。每一种特征图片中的元素都共有唯一的gamma和beta参数。
总的来说,Batch Normalization的好处主要有以下几点:
1 减少Dropout的使用,因为Dropout一般是为了防止过拟合现象,但是通过BN,这种现象已经可以有效的避免了。
2 可以使用更高的学习率
3 可以使深层的参数得到更好的优化,因为使用BN后,误差梯度不能随着传递的深入而显著减小,使得深层的参数也得到很好的训练。
4 最重要的一点是训练效率提高了!















 3206
3206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









