







原论文:Going deeper with convolutions
作者:Christian Szegedy,Wei Liu,Yangqing Jia,Pierre Sermanet,Scott Reed,Dragomir Anguelov,Dumitru Erhan,Vincent Vanhoucke,Andrew Rabinovich
时间:February 2012
本文的大部分观点来自于这篇论文,并且加入了一些自己的理解。该博客纯属读书笔记。
Pure Inception blocks
基于对TensorFlow系统的使用,使得Inception architecture不需要过多的考虑分布式训练带来的诸多问题,不需要考虑模型的分割。这样我们的模型的结构会更简洁,计算量也更少。
Scaling of the Residuals
文章提到当卷积核的数量超过1000个时,残差学习会变得不稳定,当随着迭代次数增加,参数基本为0,也就是说残差学习最终得到的只是一个恒等映射。而通过缩放残差因子x可以使得训练更加稳定。文章还否定了ResNet的two-phase 训练方法,先使用较低的学习率训练进行预热,然后使用高学习率。但是这种做法在卷积核数量很多的情况下也行不通。所以文章最终只采用缩放残差因子的方法进行训练。
实验结果如图1所示。总体效果差强人意,毕竟残差学习是微软的成果,而且文章只是把效果提升归结于模型规模的提升。
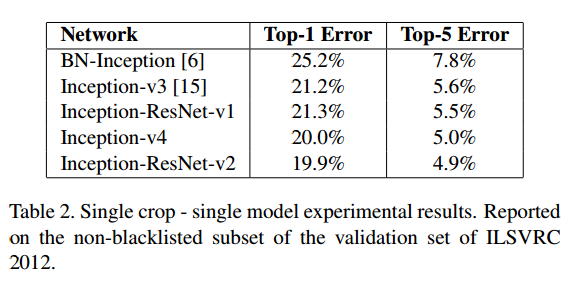 图1
图1















 564
564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









