










使用机器学习方法 做文档的自动分类
套路:
1.根据每个文件 生成该文件的一个特征
2.根据特征 选择 分类器 进行文本分类
3.(可选)根据 2 步结果,调整参数/特征等
示例:
数据:搜狗文本分类语料库 精简版
分类器:朴素贝叶斯
编程语言:Python+nltk自然语言处理库+jieba分词库
__author__ = 'LiFeiteng'
# -*- coding: utf-8 -*-
import os
import jieba
import nltk
## 由搜狗语料库 生成数据
folder_path = 'C:\LIFEITENG\SogouC.reduced\\Reduced'
#folder_path = 'C:\LIFEITENG\SogouC.mini\Sample'
folder_list = os.listdir(folder_path)
class_list = [] ##由于乱码等问题 仅以数字[0,1,...]来代表文件分类
nClass = 0
N = 100 #每类文件 最多取 100 个样本 70%train 30%test
train_set = []
test_set = []
all_words = {}
import time
process_times = [] ## 统计处理每个文件的时间
for i in range(len(folder_list)):
new_folder_path = folder_path + '\\' + folder_list[i]
files = os.listdir(new_folder_path)
class_list.append(nClass)
nClass += 1
j = 0
nFile = min([len(files), N])
for file in files:
if j > N:
break
starttime = time.clock()
fobj = open(new_folder_path+'\\'+file, 'r')
raw = fobj.read()
word_cut = jieba.cut(raw, cut_all=False)
word_list = list(word_cut)
for word in word_list:
if word in all_words.keys():
all_words[word] += 1
else:
all_words[word] = 0
if j > 0.3 * nFile:
train_set.append((word_list, class_list[i]))
else:
test_set.append((word_list, class_list[i]))
j += 1
endtime = time.clock()
process_times.append(endtime-starttime)
print "Folder ",i,"-file-",j, "all_words length = ", len(all_words.keys()),\
"process time:",(endtime-starttime)
print len(all_words)
## 根据word的词频排序
all_words_list = sorted(all_words.items(), key=lambda e:e[1], reverse=True)
word_features = []
## 由于乱码的问题,没有正确使用 stopwords;简单去掉 前100个高频项
## word_features 是选用的 word-词典
for t in range(100, 1100, 1):
word_features.append(all_words_list[t][0])
def document_features(document):
document_words = set(document)
features = {}
for word in word_features: ## 根据词典生成 每个document的feature True or False
features['contains(%s)' % word] = (word in document_words)
return features
## 根据每个document 分词生成的 word_list 生成 feature
train_data = [(document_features(d), c) for (d,c) in train_set]
test_data = [(document_features(d), c) for (d,c) in test_set]
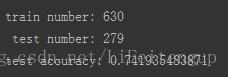
print "train number:",len(train_data),"\n test number:",len(test_data)
## 朴素贝叶斯分类器
classifier = nltk.NaiveBayesClassifier.train(train_data)
print "test accuracy:",nltk.classify.accuracy(classifier, test_data)
## 处理每个文件所用的时间 可见到后面 处理单个文件的时间显著增长
## 原因 已查明
import pylab
pylab.plot(range(len(process_times)), process_times, 'b.')
pylab.show()
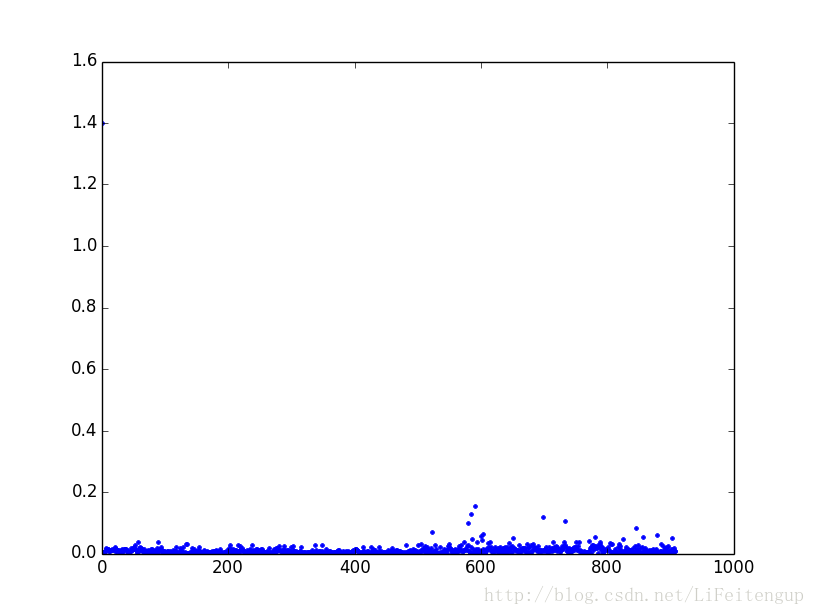
处理每个文件所用时间:
===============================
朴素贝叶斯:From 《数据挖掘概念与技术》

1.中文乱码问题,由于这个问题,在stopwords上简单去掉 前100个高频项 数据清洗不足
2.字典的选择上——简单以统计 所有文件词频,选用101-1100 1000个词作字典
我觉得 字典完全可以从 数据上 学习(要比上面方法高明些),就像在图像处理中 稀疏模型 学习字典(KSVD)一样
自然语言处理/文本处理 中也应该存在这样的方法
3.文件的特征 是[0,0,1,0,0,1,...]并不是统计每个文件的词频,
这跟选择的分类器相关,如果选择svm等 就要对文件 生成词频特征
4.到后面(见上图),单个文件处理时间显著增长,原因待查明——已查明 if word in all_words.keys(): 改为all_words.has_key(word)
以 机器学习 的小无相功 打了一套 自然语言处理/文本挖掘 的招数
难免有些生硬 望专家指点














 211
211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









